 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAM-Seg: A Continuous-valued Embedding Approach for Semantic Image Generation
Mar 19, 2025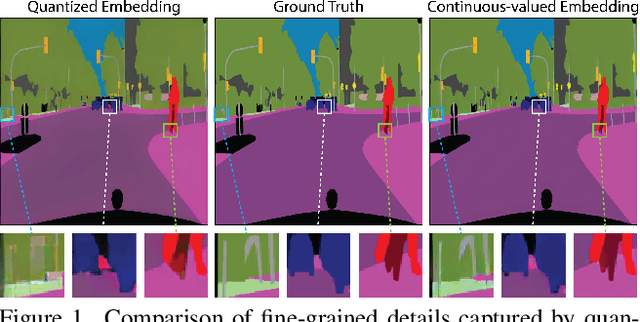
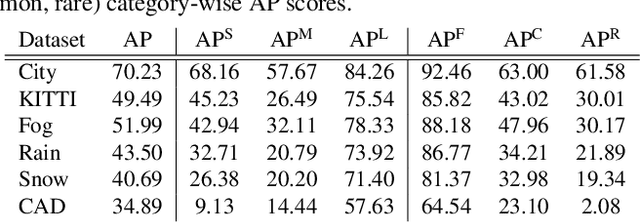
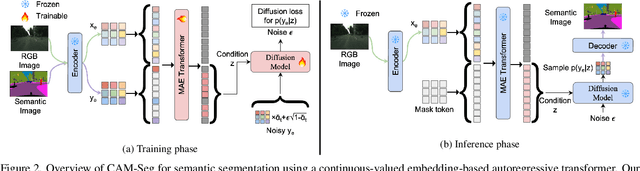
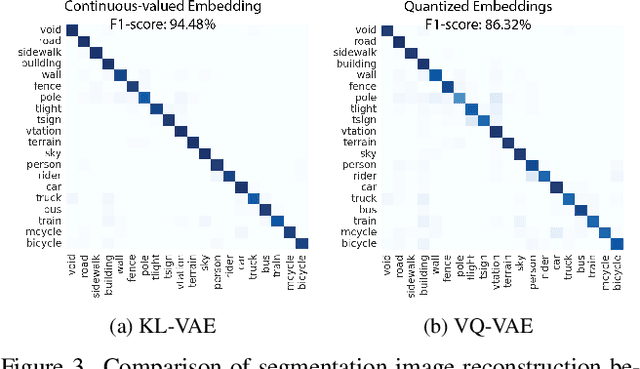
Traditional transformer-based semantic segmentation relies on quantized embeddings. However, our analysis reveals that autoencoder accuracy on segmentation mask using quantized embeddings (e.g. VQ-VAE) is 8% lower than continuous-valued embeddings (e.g. KL-VAE). Motivated by this, we propose a continuous-valued embedding framework for semantic segmentation. By reformulating semantic mask generation as a continuous image-to-embedding diffusion process, our approach eliminates the need for discrete latent representations while preserving fine-grained spatial and semantic details. Our key contribution includes a diffusion-guided autoregressive transformer that learns a continuous semantic embedding space by modeling long-range dependencies in image features. Our framework contains a unified architecture combining a VAE encoder for continuous feature extraction, a diffusion-guided transformer for conditioned embedding generation, and a VAE decoder for semantic mask reconstruction. Our setting facilitates zero-shot domain adaptation capabilities enabled by the continuity of the embedding space. Experiments across diverse datasets (e.g., Cityscapes and domain-shifted variants) demonstrate state-of-the-art robustness to distribution shifts, including adverse weather (e.g., fog, snow) and viewpoint variations. Our model also exhibits strong noise resilience, achieving robust performance ($\approx$ 95% AP compared to baseline) under gaussian noise, moderate motion blur, and moderate brightness/contrast variations, while experiencing only a moderate impact ($\approx$ 90% AP compared to baseline) from 50% salt and pepper noise, saturation and hue shifts. Code available: https://github.com/mahmed10/CAMSS.git
Unsupervised Domain Adaptation for Action Recognition via Self-Ensembling and Conditional Embedding Alignment
Oct 23, 2024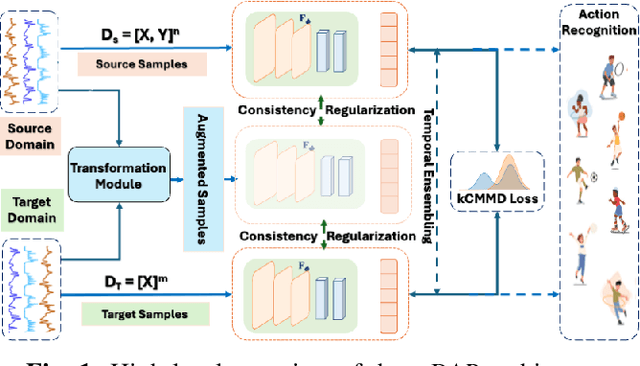

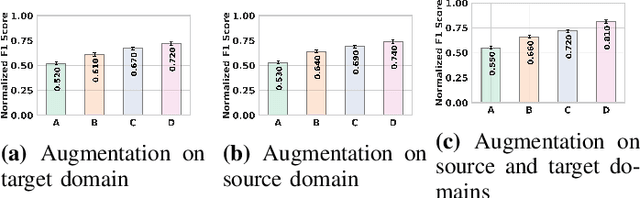
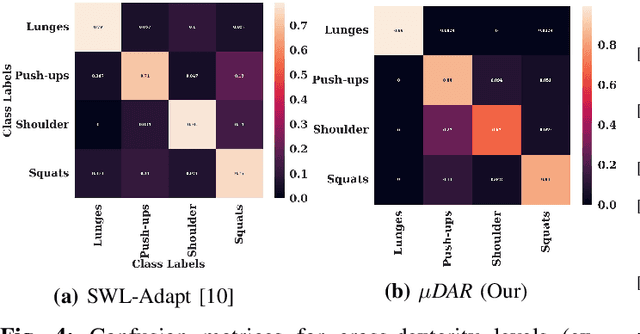
Recent advancements in deep learning-based wearable human action recognition (wHAR) have improved the capture and classification of complex motions, but adoption remains limited due to the lack of expert annotations and domain discrepancies from user variations. Limited annotations hinder the model's ability to generalize to out-of-distribution samples. While data augmentation can improve generalizability, unsupervised augmentation techniques must be applied carefully to avoid introducing noise. Unsupervised domain adaptation (UDA) addresses domain discrepancies by aligning conditional distributions with labeled target samples, but vanilla pseudo-labeling can lead to