 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere were my keys? -- Aggregating Spatial-Temporal Instances of Objects for Efficient Retrieval over Long Periods of Time
Oct 25, 2021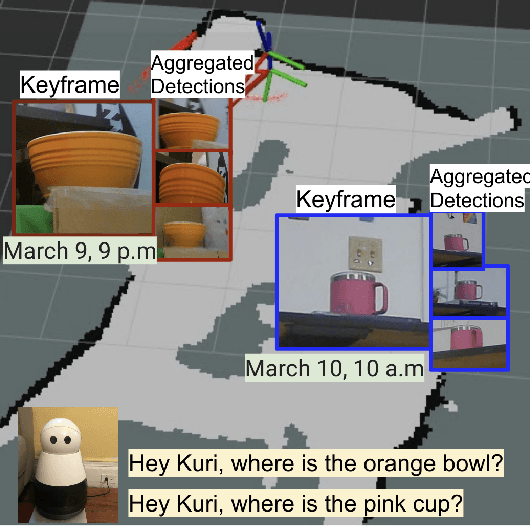

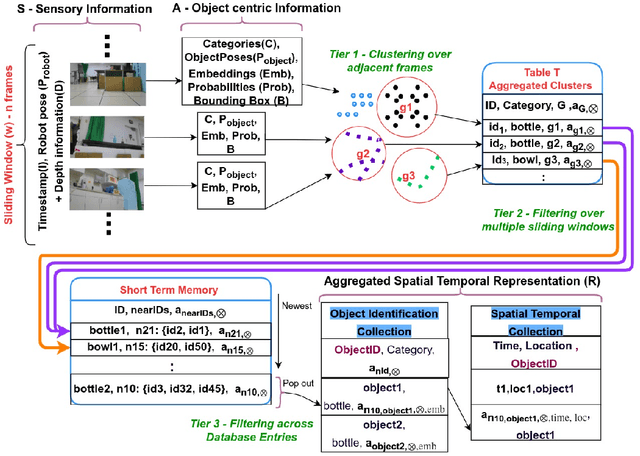
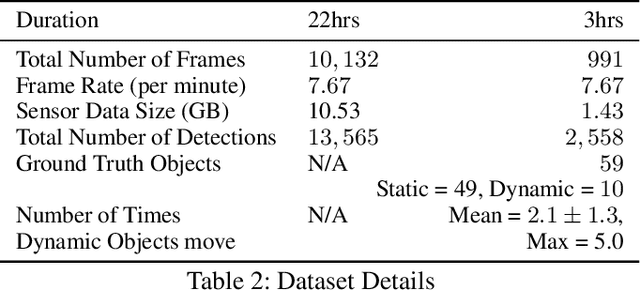
Robots equipped with situational awareness can help humans efficiently find their lost objects by leveraging spatial and temporal structure. Existing approaches to video and image retrieval do not take into account the unique constraints imposed by a moving camera with a partial view of the environment. We present a Detection-based 3-level hierarchical Association approach, D3A, to create an efficient query-able spatial-temporal representation of unique object instances in an environment. D3A performs online incremental and hierarchical learning to identify keyframes that best represent the unique objects in the environment. These keyframes are learned based on both spatial and temporal features and once identified their corresponding spatial-temporal information is organized in a key-value database. D3A allows for a variety of query patterns such as querying for objects with/without the following: 1) specific attributes, 2) spatial relationships with other objects, and 3) time slices. For a given set of 150 queries, D3A returns a small set of candidate keyframes (which occupy only 0.17% of the total sensory data) with 81.98\% mean accuracy in 11.7 ms. This is 47x faster and 33% more accurate than a baseline that naively stores the object matches (detections) in the database without associating spatial-temporal information.
RoboMem: Giving Long Term Memory to Robots
Mar 23, 2020
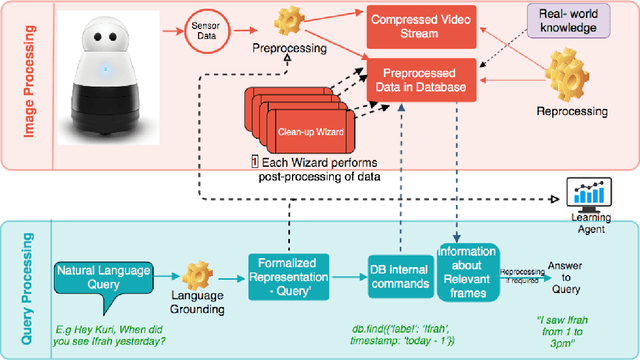

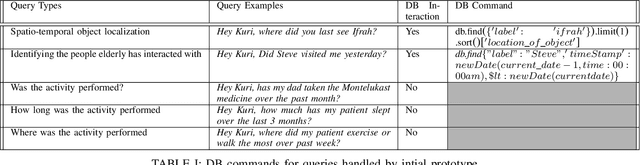
Robots have the potential to improve health monitoring outcomes for the elderly by providing doctors, and caregivers with information about the person's behavior, health activities and their surrounding environment. Over the years, less work has been done to enable robots to preserve information for longer periods of time, on the order of months and years of data, and use this contextual information to answer queries. Time complexity to process this massive sensor data in a timely fashion, inability to anticipate the future queries in advance and imprecision involved in the results have been the main impediments in making progress in this area. We make a contribution by introducing RoboMem, a query answering system for health-care assistance of elderly over long term; continuous data feeds that intends to overcome the challenges of giving long term memory to robots. The design for our framework preprocesses the sensor data and stores this preprocessed data into the database. This data is updated in the database by going through successive refinements, improving its accuracy for responding to queries. If data in the database is not enough to answer a query, a small set of relevant frames (also obtained from the database) will be reprocessed to obtain the answer. [Our initial prototype of RoboMem stores 3.5MB of data in the database as compared to 535.8MB of actual video frames and with minimal data in the database it is able to fetch information fundamental to respond to queries in 0.0002 seconds on average].