 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStageCraft: Execution Aware Mitigation of Distractor and Obstruction Failures in VLA Models
Mar 21, 2026Large scale pre-training on text and image data along with diverse robot demonstrations has helped Vision Language Action models (VLAs) to generalize to novel tasks, objects and scenes. However, these models are still susceptible to failure in the presence of execution-time impediments such as distractors and physical obstructions in the robot's workspace. Existing policy improvement methods finetune base VLAs to improve generalization, yet they still struggle in unseen distractor settings. To address this problem, we investigate whether internet-scale pretraining of large vision-language models (VLMs) can be leveraged to reason about these impediments and mitigate policy failures. To this end, we propose StageCraft, a training-free approach to improve pretrained VLA policy performance by manipulating the environment's initial state using VLM-based in-context reasoning. StageCraft takes policy rollout videos and success labels as input and leverages VLM's reasoning ability to infer which objects in the initial state need to be manipulated to avoid anticipated execution failures. StageCraft is an extensible plug-and-play module that does not introduce additional constraints on the underlying policy, and only requires a few policy rollouts to work. We evaluate performance of state-of-the-art VLA models with StageCraft and show an absolute 40% performance improvement across three real world task domains involving diverse distractors and obstructions. Our simulation experiments in RLBench empirically show that StageCraft tailors its extent of intervention based on the strength of the underlying policy and improves its performance with more in-context samples. Videos of StageCraft in effect can be found at https://stagecraft-decorator.github.io/stagecraft/ .
Meanings and Measurements: Multi-Agent Probabilistic Grounding for Vision-Language Navigation
Mar 19, 2026Robots collaborating with humans must convert natural language goals into actionable, physically grounded decisions. For example, executing a command such as "go two meters to the right of the fridge" requires grounding semantic references, spatial relations, and metric constraints within a 3D scene. While recent vision language models (VLMs) demonstrate strong semantic grounding capabilities, they are not explicitly designed to reason about metric constraints in physically defined spaces. In this work, we empirically demonstrate that state-of-the-art VLM-based grounding approaches struggle with complex metric-semantic language queries. To address this limitation, we propose MAPG (Multi-Agent Probabilistic Grounding), an agentic framework that decomposes language queries into structured subcomponents and queries a VLM to ground each component. MAPG then probabilistically composes these grounded outputs to produce metrically consistent, actionable decisions in 3D space. We evaluate MAPG on the HM-EQA benchmark and show consistent performance improvements over strong baselines. Furthermore, we introduce a new benchmark, MAPG-Bench, specifically designed to evaluate metric-semantic goal grounding, addressing a gap in existing language grounding evaluations. We also present a real-world robot demonstration showing that MAPG transfers beyond simulation when a structured scene representation is available.
You've Got a Golden Ticket: Improving Generative Robot Policies With A Single Noise Vector
Mar 16, 2026What happens when a pretrained generative robot policy is provided a constant initial noise as input, rather than repeatedly sampling it from a Gaussian? We demonstrate that the performance of a pretrained, frozen diffusion or flow matching policy can be improved with respect to a downstream reward by swapping the sampling of initial noise from the prior distribution (typically isotropic Gaussian) with a well-chosen, constant initial noise input -- a golden ticket. We propose a search method to find golden tickets using Monte-Carlo policy evaluation that keeps the pretrained policy frozen, does not train any new networks, and is applicable to all diffusion/flow matching policies (and therefore many VLAs). Our approach to policy improvement makes no assumptions beyond being able to inject initial noise into the policy and calculate (sparse) task rewards of episode rollouts, making it deployable with no additional infrastructure or models. Our method improves the performance of policies in 38 out of 43 tasks across simulated and real-world robot manipulation benchmarks, with relative improvements in success rate by up to 58% for some simulated tasks, and 60% within 50 search episodes for real-world tasks. We also show unique benefits of golden tickets for multi-task settings: the diversity of behaviors from different tickets naturally defines a Pareto frontier for balancing different objectives (e.g., speed, success rates); in VLAs, we find that a golden ticket optimized for one task can also boost performance in other related tasks. We release a codebase with pretrained policies and golden tickets for simulation benchmarks using VLAs, diffusion policies, and flow matching policies.
PokeNet: Learning Kinematic Models of Articulated Objects from Human Observations
Feb 02, 2026Articulation modeling enables robots to learn joint parameters of articulated objects for effective manipulation which can then be used downstream for skill learning or planning. Existing approaches often rely on prior knowledge about the objects, such as the number or type of joints. Some of these approaches also fail to recover occluded joints that are only revealed during interaction. Others require large numbers of multi-view images for every object, which is impractical in real-world settings. Furthermore, prior works neglect the order of manipulations, which is essential for many multi-DoF objects where one joint must be operated before another, such as a dishwasher. We introduce PokeNet, an end-to-end framework that estimates articulation models from a single human demonstration without prior object knowledge. Given a sequence of point cloud observations of a human manipulating an unknown object, PokeNet predicts joint parameters, infers manipulation order, and tracks joint states over time. PokeNet outperforms existing state-of-the-art methods, improving joint axis and state estimation accuracy by an average of over 27% across diverse objects, including novel and unseen categories. We demonstrate these gains in both simulation and real-world environments.
Learning Sequential Kinematic Models from Demonstrations for Multi-Jointed Articulated Objects
May 09, 2025As robots become more generalized and deployed in diverse environments, they must interact with complex objects, many with multiple independent joints or degrees of freedom (DoF) requiring precise control. A common strategy is object modeling, where compact state-space models are learned from real-world observations and paired with classical planning. However, existing methods often rely on prior knowledge or focus on single-DoF objects, limiting their applicability. They also fail to handle occluded joints and ignore the manipulation sequences needed to access them. We address this by learning object models from human demonstrations. We introduce Object Kinematic Sequence Machines (OKSMs), a novel representation capturing both kinematic constraints and manipulation order for multi-DoF objects. To estimate these models from point cloud data, we present Pokenet, a deep neural network trained on human demonstrations. We validate our approach on 8,000 simulated and 1,600 real-world annotated samples. Pokenet improves joint axis and state estimation by over 20 percent on real-world data compared to prior methods. Finally, we demonstrate OKSMs on a Sawyer robot using inverse kinematics-based planning to manipulate multi-DoF objects.
Composing Diffusion Policies for Few-shot Learning of Movement Trajectories
Oct 22, 2024