error propagation. To address these challenges, we propose $\mu$DAR, a novel joint optimization architecture comprised of three functions: (i) consistency regularizer between augmented samples to improve model classification generalizability, (ii) temporal ensemble for robust pseudo-label generation and (iii) conditional distribution alignment to improve domain generalizability. The temporal ensemble works by aggregating predictions from past epochs to smooth out noisy pseudo-label predictions, which are then used in the conditional distribution alignment module to minimize kernel-based class-wise conditional maximum mean discrepancy ($k$CMMD) between the source and target feature space to learn a domain invariant embedding. The consistency-regularized augmentations ensure that multiple augmentations of the same sample share the same labels; this results in (a) strong generalization with limited source domain samples and (b) consistent pseudo-label generation in target samples. The novel integration of these three modules in $\mu$DAR results in a range of $\approx$ 4-12% average macro-F1 score improvement over six state-of-the-art UDA methods in four benchmark wHAR datasets
Novel Categories Discovery from probability matrix perspective
Jul 07, 2023Novel Categories Discovery (NCD) tackles the open-world problem of classifying known and clustering novel categories based on the class semantics using partial class space annotated data. Unlike traditional pseudo-label and retraining, we investigate NCD from the novel data probability matrix perspective. We leverage the connection between NCD novel data sampling with provided novel class Multinoulli (categorical) distribution and hypothesize to implicitly achieve semantic-based novel data clustering by learning their class distribution. We propose novel constraints on first-order (mean) and second-order (covariance) statistics of probability matrix features while applying instance-wise information constraints. In particular, we align the neuron distribution (activation patterns) under a large batch of Monte-Carlo novel data sampling by matching their empirical features mean and covariance with the provided Multinoulli-distribution. Simultaneously, we minimize entropy and enforce prediction consistency for each instance. Our simple approach successfully realizes semantic-based novel data clustering provided the semantic similarity between label-unlabeled classes. We demonstrate the discriminative capacity of our approaches in image and video modalities. Moreover, we perform extensive ablation studies regarding data, networks, and our framework components to provide better insights. Our approach maintains ~94%, ~93%, and ~85%, classification accuracy in labeled data while achieving ~90%, ~84%, and ~72% clustering accuracy for novel categories for Cifar10, UCF101, and MPSC-ARL datasets that matches state-of-the-art approaches without any external clustering.
