 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic Synthetic Household Data Generation at Scale
Feb 06, 2026Advancements in foundation models have catalyzed research in Embodied AI to develop interactive agents capable of environmental reasoning and interaction. Developing such agents requires diverse, large-scale datasets. Prior frameworks generate synthetic data for long-term human-robot interactions but fail to model the bidirectional influence between human behavior and household environments. Our proposed generative framework creates household datasets at scale through loosely coupled generation of long-term human-robot interactions and environments. Human personas influence environment generation, while environment schematics and semantics shape human-robot interactions. The generated 3D data includes rich static context such as object and environment semantics, and temporal context capturing human and agent behaviors over extended periods. Our flexible tool allows users to define dataset characteristics via natural language prompts, enabling configuration of environment and human activity data through natural language specifications. The tool creates variations of user-defined configurations, enabling scalable data generation. We validate our framework through statistical evaluation using multi-modal embeddings and key metrics: cosine similarity, mutual information gain, intervention analysis, and iterative improvement validation. Statistical comparisons show good alignment with real-world datasets (HOMER) with cosine similarity (0.60), while synthetic datasets (Wang et al.) show moderate alignment (0.27). Intervention analysis across age, organization, and sleep pattern changes shows statistically significant effects (p < 0.001) with large effect sizes (Cohen's d = 0.51-1.12), confirming bidirectional coupling translates persona traits into measurable environmental and behavioral differences. These contributions enable development and testing of household smart devices at scale.
LaNMP: A Language-Conditioned Mobile Manipulation Benchmark for Autonomous Robots
Nov 28, 2024


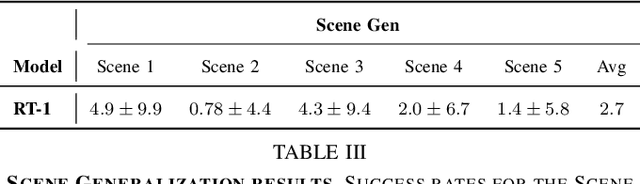
As robots that follow natural language become more capable and prevalent, we need a benchmark to holistically develop and evaluate their ability to solve long-horizon mobile manipulation tasks in large, diverse environments. To tackle this challenge, robots must use visual and language understanding, navigation, and manipulation capabilities. Existing datasets do not integrate all these aspects, restricting their efficacy as benchmarks. To address this gap, we present the Language, Navigation, Manipulation, Perception (LaNMP, pronounced Lamp) dataset and demonstrate the benefits of integrating these four capabilities and various modalities. LaNMP comprises 574 trajectories across eight simulated and real-world environments for long-horizon room-to-room pick-and-place tasks specified by natural language. Every trajectory consists of over 20 attributes, including RGB-D images, segmentations, and the poses of the robot body, end-effector, and grasped objects. We fine-tuned and tested two models in simulation, and evaluated a third on a physical robot, to demonstrate the benchmark's applicability in development and evaluation, as well as making models more sample efficient. The models performed suboptimally compared to humans; however, showed promise in increasing model sample efficiency, indicating significant room for developing more sample efficient multimodal mobile manipulation models using our benchmark.
A Framework for Realistic Simulation of Daily Human Activity
Nov 26, 2023For social robots like Astro which interact with and adapt to the daily movements of users within the home, realistic simulation of human activity is needed for feature development and testing. This paper presents a framework for simulating daily human activity patterns in home environments at scale, supporting manual configurability of different personas or activity patterns, variation of activity timings, and testing on multiple home layouts. We introduce a method for specifying day-to-day variation in schedules and present a bidirectional constraint propagation algorithm for generating schedules from templates. We validate the expressive power of our framework through a use case scenario analysis and demonstrate that our method can be used to generate data closely resembling human behavior from three public datasets and a self-collected dataset. Our contribution supports systematic testing of social robot behaviors at scale, enables procedural generation of synthetic datasets of human movement in different households, and can help minimize bias in training data, leading to more robust and effective robots for home environments.
Improved Inference of Human Intent by Combining Plan Recognition and Language Feedback
Oct 03, 2023



Conversational assistive robots can aid people, especially those with cognitive impairments, to accomplish various tasks such as cooking meals, performing exercises, or operating machines. However, to interact with people effectively, robots must recognize human plans and goals from noisy observations of human actions, even when the user acts sub-optimally. Previous works on Plan and Goal Recognition (PGR) as planning have used hierarchical task networks (HTN) to model the actor/human. However, these techniques are insufficient as they do not have user engagement via natural modes of interaction such as language. Moreover, they have no mechanisms to let users, especially those with cognitive impairments, know of a deviation from their original plan or about any sub-optimal actions taken towards their goal. We propose a novel framework for plan and goal recognition in partially observable domains -- Dialogue for Goal Recognition (D4GR) enabling a robot to rectify its belief in human progress by asking clarification questions about noisy sensor data and sub-optimal human actions. We evaluate the performance of D4GR over two simulated domains -- kitchen and blocks domain. With language feedback and the world state information in a hierarchical task model, we show that D4GR framework for the highest sensor noise performs 1% better than HTN in goal accuracy in both domains. For plan accuracy, D4GR outperforms by 4% in the kitchen domain and 2% in the blocks domain in comparison to HTN. The ALWAYS-ASK oracle outperforms our policy by 3% in goal recognition and 7%in plan recognition. D4GR does so by asking 68% fewer questions than an oracle baseline. We also demonstrate a real-world robot scenario in the kitchen domain, validating the improved plan and goal recognition of D4GR in a realistic setting.
Lang2LTL: Translating Natural Language Commands to Temporal Robot Task Specification
Feb 22, 2023


