 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmaller Abstract State Spaces Enable Cross-Scale Generalization in Reinforcement Learning
May 19, 2026While humans readily generalize abstract concepts to more complex or larger tasks, building Reinforcement Learning (RL) systems with this ability remains elusive. Here, we present the first theoretical model of how such Out-of-Distribution (OOD) generalization can be achieved in RL agents. Our approach considers Partially Observable Markov Decision Processes (POMDPs) and assumes that an intelligent agent uses an abstraction function to determine which experiences can be treated as equivalent and which must be distinguished. First, we extend the existing state abstraction framework and proof techniques to POMDPs. Then, we define a successor-weighted model reduction, a model reduction variant that enables compression into smaller abstract spaces than prior definitions allow. We derive a bound on the agent's OOD test performance, thereby defining the conditions under which OOD generalization is achievable. This bound decomposes an agent's performance loss into approximation and estimation errors, revealing how reducing an agent's abstract state space size improves test performance and OOD generalization. Our analysis suggests that constraining an agent to operate over a small, finite set of abstract states is necessary for achieving generalization to more complex tasks. Our results motivate further research into learning RL architectures that scale across tasks of varying complexity levels.
Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping
Feb 21, 2024While Transformers have enabled tremendous progress in various application settings, such architectures still lag behind traditional symbolic planners for solving complex decision making tasks. In this work, we demonstrate how to train Transformers to solve complex planning tasks and present Searchformer, a Transformer model that optimally solves previously unseen Sokoban puzzles 93.7% of the time, while using up to 26.8% fewer search steps than standard $A^*$ search. Searchformer is an encoder-decoder Transformer model trained to predict the search dynamics of $A^*$. This model is then fine-tuned via expert iterations to perform fewer search steps than $A^*$ search while still generating an optimal plan. In our training method, $A^*$'s search dynamics are expressed as a token sequence outlining when task states are added and removed into the search tree during symbolic planning. In our ablation studies on maze navigation, we find that Searchformer significantly outperforms baselines that predict the optimal plan directly with a 5-10$\times$ smaller model size and a 10$\times$ smaller training dataset. We also demonstrate how Searchformer scales to larger and more complex decision making tasks like Sokoban with improved percentage of solved tasks and shortened search dynamics.
Maximum State Entropy Exploration using Predecessor and Successor Representations
Jun 26, 2023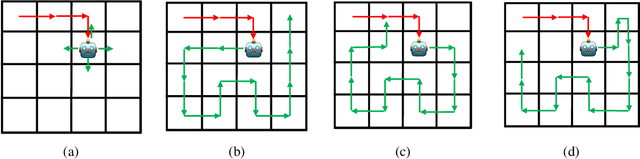

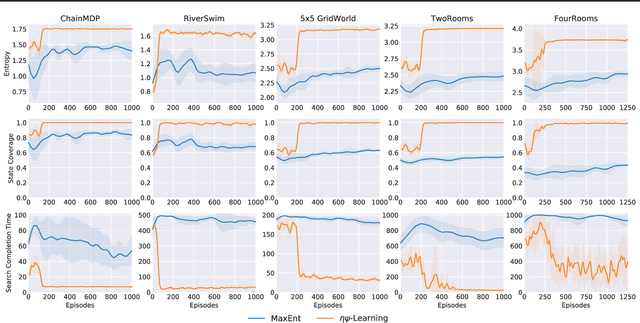

Animals have a developed ability to explore that aids them in important tasks such as locating food, exploring for shelter, and finding misplaced items. These exploration skills necessarily track where they have been so that they can plan for finding items with relative efficiency. Contemporary exploration algorithms often learn a less efficient exploration strategy because they either condition only on the current state or simply rely on making random open-loop exploratory moves. In this work, we propose $\eta\psi$-Learning, a method to learn efficient exploratory policies by conditioning on past episodic experience to make the next exploratory move. Specifically, $\eta\psi$-Learning learns an exploration policy that maximizes the entropy of the state visitation distribution of a single trajectory. Furthermore, we demonstrate how variants of the predecessor representation and successor representations can be combined to predict the state visitation entropy. Our experiments demonstrate the efficacy of $\eta\psi$-Learning to strategically explore the environment and maximize the state coverage with limited samples.
