 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Efficient Exploration through Human Seeded Rapidly-exploring Random Trees
Mar 23, 2022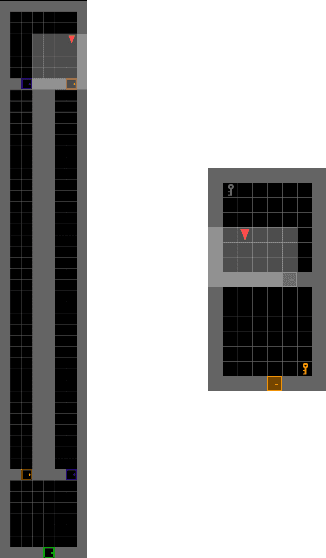
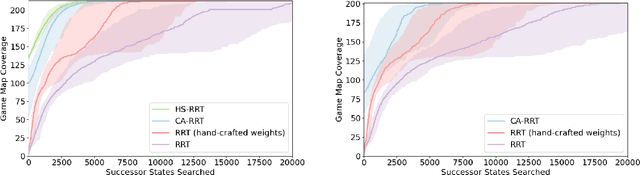
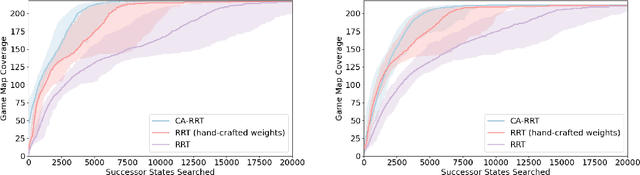
Modern day computer games have extremely large state and action spaces. To detect bugs in these games' models, human testers play the games repeatedly to explore the game and find errors in the games. Such game play is exhaustive and time consuming. Moreover, since robotics simulators depend on similar methods of model specification and debugging, the problem of finding errors in the model is of interest for the robotics community to ensure robot behaviors and interactions are consistent in simulators. Previous methods have used reinforcement learning and search based methods including Rapidly-exploring Random Trees (RRT) to explore a game's state-action space to find bugs. However, such search and exploration based methods are not efficient at exploring the state-action space without a pre-defined heuristic. In this work we attempt to combine a human-tester's expertise in solving games, and the exhaustiveness of RRT to search a game's state space efficiently with high coverage. This paper introduces human-seeded RRT (HS-RRT) and behavior-cloning-assisted RRT (CA-RRT) in testing the number of game states searched and the time taken to explore those game states. We compare our methods to an existing weighted RRT baseline for game exploration testing studied. We find HS-RRT and CA-RRT both explore more game states in fewer tree expansions/iterations when compared to the existing baseline. In each test, CA-RRT reached more states on average in the same number of iterations as RRT. In our tested environments, CA-RRT was able to reach the same number of states as RRT by more than 5000 fewer iterations on average, almost a 50% reduction.