 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAM-Seg: A Continuous-valued Embedding Approach for Semantic Image Generation
Mar 19, 2025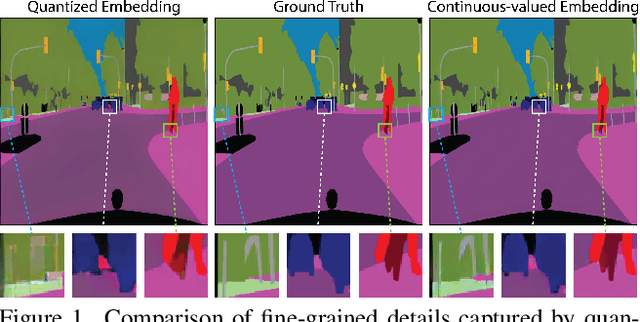
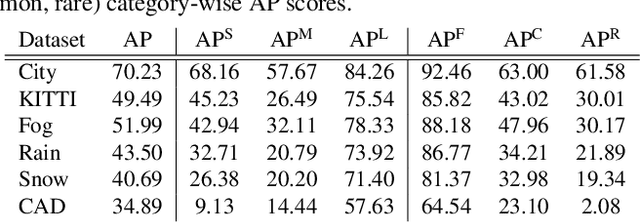
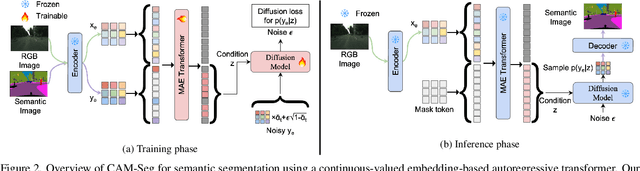
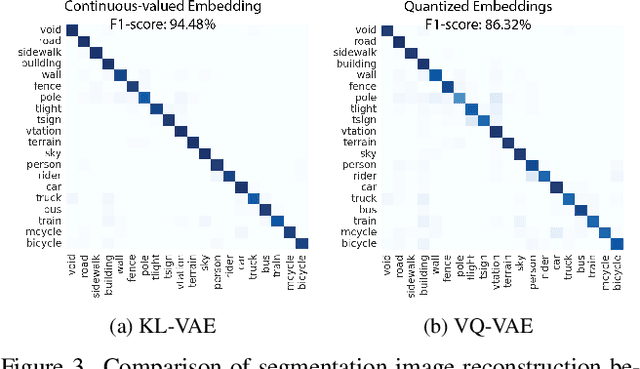
Traditional transformer-based semantic segmentation relies on quantized embeddings. However, our analysis reveals that autoencoder accuracy on segmentation mask using quantized embeddings (e.g. VQ-VAE) is 8% lower than continuous-valued embeddings (e.g. KL-VAE). Motivated by this, we propose a continuous-valued embedding framework for semantic segmentation. By reformulating semantic mask generation as a continuous image-to-embedding diffusion process, our approach eliminates the need for discrete latent representations while preserving fine-grained spatial and semantic details. Our key contribution includes a diffusion-guided autoregressive transformer that learns a continuous semantic embedding space by modeling long-range dependencies in image features. Our framework contains a unified architecture combining a VAE encoder for continuous feature extraction, a diffusion-guided transformer for conditioned embedding generation, and a VAE decoder for semantic mask reconstruction. Our setting facilitates zero-shot domain adaptation capabilities enabled by the continuity of the embedding space. Experiments across diverse datasets (e.g., Cityscapes and domain-shifted variants) demonstrate state-of-the-art robustness to distribution shifts, including adverse weather (e.g., fog, snow) and viewpoint variations. Our model also exhibits strong noise resilience, achieving robust performance ($\approx$ 95% AP compared to baseline) under gaussian noise, moderate motion blur, and moderate brightness/contrast variations, while experiencing only a moderate impact ($\approx$ 90% AP compared to baseline) from 50% salt and pepper noise, saturation and hue shifts. Code available: https://github.com/mahmed10/CAMSS.git
A Paradigm Shift in Mouza Map Vectorization: A Human-Machine Collaboration Approach
Oct 21, 2024Efficient vectorization of hand-drawn cadastral maps, such as Mouza maps in Bangladesh, poses a significant challenge due to their complex structures. Current manual digitization methods are time-consuming and labor-intensive. Our study proposes a semi-automated approach to streamline the digitization process, saving both time and human resources. Our methodology focuses on separating the plot boundaries and plot identifiers and applying our digitization methodology to convert both of them into vectorized format. To accomplish full vectorization, Convolutional Neural Network (CNN) models are utilized for pre-processing and plot number detection along with our smoothing algorithms based on the diversity of vector maps. The CNN models are trained with our own labeled dataset, generated from the maps, and smoothing algorithms are introduced from the various observations of the map's vector formats. Further human intervention remains essential for precision. We have evaluated our methods on several maps and provided both quantitative and qualitative results with user study. The result demonstrates that our methodology outperforms the existing map digitization processes significantly.