IQL-TD-MPC: Implicit Q-Learning for Hierarchical Model Predictive Control
Jun 01, 2023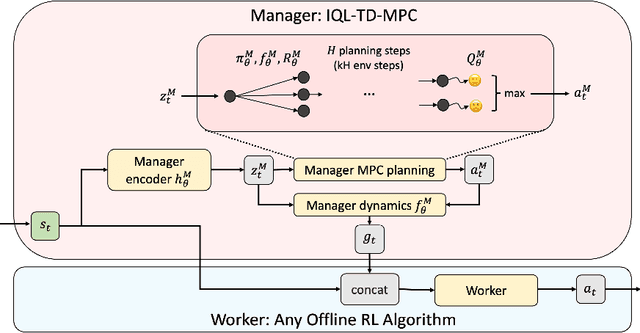
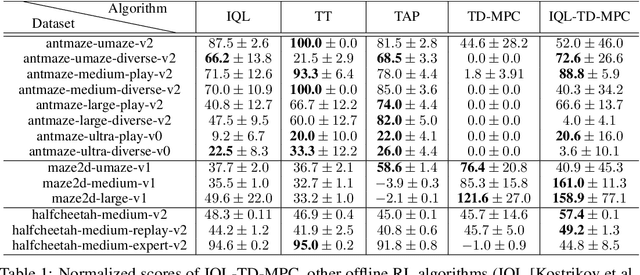

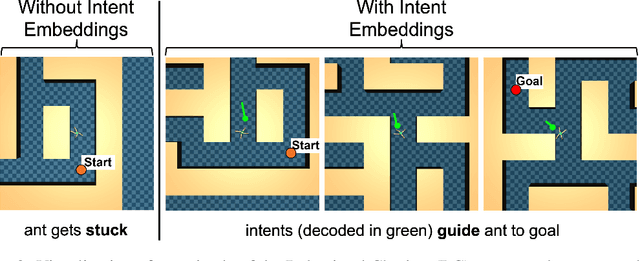
Model-based reinforcement learning (RL) has shown great promise due to its sample efficiency, but still struggles with long-horizon sparse-reward tasks, especially in offline settings where the agent learns from a fixed dataset. We hypothesize that model-based RL agents struggle in these environments due to a lack of long-term planning capabilities, and that planning in a temporally abstract model of the environment can alleviate this issue. In this paper, we make two key contributions: 1) we introduce an offline model-based RL algorithm, IQL-TD-MPC, that extends the state-of-the-art Temporal Difference Learning for Model Predictive Control (TD-MPC) with Implicit Q-Learning (IQL); 2) we propose to use IQL-TD-MPC as a Manager in a hierarchical setting with any off-the-shelf offline RL algorithm as a Worker. More specifically, we pre-train a temporally abstract IQL-TD-MPC Manager to predict "intent embeddings", which roughly correspond to subgoals, via planning. We empirically show that augmenting state representations with intent embeddings generated by an IQL-TD-MPC manager significantly improves off-the-shelf offline RL agents' performance on some of the most challenging D4RL benchmark tasks. For instance, the offline RL algorithms AWAC, TD3-BC, DT, and CQL all get zero or near-zero normalized evaluation scores on the medium and large antmaze tasks, while our modification gives an average score over 40.
