 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Frege to chatGPT: Compositionality in language, cognition, and deep neural networks
May 24, 2024



Compositionality has long been considered a key explanatory property underlying human intelligence: arbitrary concepts can be composed into novel complex combinations, permitting the acquisition of an open ended, potentially infinite expressive capacity from finite learning experiences. Influential arguments have held that neural networks fail to explain this aspect of behavior, leading many to dismiss them as viable models of human cognition. Over the last decade, however, modern deep neural networks (DNNs), which share the same fundamental design principles as their predecessors, have come to dominate artificial intelligence, exhibiting the most advanced cognitive behaviors ever demonstrated in machines. In particular, large language models (LLMs), DNNs trained to predict the next word on a large corpus of text, have proven capable of sophisticated behaviors such as writing syntactically complex sentences without grammatical errors, producing cogent chains of reasoning, and even writing original computer programs -- all behaviors thought to require compositional processing. In this chapter, we survey recent empirical work from machine learning for a broad audience in philosophy, cognitive science, and neuroscience, situating recent breakthroughs within the broader context of philosophical arguments about compositionality. In particular, our review emphasizes two approaches to endowing neural networks with compositional generalization capabilities: (1) architectural inductive biases, and (2) metalearning, or learning to learn. We also present findings suggesting that LLM pretraining can be understood as a kind of metalearning, and can thereby equip DNNs with compositional generalization abilities in a similar way. We conclude by discussing the implications that these findings may have for the study of compositionality in human cognition and by suggesting avenues for future research.
Multiple Realizability and the Rise of Deep Learning
May 21, 2024The multiple realizability thesis holds that psychological states may be implemented in a diversity of physical systems. The deep learning revolution seems to be bringing this possibility to life, offering the most plausible examples of man-made realizations of sophisticated cognitive functions to date. This paper explores the implications of deep learning models for the multiple realizability thesis. Among other things, it challenges the widely held view that multiple realizability entails that the study of the mind can and must be pursued independently of the study of its implementation in the brain or in artificial analogues. Although its central contribution is philosophical, the paper has substantial methodological upshots for contemporary cognitive science, suggesting that deep neural networks may play a crucial role in formulating and evaluating hypotheses about cognition, even if they are interpreted as implementation-level models. In the age of deep learning, multiple realizability possesses a renewed significance.
Human Curriculum Effects Emerge with In-Context Learning in Neural Networks
Feb 13, 2024Human learning is sensitive to rule-like structure and the curriculum of examples used for training. In tasks governed by succinct rules, learning is more robust when related examples are blocked across trials, but in the absence of such rules, interleaving is more effective. To date, no neural model has simultaneously captured these seemingly contradictory effects. Here we show that this same tradeoff spontaneously emerges with "in-context learning" (ICL) both in neural networks trained with metalearning and in large language models (LLMs). ICL is the ability to learn new tasks "in context" - without weight changes - via an inner-loop algorithm implemented in activation dynamics. Experiments with pretrained LLMs and metalearning transformers show that ICL exhibits the blocking advantage demonstrated in humans on a task involving rule-like structure, and conversely, that concurrent in-weight learning reproduces the interleaving advantage observed in humans on tasks lacking such structure.
The Relational Bottleneck as an Inductive Bias for Efficient Abstraction
Sep 12, 2023

A central challenge for cognitive science is to explain how abstract concepts are acquired from limited experience. This effort has often been framed in terms of a dichotomy between empiricist and nativist approaches, most recently embodied by debates concerning deep neural networks and symbolic cognitive models. Here, we highlight a recently emerging line of work that suggests a novel reconciliation of these approaches, by exploiting an inductive bias that we term the relational bottleneck. We review a family of models that employ this approach to induce abstractions in a data-efficient manner, emphasizing their potential as candidate models for the acquisition of abstract concepts in the human mind and brain.