Novel Categories Discovery from probability matrix perspective
Jul 07, 2023Novel Categories Discovery (NCD) tackles the open-world problem of classifying known and clustering novel categories based on the class semantics using partial class space annotated data. Unlike traditional pseudo-label and retraining, we investigate NCD from the novel data probability matrix perspective. We leverage the connection between NCD novel data sampling with provided novel class Multinoulli (categorical) distribution and hypothesize to implicitly achieve semantic-based novel data clustering by learning their class distribution. We propose novel constraints on first-order (mean) and second-order (covariance) statistics of probability matrix features while applying instance-wise information constraints. In particular, we align the neuron distribution (activation patterns) under a large batch of Monte-Carlo novel data sampling by matching their empirical features mean and covariance with the provided Multinoulli-distribution. Simultaneously, we minimize entropy and enforce prediction consistency for each instance. Our simple approach successfully realizes semantic-based novel data clustering provided the semantic similarity between label-unlabeled classes. We demonstrate the discriminative capacity of our approaches in image and video modalities. Moreover, we perform extensive ablation studies regarding data, networks, and our framework components to provide better insights. Our approach maintains ~94%, ~93%, and ~85%, classification accuracy in labeled data while achieving ~90%, ~84%, and ~72% clustering accuracy for novel categories for Cifar10, UCF101, and MPSC-ARL datasets that matches state-of-the-art approaches without any external clustering.
A Systematic Study on Object Recognition Using Millimeter-wave Radar
May 03, 2023



Due to its light and weather-independent sensing, millimeter-wave (MMW) radar is essential in smart environments. Intelligent vehicle systems and industry-grade MMW radars have integrated such capabilities. Industry-grade MMW radars are expensive and hard to get for community-purpose smart environment applications. However, commercially available MMW radars have hidden underpinning challenges that need to be investigated for tasks like recognizing objects and activities, real-time person tracking, object localization, etc. Image and video data are straightforward to gather, understand, and annotate for such jobs. Image and video data are light and weather-dependent, susceptible to the occlusion effect, and present privacy problems. To eliminate dependence and ensure privacy, commercial MMW radars should be tested. MMW radar's practicality and performance in varied operating settings must be addressed before promoting it. To address the problems, we collected a dataset using Texas Instruments' Automotive mmWave Radar (AWR2944) and reported the best experimental settings for object recognition performance using different deep learning algorithms. Our extensive data gathering technique allows us to systematically explore and identify object identification task problems under cross-ambience conditions. We investigated several solutions and published detailed experimental data.
NEV-NCD: Negative Learning, Entropy, and Variance regularization based novel action categories discovery
Apr 14, 2023



Novel Categories Discovery (NCD) facilitates learning from a partially annotated label space and enables deep learning (DL) models to operate in an open-world setting by identifying and differentiating instances of novel classes based on the labeled data notions. One of the primary assumptions of NCD is that the novel label space is perfectly disjoint and can be equipartitioned, but it is rarely realized by most NCD approaches in practice. To better align with this assumption, we propose a novel single-stage joint optimization-based NCD method, Negative learning, Entropy, and Variance regularization NCD (NEV-NCD). We demonstrate the efficacy of NEV-NCD in previously unexplored NCD applications of video action recognition (VAR) with the public UCF101 dataset and a curated in-house partial action-space annotated multi-view video dataset. We perform a thorough ablation study by varying the composition of final joint loss and associated hyper-parameters. During our experiments with UCF101 and multi-view action dataset, NEV-NCD achieves ~ 83% classification accuracy in test instances of labeled data. NEV-NCD achieves ~ 70% clustering accuracy over unlabeled data outperforming both naive baselines (by ~ 40%) and state-of-the-art pseudo-labeling-based approaches (by ~ 3.5%) over both datasets. Further, we propose to incorporate optional view-invariant feature learning with the multiview dataset to identify novel categories from novel viewpoints. Our additional view-invariance constraint improves the discriminative accuracy for both known and unknown categories by ~ 10% for novel viewpoints.