Reward-Predictive Clustering
Nov 07, 2022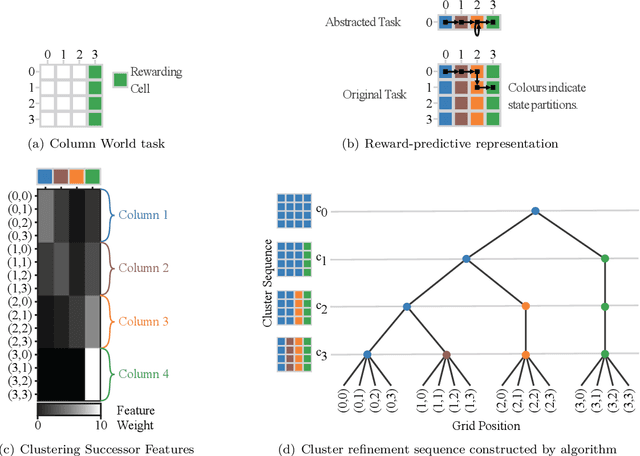
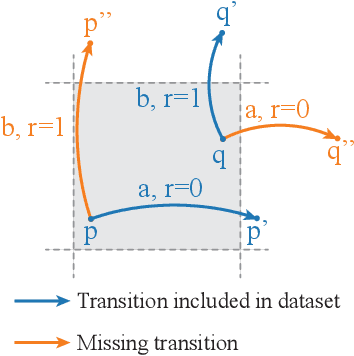

Recent advances in reinforcement-learning research have demonstrated impressive results in building algorithms that can out-perform humans in complex tasks. Nevertheless, creating reinforcement-learning systems that can build abstractions of their experience to accelerate learning in new contexts still remains an active area of research. Previous work showed that reward-predictive state abstractions fulfill this goal, but have only be applied to tabular settings. Here, we provide a clustering algorithm that enables the application of such state abstractions to deep learning settings, providing compressed representations of an agent's inputs that preserve the ability to predict sequences of reward. A convergence theorem and simulations show that the resulting reward-predictive deep network maximally compresses the agent's inputs, significantly speeding up learning in high dimensional visual control tasks. Furthermore, we present different generalization experiments and analyze under which conditions a pre-trained reward-predictive representation network can be re-used without re-training to accelerate learning -- a form of systematic out-of-distribution transfer.
Successor Features Support Model-based and Model-free Reinforcement Learning
Jan 31, 2019
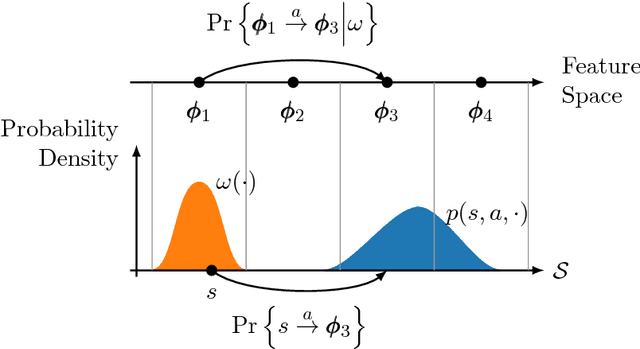
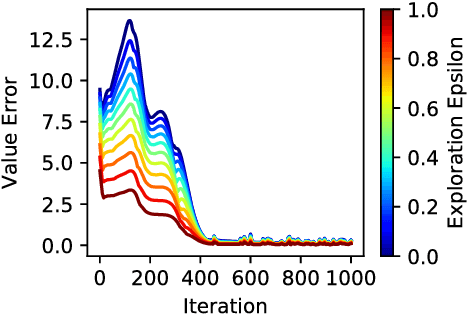
One key challenge in reinforcement learning is the ability to generalize knowledge in control problems. While deep learning methods have been successfully combined with model-free reinforcement-learning algorithms, how to perform model-based reinforcement learning in the presence of approximation errors still remains an open problem. Using successor features, a feature representation that predicts a temporal constraint, this paper presents three contributions: First, it shows how learning successor features is equivalent to model-free learning. Then, it shows how successor features encode model reductions that compress the state space by creating state partitions of bisimilar states. Using this representation, an intelligent agent is guaranteed to accurately predict future reward outcomes, a key property of model-based reinforcement-learning algorithms. Lastly, it presents a loss objective and prediction error bounds showing that accurately predicting value functions and reward sequences is possible with an approximation of successor features. On finite control problems, we illustrate how minimizing this loss objective results in approximate bisimulations. The results presented in this paper provide a novel understanding of representations that can support model-free and model-based reinforcement learning.
