 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposing Diffusion Policies for Few-shot Learning of Movement Trajectories
Oct 22, 2024



Humans can perform various combinations of physical skills without having to relearn skills from scratch every single time. For example, we can swing a bat when walking without having to re-learn such a policy from scratch by composing the individual skills of walking and bat swinging. Enabling robots to combine or compose skills is essential so they can learn novel skills and tasks faster with fewer real world samples. To this end, we propose a novel compositional approach called DSE- Diffusion Score Equilibrium that enables few-shot learning for novel skills by utilizing a combination of base policy priors. Our method is based on probabilistically composing diffusion policies to better model the few-shot demonstration data-distribution than any individual policy. Our goal here is to learn robot motions few-shot and not necessarily goal oriented trajectories. Unfortunately we lack a general purpose metric to evaluate the error between a skill or motion and the provided demonstrations. Hence, we propose a probabilistic measure - Maximum Mean Discrepancy on the Forward Kinematics Kernel (MMD-FK), that is task and action space agnostic. By using our few-shot learning approach DSE, we show that we are able to achieve a reduction of over 30% in MMD-FK across skills and number of demonstrations. Moreover, we show the utility of our approach through real world experiments by teaching novel trajectories to a robot in 5 demonstrations.
Interactive Visual Task Learning for Robots
Dec 20, 2023
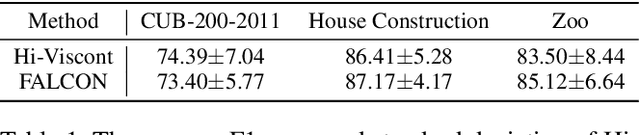
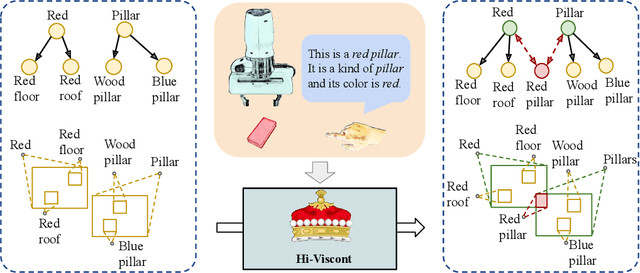

We present a framework for robots to learn novel visual concepts and tasks via in-situ linguistic interactions with human users. Previous approaches have either used large pre-trained visual models to infer novel objects zero-shot, or added novel concepts along with their attributes and representations to a concept hierarchy. We extend the approaches that focus on learning visual concept hierarchies by enabling them to learn novel concepts and solve unseen robotics tasks with them. To enable a visual concept learner to solve robotics tasks one-shot, we developed two distinct techniques. Firstly, we propose a novel approach, Hi-Viscont(HIerarchical VISual CONcept learner for Task), which augments information of a novel concept to its parent nodes within a concept hierarchy. This information propagation allows all concepts in a hierarchy to update as novel concepts are taught in a continual learning setting. Secondly, we represent a visual task as a scene graph with language annotations, allowing us to create novel permutations of a demonstrated task zero-shot in-situ. We present two sets of results. Firstly, we compare Hi-Viscont with the baseline model (FALCON) on visual question answering(VQA) in three domains. While being comparable to the baseline model on leaf level concepts, Hi-Viscont achieves an improvement of over 9% on non-leaf concepts on average. We compare our model's performance against the baseline FALCON model. Our framework achieves 33% improvements in success rate metric, and 19% improvements in the object level accuracy compared to the baseline model. With both of these results we demonstrate the ability of our model to learn tasks and concepts in a continual learning setting on the robot.