Demo: RhythmEdge: Enabling Contactless Heart Rate Estimation on the Edge
Aug 13, 2022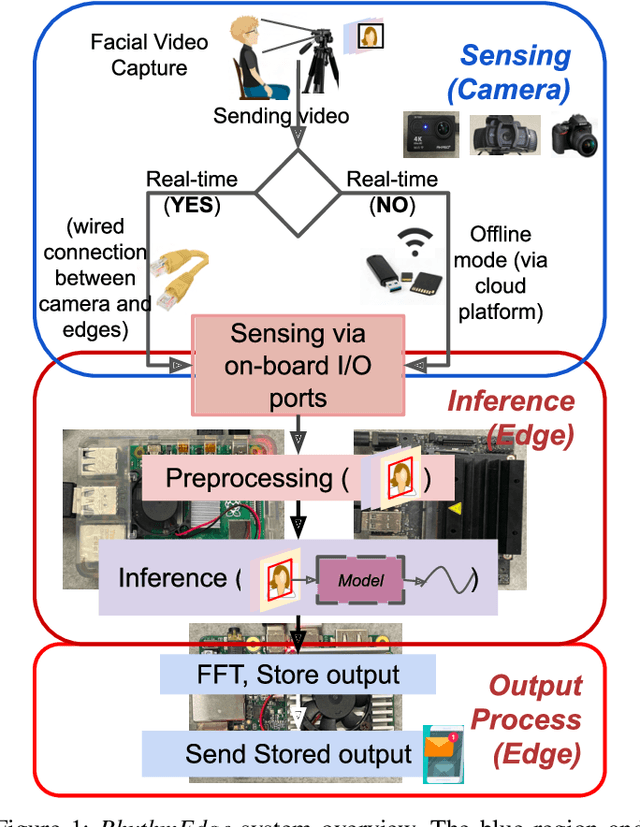

In this demo paper, we design and prototype RhythmEdge, a low-cost, deep-learning-based contact-less system for regular HR monitoring applications. RhythmEdge benefits over existing approaches by facilitating contact-less nature, real-time/offline operation, inexpensive and available sensing components, and computing devices. Our RhythmEdge system is portable and easily deployable for reliable HR estimation in moderately controlled indoor or outdoor environments. RhythmEdge measures HR via detecting changes in blood volume from facial videos (Remote Photoplethysmography; rPPG) and provides instant assessment using off-the-shelf commercially available resource-constrained edge platforms and video cameras. We demonstrate the scalability, flexibility, and compatibility of the RhythmEdge by deploying it on three resource-constrained platforms of differing architectures (NVIDIA Jetson Nano, Google Coral Development Board, Raspberry Pi) and three heterogeneous cameras of differing sensitivity, resolution, properties (web camera, action camera, and DSLR). RhythmEdge further stores longitudinal cardiovascular information and provides instant notification to the users. We thoroughly test the prototype stability, latency, and feasibility for three edge computing platforms by profiling their runtime, memory, and power usage.
Autonomous Warehouse Robot using Deep Q-Learning
Feb 21, 2022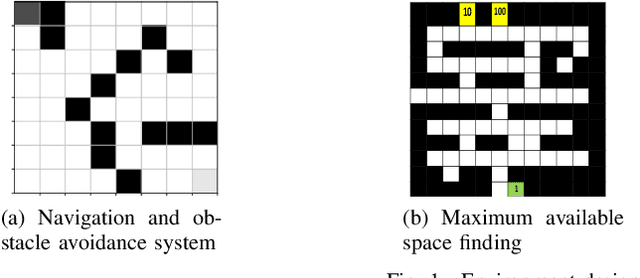
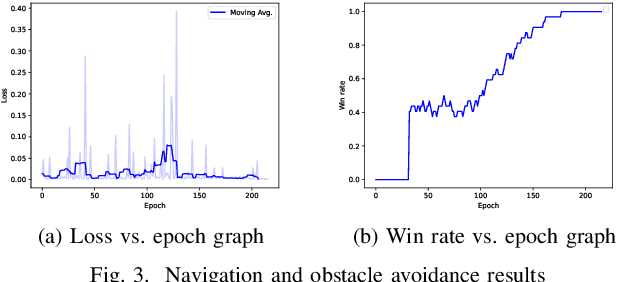
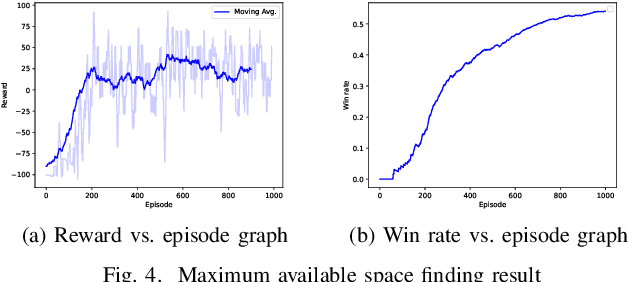
In warehouses, specialized agents need to navigate, avoid obstacles and maximize the use of space in the warehouse environment. Due to the unpredictability of these environments, reinforcement learning approaches can be applied to complete these tasks. In this paper, we propose using Deep Reinforcement Learning (DRL) to address the robot navigation and obstacle avoidance problem and traditional Q-learning with minor variations to maximize the use of space for product placement. We first investigate the problem for the single robot case. Next, based on the single robot model, we extend our system to the multi-robot case. We use a strategic variation of Q-tables to perform multi-agent Q-learning. We successfully test the performance of our model in a 2D simulation environment for both the single and multi-robot cases.