Mitigating Planner Overfitting in Model-Based Reinforcement Learning
Dec 03, 2018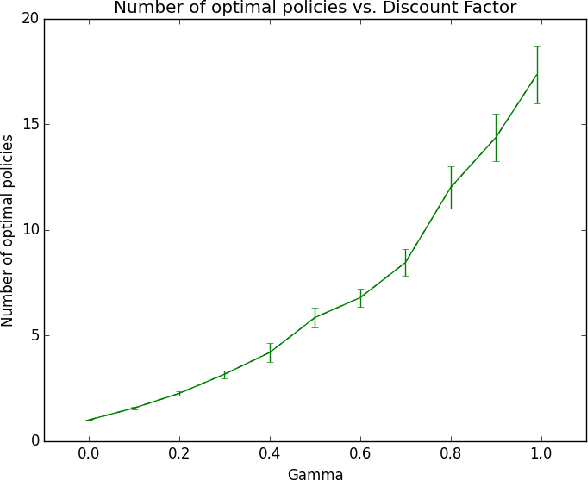
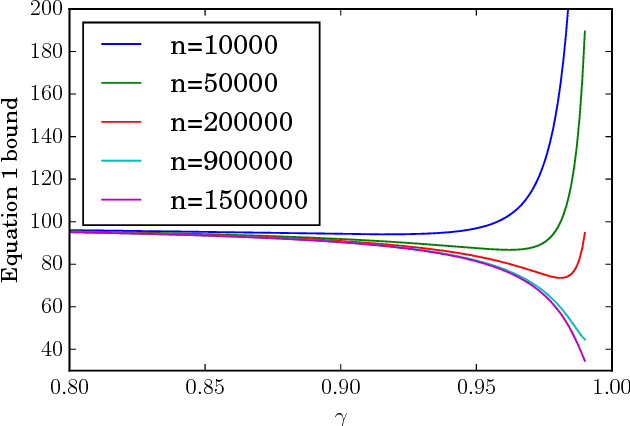
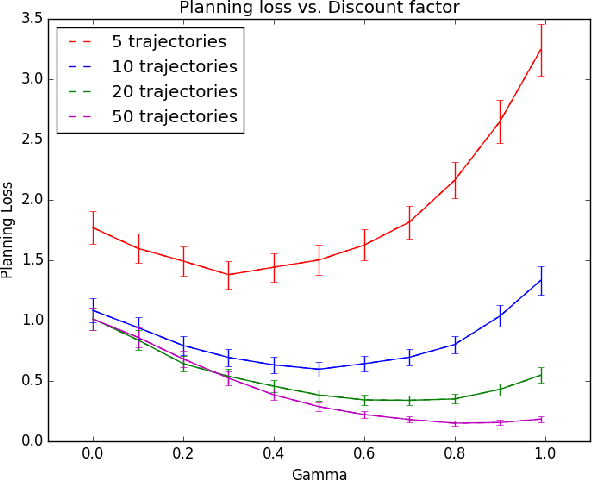
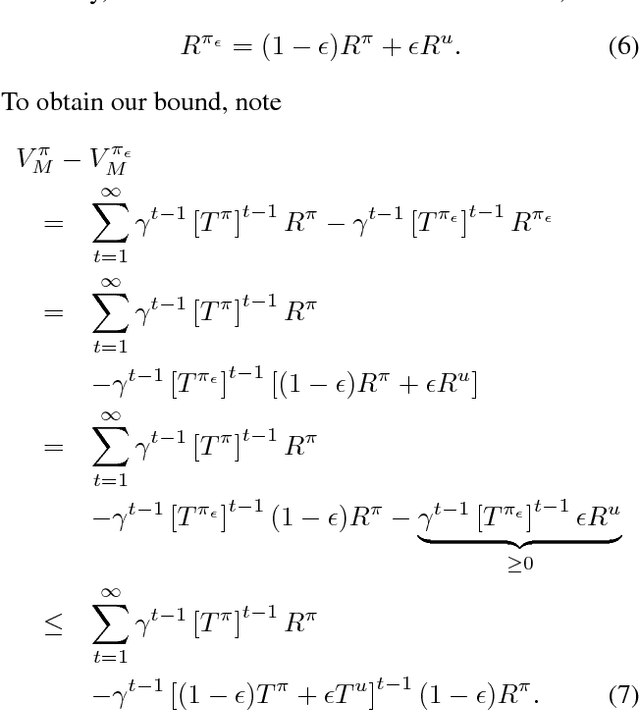
An agent with an inaccurate model of its environment faces a difficult choice: it can ignore the errors in its model and act in the real world in whatever way it determines is optimal with respect to its model. Alternatively, it can take a more conservative stance and eschew its model in favor of optimizing its behavior solely via real-world interaction. This latter approach can be exceedingly slow to learn from experience, while the former can lead to "planner overfitting" - aspects of the agent's behavior are optimized to exploit errors in its model. This paper explores an intermediate position in which the planner seeks to avoid overfitting through a kind of regularization of the plans it considers. We present three different approaches that demonstrably mitigate planner overfitting in reinforcement-learning environments.