NEV-NCD: Negative Learning, Entropy, and Variance regularization based novel action categories discovery
Apr 14, 2023



Novel Categories Discovery (NCD) facilitates learning from a partially annotated label space and enables deep learning (DL) models to operate in an open-world setting by identifying and differentiating instances of novel classes based on the labeled data notions. One of the primary assumptions of NCD is that the novel label space is perfectly disjoint and can be equipartitioned, but it is rarely realized by most NCD approaches in practice. To better align with this assumption, we propose a novel single-stage joint optimization-based NCD method, Negative learning, Entropy, and Variance regularization NCD (NEV-NCD). We demonstrate the efficacy of NEV-NCD in previously unexplored NCD applications of video action recognition (VAR) with the public UCF101 dataset and a curated in-house partial action-space annotated multi-view video dataset. We perform a thorough ablation study by varying the composition of final joint loss and associated hyper-parameters. During our experiments with UCF101 and multi-view action dataset, NEV-NCD achieves ~ 83% classification accuracy in test instances of labeled data. NEV-NCD achieves ~ 70% clustering accuracy over unlabeled data outperforming both naive baselines (by ~ 40%) and state-of-the-art pseudo-labeling-based approaches (by ~ 3.5%) over both datasets. Further, we propose to incorporate optional view-invariant feature learning with the multiview dataset to identify novel categories from novel viewpoints. Our additional view-invariance constraint improves the discriminative accuracy for both known and unknown categories by ~ 10% for novel viewpoints.
Domain Adaptation for Inertial Measurement Unit-based Human Activity Recognition: A Survey
Apr 07, 2023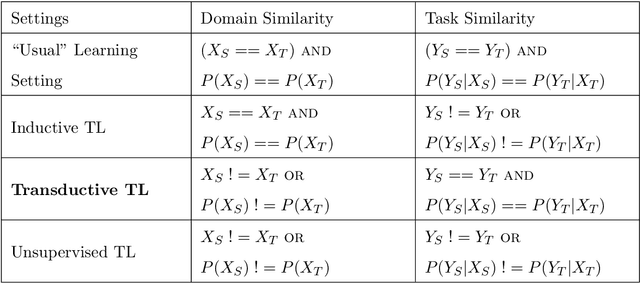
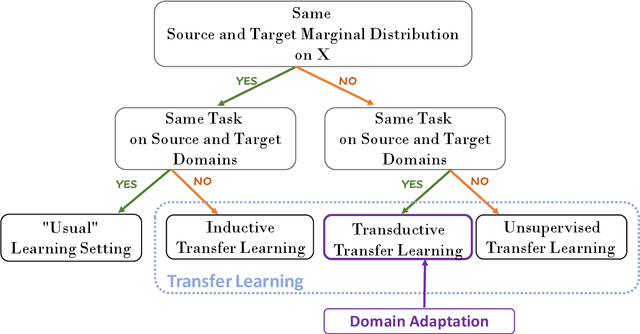
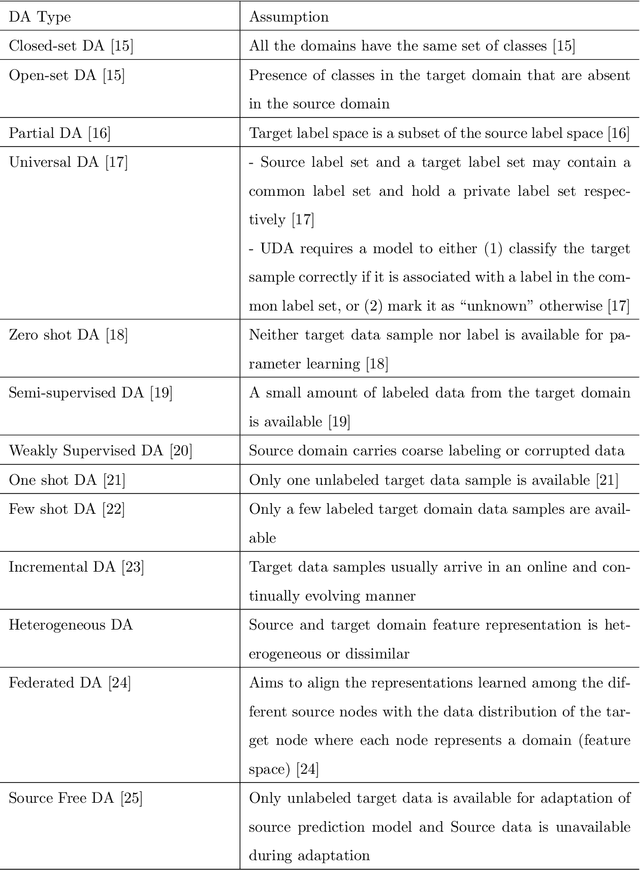
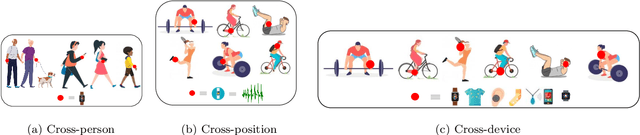
Machine learning-based wearable human activity recognition (WHAR) models enable the development of various smart and connected community applications such as sleep pattern monitoring, medication reminders, cognitive health assessment, sports analytics, etc. However, the widespread adoption of these WHAR models is impeded by their degraded performance in the presence of data distribution heterogeneities caused by the sensor placement at different body positions, inherent biases and heterogeneities across devices, and personal and environmental diversities. Various traditional machine learning algorithms and transfer learning techniques have been proposed in the literature to address the underpinning challenges of handling such data heterogeneities. Domain adaptation is one such transfer learning techniques that has gained significant popularity in recent literature. In this paper, we survey the recent progress of domain adaptation techniques in the Inertial Measurement Unit (IMU)-based human activity recognition area, discuss potential future directions.