Natural language provides a powerful modality to program robots to perform temporal tasks. Linear temporal logic (LTL) provides unambiguous semantics for formal descriptions of temporal tasks. However, existing approaches cannot accurately and robustly translate English sentences to their equivalent LTL formulas in unseen environments. To address this problem, we propose Lang2LTL, a novel modular system that leverages pretrained large language models to first extract referring expressions from a natural language command, then ground the expressions to real-world landmarks and objects, and finally translate the command into an LTL task specification for the robot. It enables any robotic system to interpret natural language navigation commands without additional training, provided that it tracks its position and has a semantic map with landmarks labeled with free-form text. We demonstrate the state-of-the-art ability to generalize to multi-scale navigation domains such as OpenStreetMap (OSM) and CleanUp World (a simulated household environment). Lang2LTL achieves an average accuracy of 88.4% in translating challenging LTL formulas in 22 unseen OSM environments as evaluated on a new corpus of over 10,000 commands, 22 times better than the previous SoTA. Without modification, the best performing Lang2LTL model on the OSM dataset can translate commands in CleanUp World with 82.8% accuracy. As a part of our proposed comprehensive evaluation procedures, we collected a new labeled dataset of English commands representing 2,125 unique LTL formulas, the largest ever dataset of natural language commands to LTL specifications for robotic tasks with the most diverse LTL formulas, 40 times more than previous largest dataset. Finally, we integrated Lang2LTL with a planner to command a quadruped mobile robot to perform multi-step navigational tasks in an analog real-world environment created in the lab.
Planning with Large Language Models via Corrective Re-prompting
Nov 17, 2022
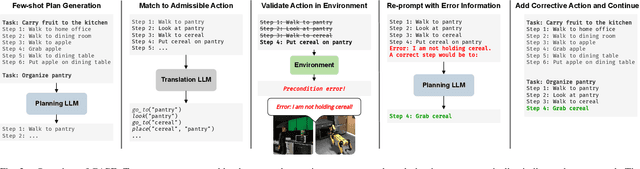
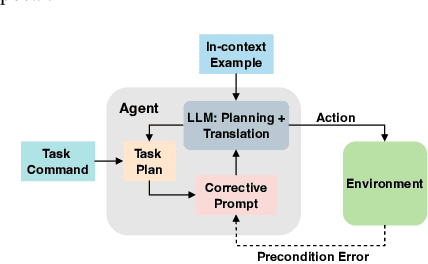
Extracting the common sense knowledge present in Large Language Models (LLMs) offers a path to designing intelligent, embodied agents. Related works have queried LLMs with a wide-range of contextual information, such as goals, sensor observations and scene descriptions, to generate high-level action plans for specific tasks; however these approaches often involve human intervention or additional machinery to enable sensor-motor interactions. In this work, we propose a prompting-based strategy for extracting executable plans from an LLM, which leverages a novel and readily-accessible source of information: precondition errors. Our approach assumes that actions are only afforded execution in certain contexts, i.e., implicit preconditions must be met for an action to execute (e.g., a door must be unlocked to open it), and that the embodied agent has the ability to determine if the action is/is not executable in the current context (e.g., detect if a precondition error is present). When an agent is unable to execute an action, our approach re-prompts the LLM with precondition error information to extract an executable corrective action to achieve the intended goal in the current context. We evaluate our approach in the VirtualHome simulation environment on 88 different tasks and 7 scenes. We evaluate different prompt templates and compare to methods that naively re-sample actions from the LLM. Our approach, using precondition errors, improves executability and semantic correctness of plans, while also reducing the number of re-prompts required when querying actions.
Where were my keys? -- Aggregating Spatial-Temporal Instances of Objects for Efficient Retrieval over Long Periods of Time
Oct 25, 2021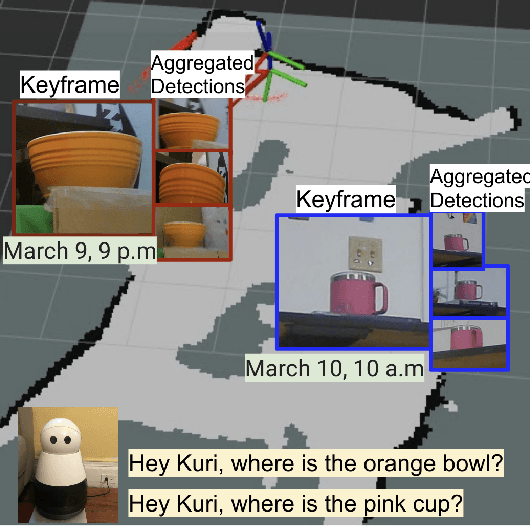