Transfer with Model Features in Reinforcement Learning
Jul 04, 2018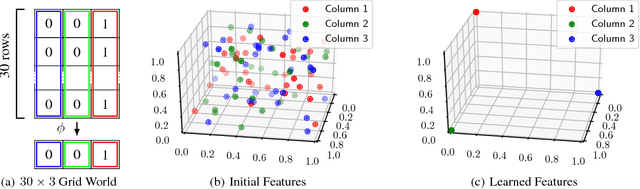
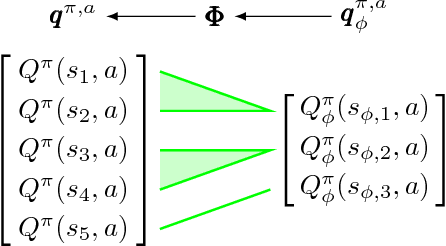
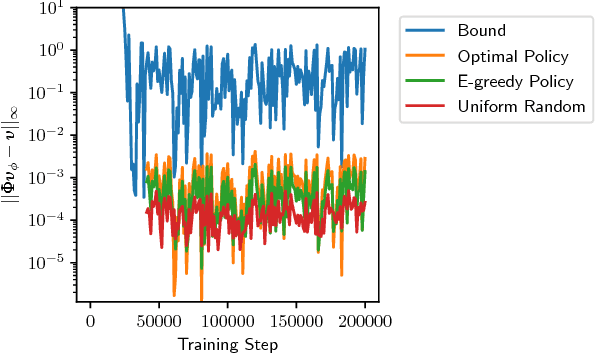
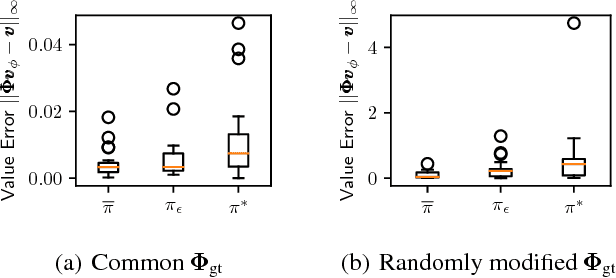
A key question in Reinforcement Learning is which representation an agent can learn to efficiently reuse knowledge between different tasks. Recently the Successor Representation was shown to have empirical benefits for transferring knowledge between tasks with shared transition dynamics. This paper presents Model Features: a feature representation that clusters behaviourally equivalent states and that is equivalent to a Model-Reduction. Further, we present a Successor Feature model which shows that learning Successor Features is equivalent to learning a Model-Reduction. A novel optimization objective is developed and we provide bounds showing that minimizing this objective results in an increasingly improved approximation of a Model-Reduction. Further, we provide transfer experiments on randomly generated MDPs which vary in their transition and reward functions but approximately preserve behavioural equivalence between states. These results demonstrate that Model Features are suitable for transfer between tasks with varying transition and reward functions.