Where were my keys? -- Aggregating Spatial-Temporal Instances of Objects for Efficient Retrieval over Long Periods of Time
Oct 25, 2021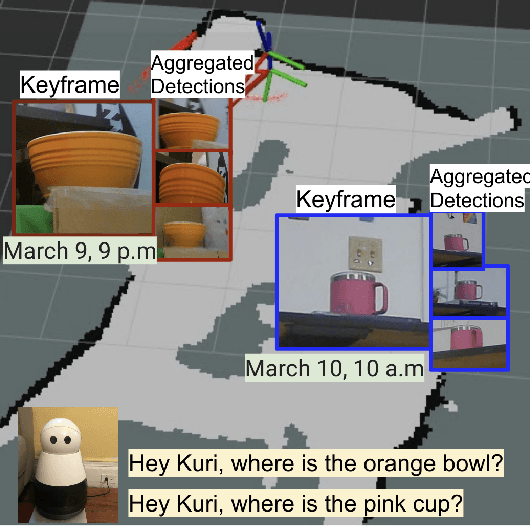

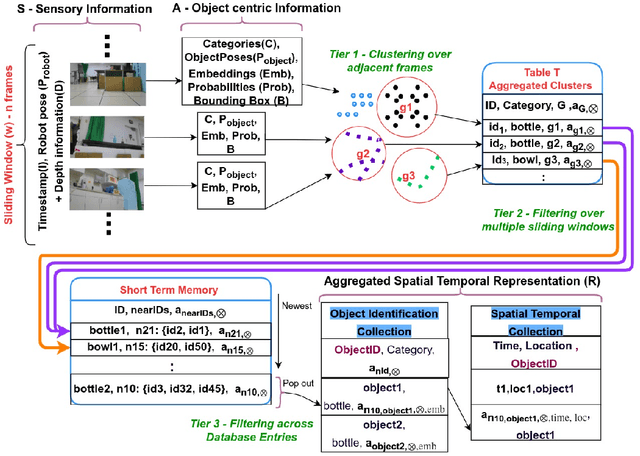
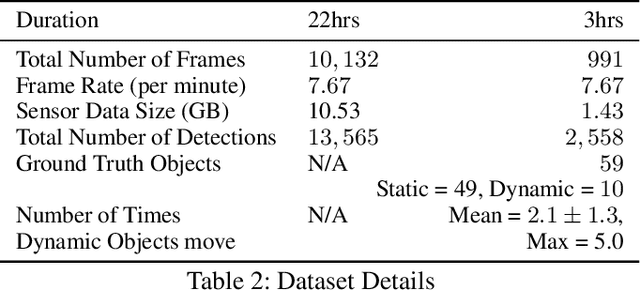
Robots equipped with situational awareness can help humans efficiently find their lost objects by leveraging spatial and temporal structure. Existing approaches to video and image retrieval do not take into account the unique constraints imposed by a moving camera with a partial view of the environment. We present a Detection-based 3-level hierarchical Association approach, D3A, to create an efficient query-able spatial-temporal representation of unique object instances in an environment. D3A performs online incremental and hierarchical learning to identify keyframes that best represent the unique objects in the environment. These keyframes are learned based on both spatial and temporal features and once identified their corresponding spatial-temporal information is organized in a key-value database. D3A allows for a variety of query patterns such as querying for objects with/without the following: 1) specific attributes, 2) spatial relationships with other objects, and 3) time slices. For a given set of 150 queries, D3A returns a small set of candidate keyframes (which occupy only 0.17% of the total sensory data) with 81.98\% mean accuracy in 11.7 ms. This is 47x faster and 33% more accurate than a baseline that naively stores the object matches (detections) in the database without associating spatial-temporal information.