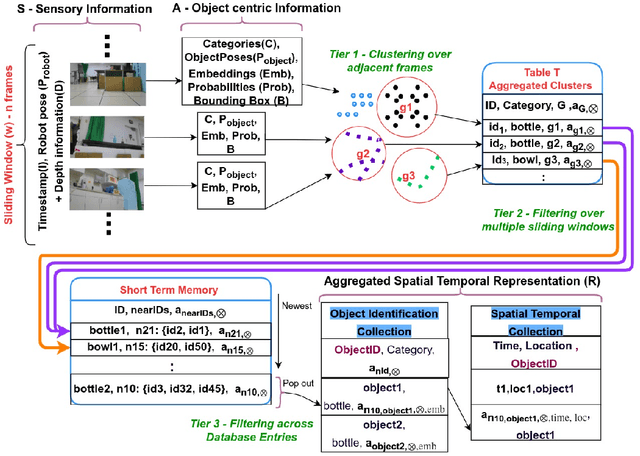
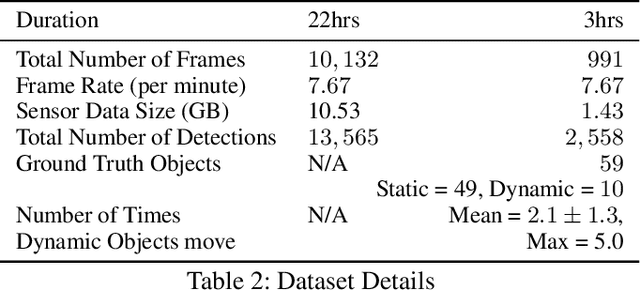
Robots equipped with situational awareness can help humans efficiently find their lost objects by leveraging spatial and temporal structure. Existing approaches to video and image retrieval do not take into account the unique constraints imposed by a moving camera with a partial view of the environment. We present a Detection-based 3-level hierarchical Association approach, D3A, to create an efficient query-able spatial-temporal representation of unique object instances in an environment. D3A performs online incremental and hierarchical learning to identify keyframes that best represent the unique objects in the environment. These keyframes are learned based on both spatial and temporal features and once identified their corresponding spatial-temporal information is organized in a key-value database. D3A allows for a variety of query patterns such as querying for objects with/without the following: 1) specific attributes, 2) spatial relationships with other objects, and 3) time slices. For a given set of 150 queries, D3A returns a small set of candidate keyframes (which occupy only 0.17% of the total sensory data) with 81.98\% mean accuracy in 11.7 ms. This is 47x faster and 33% more accurate than a baseline that naively stores the object matches (detections) in the database without associating spatial-temporal information.
RoboMem: Giving Long Term Memory to Robots
Mar 23, 2020
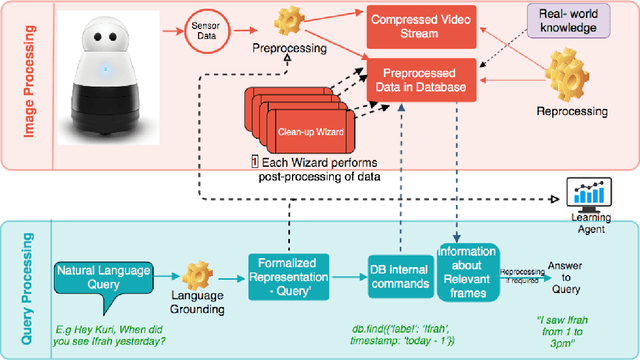

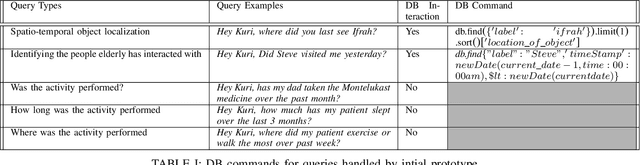
Robots have the potential to improve health monitoring outcomes for the elderly by providing doctors, and caregivers with information about the person's behavior, health activities and their surrounding environment. Over the years, less work has been done to enable robots to preserve information for longer periods of time, on the order of months and years of data, and use this contextual information to answer queries. Time complexity to process this massive sensor data in a timely fashion, inability to anticipate the future queries in advance and imprecision involved in the results have been the main impediments in making progress in this area. We make a contribution by introducing RoboMem, a query answering system for health-care assistance of elderly over long term; continuous data feeds that intends to overcome the challenges of giving long term memory to robots. The design for our framework preprocesses the sensor data and stores this preprocessed data into the database. This data is updated in the database by going through successive refinements, improving its accuracy for responding to queries. If data in the database is not enough to answer a query, a small set of relevant frames (also obtained from the database) will be reprocessed to obtain the answer. [Our initial prototype of RoboMem stores 3.5MB of data in the database as compared to 535.8MB of actual video frames and with minimal data in the database it is able to fetch information fundamental to respond to queries in 0.0002 seconds on average].