 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Mechanisms Mimic Frontostriatal Gating Operations When Trained on Human Working Memory Tasks
Paper and Code
Feb 13, 2024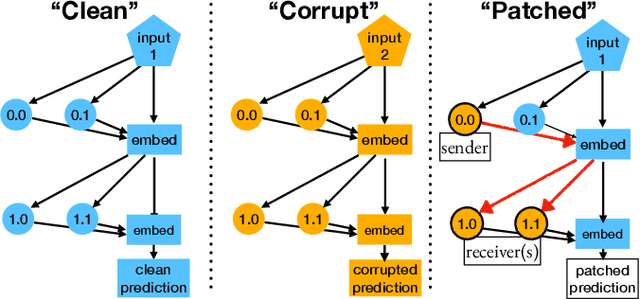
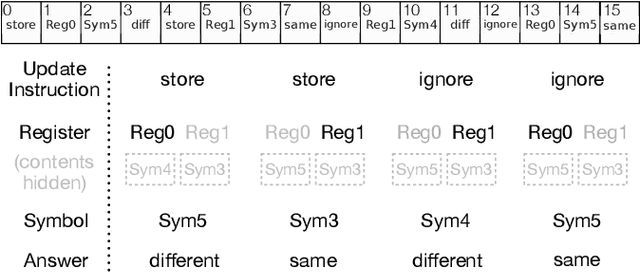
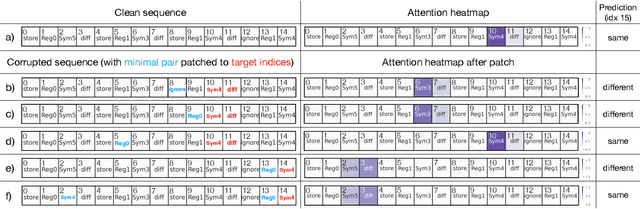
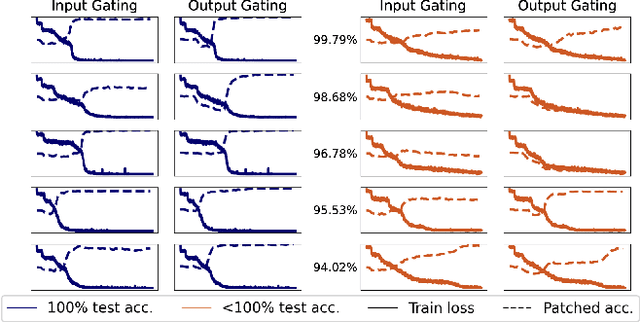
Models based on the Transformer neural network architecture have seen success on a wide variety of tasks that appear to require complex "cognitive branching" -- or the ability to maintain pursuit of one goal while accomplishing others. In cognitive neuroscience, success on such tasks is thought to rely on sophisticated frontostriatal mechanisms for selective \textit{gating}, which enable role-addressable updating -- and later readout -- of information to and from distinct "addresses" of memory, in the form of clusters of neurons. However, Transformer models have no such mechanisms intentionally built-in. It is thus an open question how Transformers solve such tasks, and whether the mechanisms that emerge to help them to do so bear any resemblance to the gating mechanisms in the human brain. In this work, we analyze the mechanisms that emerge within a vanilla attention-only Transformer trained on a simple sequence modeling task inspired by a task explicitly designed to study working memory gating in computational cognitive neuroscience. We find that, as a result of training, the self-attention mechanism within the Transformer specializes in a way that mirrors the input and output gating mechanisms which were explicitly incorporated into earlier, more biologically-inspired architectures. These results suggest opportunities for future research on computational similarities between modern AI architectures and models of the human brain.