Advantages and Limitations of using Successor Features for Transfer in Reinforcement Learning
Jul 31, 2017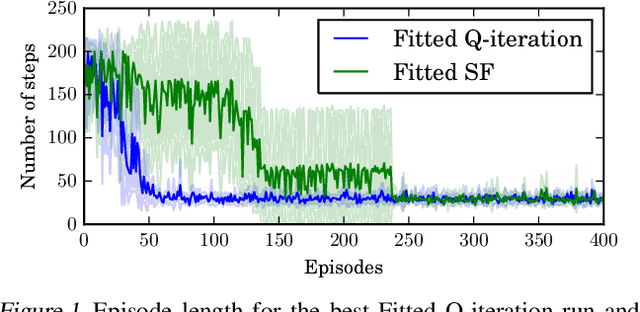
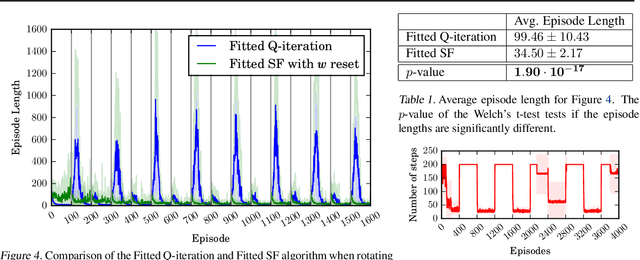
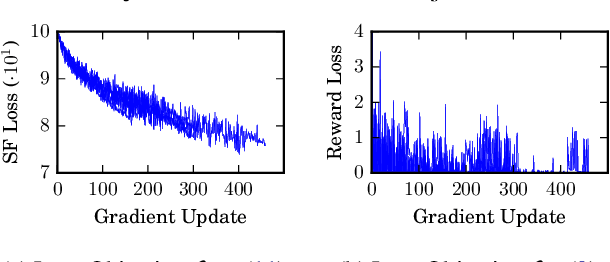
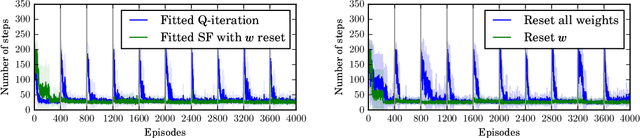
One question central to Reinforcement Learning is how to learn a feature representation that supports algorithm scaling and re-use of learned information from different tasks. Successor Features approach this problem by learning a feature representation that satisfies a temporal constraint. We present an implementation of an approach that decouples the feature representation from the reward function, making it suitable for transferring knowledge between domains. We then assess the advantages and limitations of using Successor Features for transfer.
Policy Gradient Methods for Off-policy Control
Dec 13, 2015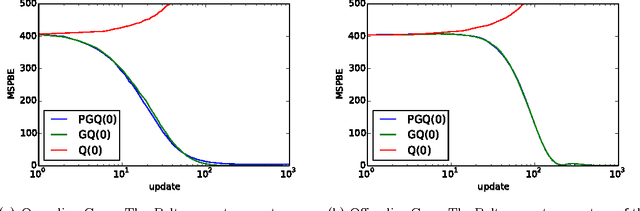
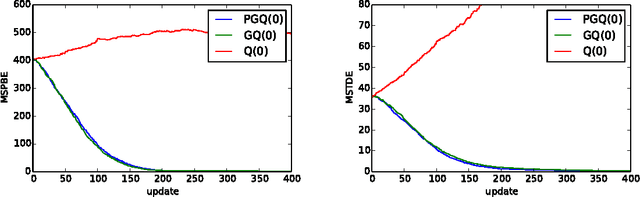
Off-policy learning refers to the problem of learning the value function of a way of behaving, or policy, while following a different policy. Gradient-based off-policy learning algorithms, such as GTD and TDC/GQ, converge even when using function approximation and incremental updates. However, they have been developed for the case of a fixed behavior policy. In control problems, one would like to adapt the behavior policy over time to become more greedy with respect to the existing value function. In this paper, we present the first gradient-based learning algorithms for this problem, which rely on the framework of policy gradient in order to modify the behavior policy. We present derivations of the algorithms, a convergence theorem, and empirical evidence showing that they compare favorably to existing approaches.