A Neural Network Model of Continual Learning with Cognitive Control
Feb 09, 2022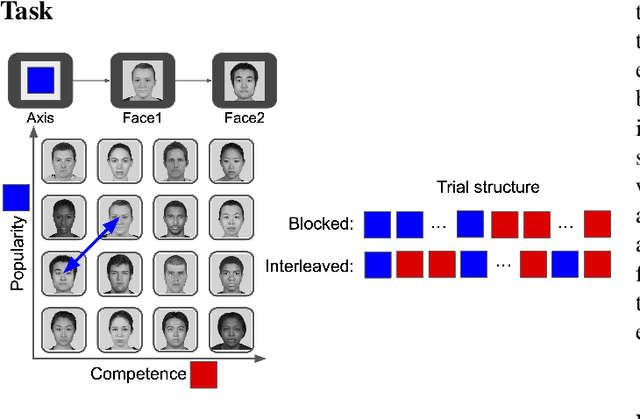
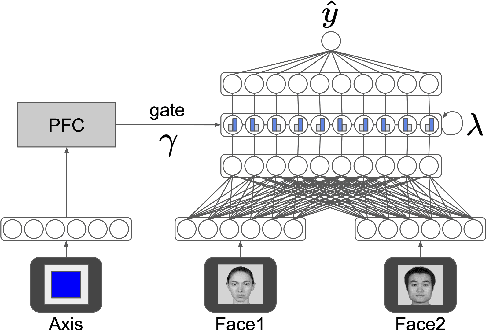
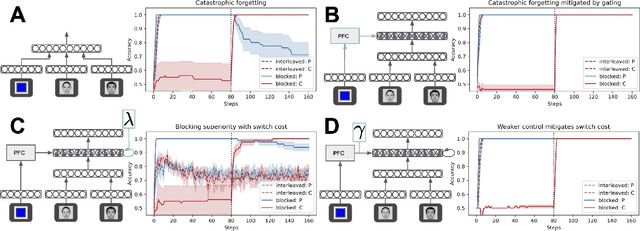
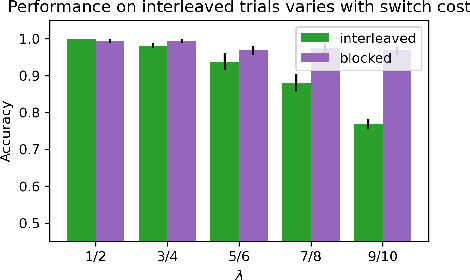
Neural networks struggle in continual learning settings from catastrophic forgetting: when trials are blocked, new learning can overwrite the learning from previous blocks. Humans learn effectively in these settings, in some cases even showing an advantage of blocking, suggesting the brain contains mechanisms to overcome this problem. Here, we build on previous work and show that neural networks equipped with a mechanism for cognitive control do not exhibit catastrophic forgetting when trials are blocked. We further show an advantage of blocking over interleaving when there is a bias for active maintenance in the control signal, implying a tradeoff between maintenance and the strength of control. Analyses of map-like representations learned by the networks provided additional insights into these mechanisms. Our work highlights the potential of cognitive control to aid continual learning in neural networks, and offers an explanation for the advantage of blocking that has been observed in humans.
Compositional Processing Emerges in Neural Networks Solving Math Problems
May 19, 2021
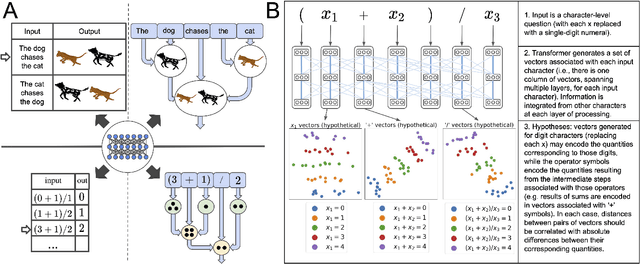
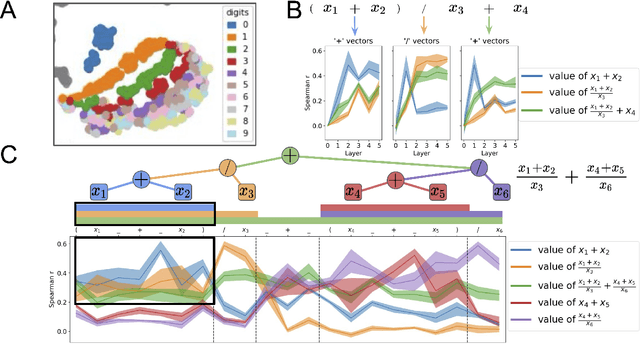
A longstanding question in cognitive science concerns the learning mechanisms underlying compositionality in human cognition. Humans can infer the structured relationships (e.g., grammatical rules) implicit in their sensory observations (e.g., auditory speech), and use this knowledge to guide the composition of simpler meanings into complex wholes. Recent progress in artificial neural networks has shown that when large models are trained on enough linguistic data, grammatical structure emerges in their representations. We extend this work to the domain of mathematical reasoning, where it is possible to formulate precise hypotheses about how meanings (e.g., the quantities corresponding to numerals) should be composed according to structured rules (e.g., order of operations). Our work shows that neural networks are not only able to infer something about the structured relationships implicit in their training data, but can also deploy this knowledge to guide the composition of individual meanings into composite wholes.