Humans can perform various combinations of physical skills without having to relearn skills from scratch every single time. For example, we can swing a bat when walking without having to re-learn such a policy from scratch by composing the individual skills of walking and bat swinging. Enabling robots to combine or compose skills is essential so they can learn novel skills and tasks faster with fewer real world samples. To this end, we propose a novel compositional approach called DSE- Diffusion Score Equilibrium that enables few-shot learning for novel skills by utilizing a combination of base policy priors. Our method is based on probabilistically composing diffusion policies to better model the few-shot demonstration data-distribution than any individual policy. Our goal here is to learn robot motions few-shot and not necessarily goal oriented trajectories. Unfortunately we lack a general purpose metric to evaluate the error between a skill or motion and the provided demonstrations. Hence, we propose a probabilistic measure - Maximum Mean Discrepancy on the Forward Kinematics Kernel (MMD-FK), that is task and action space agnostic. By using our few-shot learning approach DSE, we show that we are able to achieve a reduction of over 30% in MMD-FK across skills and number of demonstrations. Moreover, we show the utility of our approach through real world experiments by teaching novel trajectories to a robot in 5 demonstrations.
Continual Skill and Task Learning via Dialogue
Sep 05, 2024
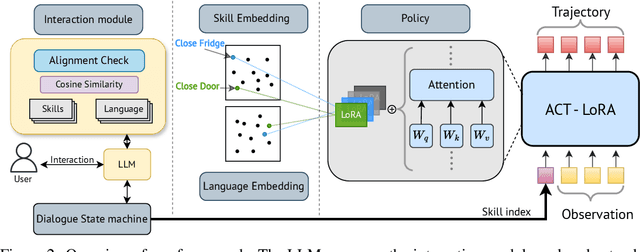
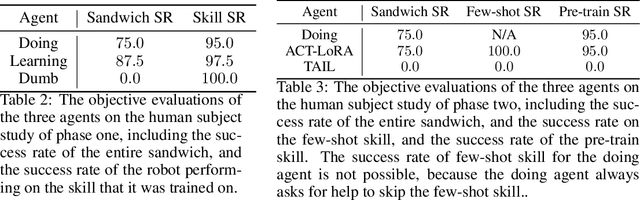

Continual and interactive robot learning is a challenging problem as the robot is present with human users who expect the robot to learn novel skills to solve novel tasks perpetually with sample efficiency. In this work we present a framework for robots to query and learn visuo-motor robot skills and task relevant information via natural language dialog interactions with human users. Previous approaches either focus on improving the performance of instruction following agents, or passively learn novel skills or concepts. Instead, we used dialog combined with a language-skill grounding embedding to query or confirm skills and/or tasks requested by a user. To achieve this goal, we developed and integrated three different components for our agent. Firstly, we propose a novel visual-motor control policy ACT with Low Rank Adaptation (ACT-LoRA), which enables the existing SoTA ACT model to perform few-shot continual learning. Secondly, we develop an alignment model that projects demonstrations across skill embodiments into a shared embedding allowing us to know when to ask questions and/or demonstrations from users. Finally, we integrated an existing LLM to interact with a human user to perform grounded interactive continual skill learning to solve a task. Our ACT-LoRA model learns novel fine-tuned skills with a 100% accuracy when trained with only five demonstrations for a novel skill while still maintaining a 74.75% accuracy on pre-trained skills in the RLBench dataset where other models fall significantly short. We also performed a human-subjects study with 8 subjects to demonstrate the continual learning capabilities of our combined framework. We achieve a success rate of 75% in the task of sandwich making with the real robot learning from participant data demonstrating that robots can learn novel skills or task knowledge from dialogue with non-expert users using our approach.
Interactive Visual Task Learning for Robots
Dec 20, 2023
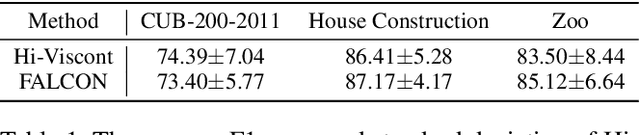
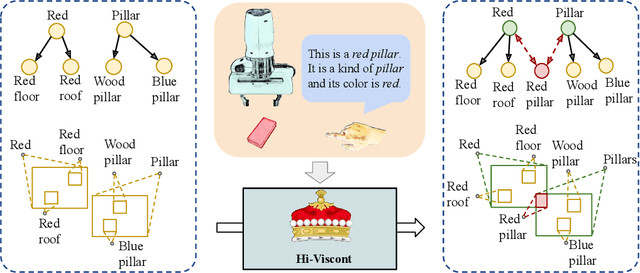