Predicting score distribution to improve non-intrusive speech quality estimation
Apr 13, 2022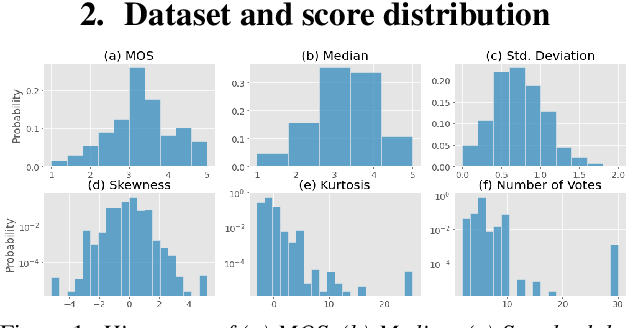
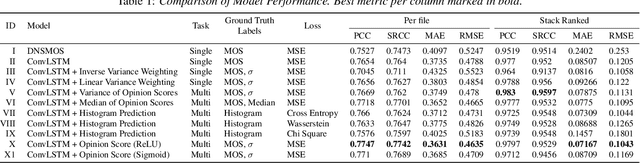
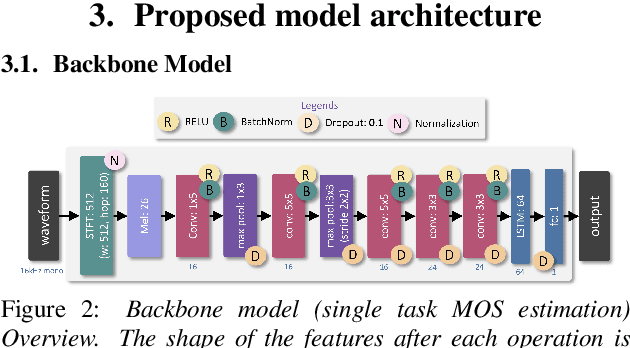
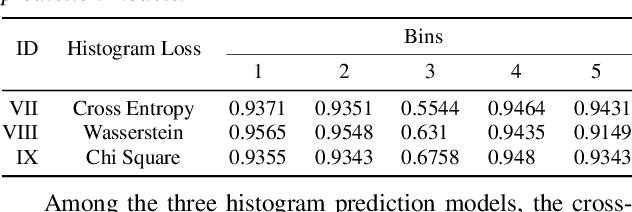
Deep noise suppressors (DNS) have become an attractive solution to remove background noise, reverberation, and distortions from speech and are widely used in telephony/voice applications. They are also occasionally prone to introducing artifacts and lowering the perceptual quality of the speech. Subjective listening tests that use multiple human judges to derive a mean opinion score (MOS) are a popular way to measure these models' performance. Deep neural network based non-intrusive MOS estimation models have recently emerged as a popular cost-efficient alternative to these tests. These models are trained with only the MOS labels, often discarding the secondary statistics of the opinion scores. In this paper, we investigate several ways to integrate the distribution of opinion scores (e.g. variance, histogram information) to improve the MOS estimation performance. Our model is trained on a corpus of 419K denoised samples by 320 different DNS models and model variations and evaluated on 18K test samples from DNSMOS. We show that with very minor modification of a single task MOS estimation pipeline, these freely available labels can provide up to a 0.016 RMSE and 1% SRCC improvement.