Complementary Structure-Learning Neural Networks for Relational Reasoning
May 19, 2021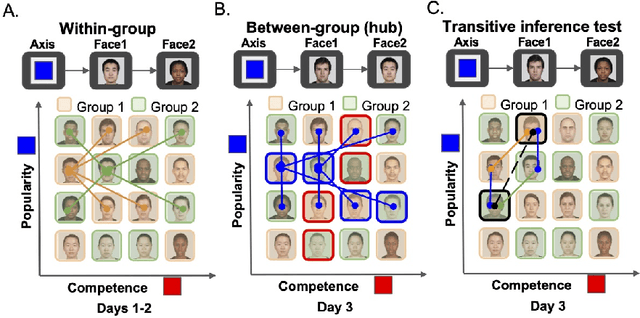
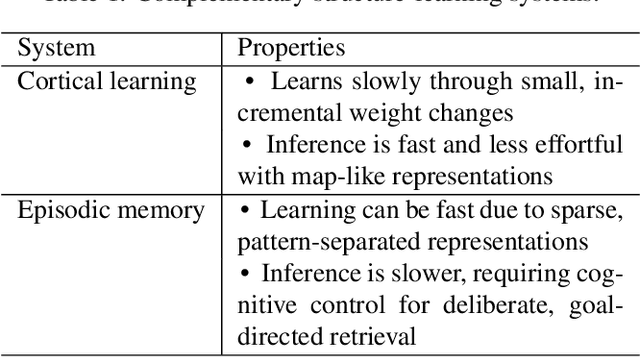
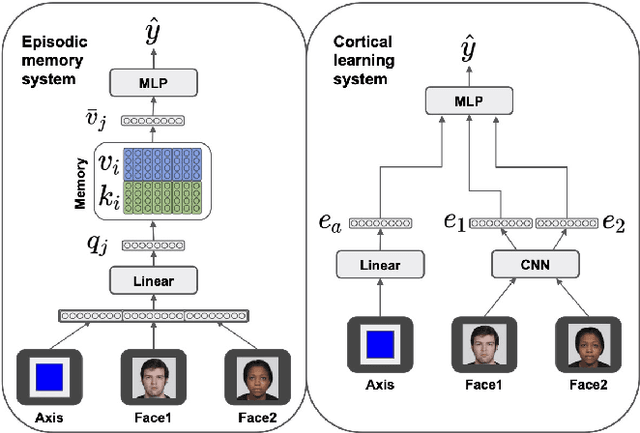
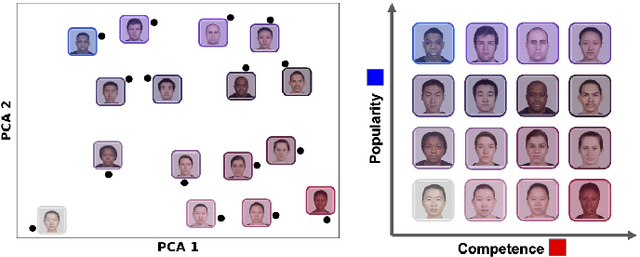
The neural mechanisms supporting flexible relational inferences, especially in novel situations, are a major focus of current research. In the complementary learning systems framework, pattern separation in the hippocampus allows rapid learning in novel environments, while slower learning in neocortex accumulates small weight changes to extract systematic structure from well-learned environments. In this work, we adapt this framework to a task from a recent fMRI experiment where novel transitive inferences must be made according to implicit relational structure. We show that computational models capturing the basic cognitive properties of these two systems can explain relational transitive inferences in both familiar and novel environments, and reproduce key phenomena observed in the fMRI experiment.