 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Curriculum Effects Emerge with In-Context Learning in Neural Networks
Feb 13, 2024Human learning is sensitive to rule-like structure and the curriculum of examples used for training. In tasks governed by succinct rules, learning is more robust when related examples are blocked across trials, but in the absence of such rules, interleaving is more effective. To date, no neural model has simultaneously captured these seemingly contradictory effects. Here we show that this same tradeoff spontaneously emerges with "in-context learning" (ICL) both in neural networks trained with metalearning and in large language models (LLMs). ICL is the ability to learn new tasks "in context" - without weight changes - via an inner-loop algorithm implemented in activation dynamics. Experiments with pretrained LLMs and metalearning transformers show that ICL exhibits the blocking advantage demonstrated in humans on a task involving rule-like structure, and conversely, that concurrent in-weight learning reproduces the interleaving advantage observed in humans on tasks lacking such structure.
Transformer Mechanisms Mimic Frontostriatal Gating Operations When Trained on Human Working Memory Tasks
Feb 13, 2024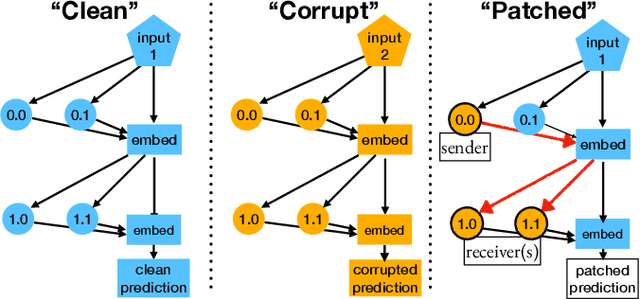
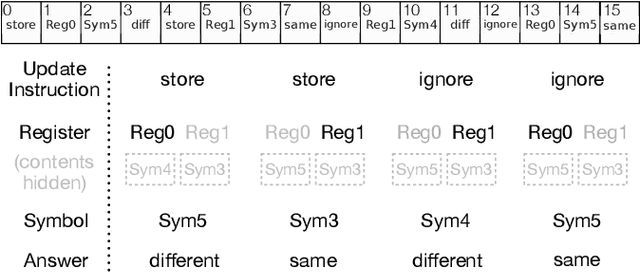
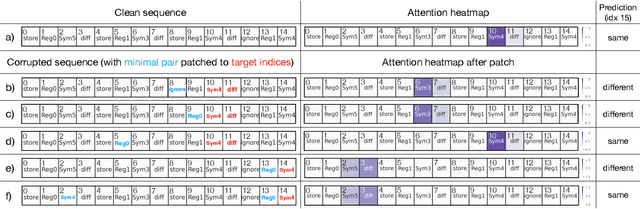
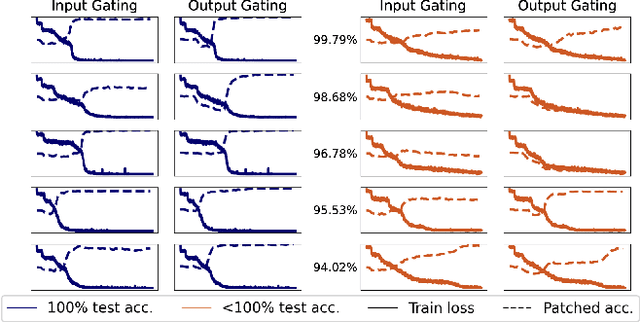
Models based on the Transformer neural network architecture have seen success on a wide variety of tasks that appear to require complex "cognitive branching" -- or the ability to maintain pursuit of one goal while accomplishing others. In cognitive neuroscience, success on such tasks is thought to rely on sophisticated frontostriatal mechanisms for selective \textit{gating}, which enable role-addressable updating -- and later readout -- of information to and from distinct "addresses" of memory, in the form of clusters of neurons. However, Transformer models have no such mechanisms intentionally built-in. It is thus an open question how Transformers solve such tasks, and whether the mechanisms that emerge to help them to do so bear any resemblance to the gating mechanisms in the human brain. In this work, we analyze the mechanisms that emerge within a vanilla attention-only Transformer trained on a simple sequence modeling task inspired by a task explicitly designed to study working memory gating in computational cognitive neuroscience. We find that, as a result of training, the self-attention mechanism within the Transformer specializes in a way that mirrors the input and output gating mechanisms which were explicitly incorporated into earlier, more biologically-inspired architectures. These results suggest opportunities for future research on computational similarities between modern AI architectures and models of the human brain.
Reward-Predictive Clustering
Nov 07, 2022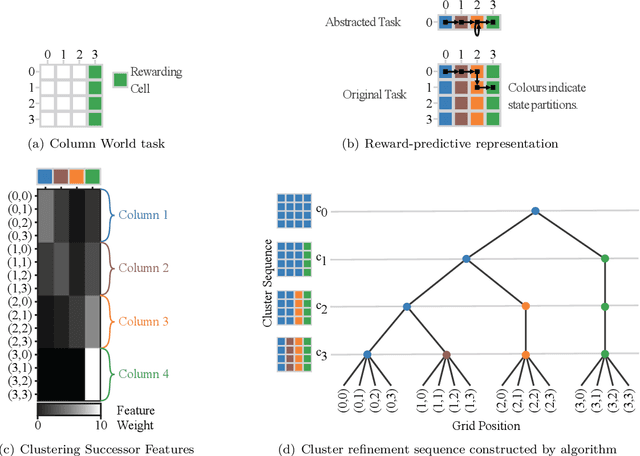
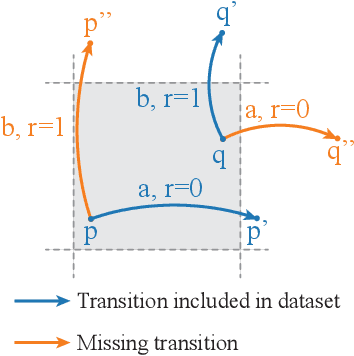

Recent advances in reinforcement-learning research have demonstrated impressive results in building algorithms that can out-perform humans in complex tasks. Nevertheless, creating reinforcement-learning systems that can build abstractions of their experience to accelerate learning in new contexts still remains an active area of research. Previous work showed that reward-predictive state abstractions fulfill this goal, but have only be applied to tabular settings. Here, we provide a clustering algorithm that enables the application of such state abstractions to deep learning settings, providing compressed representations of an agent's inputs that preserve the ability to predict sequences of reward. A convergence theorem and simulations show that the resulting reward-predictive deep network maximally compresses the agent's inputs, significantly speeding up learning in high dimensional visual control tasks. Furthermore, we present different generalization experiments and analyze under which conditions a pre-trained reward-predictive representation network can be re-used without re-training to accelerate learning -- a form of systematic out-of-distribution transfer.