We present a framework for robots to learn novel visual concepts and tasks via in-situ linguistic interactions with human users. Previous approaches have either used large pre-trained visual models to infer novel objects zero-shot, or added novel concepts along with their attributes and representations to a concept hierarchy. We extend the approaches that focus on learning visual concept hierarchies by enabling them to learn novel concepts and solve unseen robotics tasks with them. To enable a visual concept learner to solve robotics tasks one-shot, we developed two distinct techniques. Firstly, we propose a novel approach, Hi-Viscont(HIerarchical VISual CONcept learner for Task), which augments information of a novel concept to its parent nodes within a concept hierarchy. This information propagation allows all concepts in a hierarchy to update as novel concepts are taught in a continual learning setting. Secondly, we represent a visual task as a scene graph with language annotations, allowing us to create novel permutations of a demonstrated task zero-shot in-situ. We present two sets of results. Firstly, we compare Hi-Viscont with the baseline model (FALCON) on visual question answering(VQA) in three domains. While being comparable to the baseline model on leaf level concepts, Hi-Viscont achieves an improvement of over 9% on non-leaf concepts on average. We compare our model's performance against the baseline FALCON model. Our framework achieves 33% improvements in success rate metric, and 19% improvements in the object level accuracy compared to the baseline model. With both of these results we demonstrate the ability of our model to learn tasks and concepts in a continual learning setting on the robot.
Improved Inference of Human Intent by Combining Plan Recognition and Language Feedback
Oct 03, 2023



Conversational assistive robots can aid people, especially those with cognitive impairments, to accomplish various tasks such as cooking meals, performing exercises, or operating machines. However, to interact with people effectively, robots must recognize human plans and goals from noisy observations of human actions, even when the user acts sub-optimally. Previous works on Plan and Goal Recognition (PGR) as planning have used hierarchical task networks (HTN) to model the actor/human. However, these techniques are insufficient as they do not have user engagement via natural modes of interaction such as language. Moreover, they have no mechanisms to let users, especially those with cognitive impairments, know of a deviation from their original plan or about any sub-optimal actions taken towards their goal. We propose a novel framework for plan and goal recognition in partially observable domains -- Dialogue for Goal Recognition (D4GR) enabling a robot to rectify its belief in human progress by asking clarification questions about noisy sensor data and sub-optimal human actions. We evaluate the performance of D4GR over two simulated domains -- kitchen and blocks domain. With language feedback and the world state information in a hierarchical task model, we show that D4GR framework for the highest sensor noise performs 1% better than HTN in goal accuracy in both domains. For plan accuracy, D4GR outperforms by 4% in the kitchen domain and 2% in the blocks domain in comparison to HTN. The ALWAYS-ASK oracle outperforms our policy by 3% in goal recognition and 7%in plan recognition. D4GR does so by asking 68% fewer questions than an oracle baseline. We also demonstrate a real-world robot scenario in the kitchen domain, validating the improved plan and goal recognition of D4GR in a realistic setting.
Language-Conditioned Change-point Detection to Identify Sub-Tasks in Robotics Domains
Sep 01, 2023



In this work, we present an approach to identify sub-tasks within a demonstrated robot trajectory using language instructions. We identify these sub-tasks using language provided during demonstrations as guidance to identify sub-segments of a longer robot trajectory. Given a sequence of natural language instructions and a long trajectory consisting of image frames and discrete actions, we want to map an instruction to a smaller fragment of the trajectory. Unlike previous instruction following works which directly learn the mapping from language to a policy, we propose a language-conditioned change-point detection method to identify sub-tasks in a problem. Our approach learns the relationship between constituent segments of a long language command and corresponding constituent segments of a trajectory. These constituent trajectory segments can be used to learn subtasks or sub-goals for planning or options as demonstrated by previous related work. Our insight in this work is that the language-conditioned robot change-point detection problem is similar to the existing video moment retrieval works used to identify sub-segments within online videos. Through extensive experimentation, we demonstrate a $1.78_{\pm 0.82}\%$ improvement over a baseline approach in accurately identifying sub-tasks within a trajectory using our proposed method. Moreover, we present a comprehensive study investigating sample complexity requirements on learning this mapping, between language and trajectory sub-segments, to understand if the video retrieval-based methods are realistic in real robot scenarios.