 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere were my keys? -- Aggregating Spatial-Temporal Instances of Objects for Efficient Retrieval over Long Periods of Time
Paper and Code
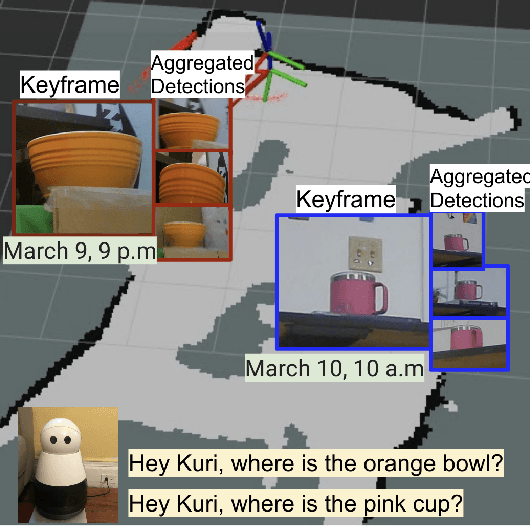

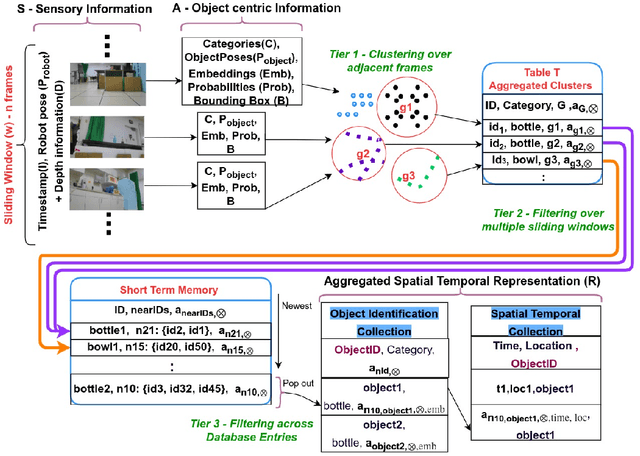
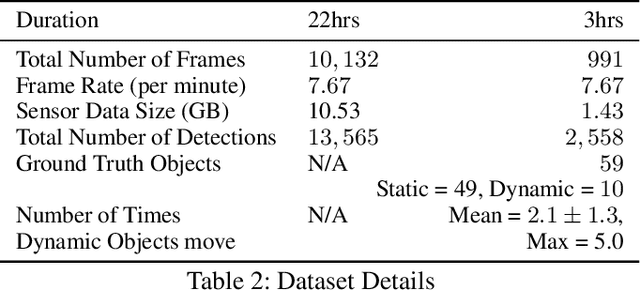
Robots equipped with situational awareness can help humans efficiently find their lost objects by leveraging spatial and temporal structure. Existing approaches to video and image retrieval do not take into account the unique constraints imposed by a moving camera with a partial view of the environment. We present a Detection-based 3-level hierarchical Association approach, D3A, to create an efficient query-able spatial-temporal representation of unique object instances in an environment. D3A performs online incremental and hierarchical learning to identify keyframes that best represent the unique objects in the environment. These keyframes are learned based on both spatial and temporal features and once identified their corresponding spatial-temporal information is organized in a key-value database. D3A allows for a variety of query patterns such as querying for objects with/without the following: 1) specific attributes, 2) spatial relationships with other objects, and 3) time slices. For a given set of 150 queries, D3A returns a small set of candidate keyframes (which occupy only 0.17% of the total sensory data) with 81.98\% mean accuracy in 11.7 ms. This is 47x faster and 33% more accurate than a baseline that naively stores the object matches (detections) in the database without associating spatial-temporal information.