 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting score distribution to improve non-intrusive speech quality estimation
Paper and Code
Apr 13, 2022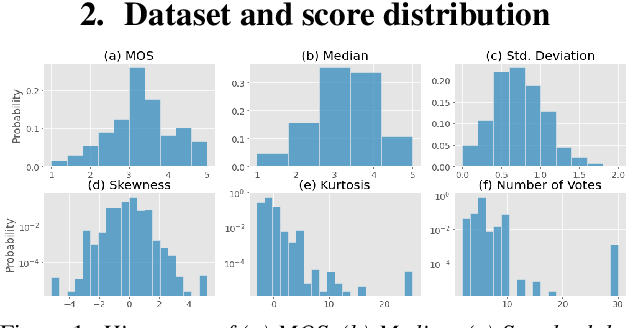
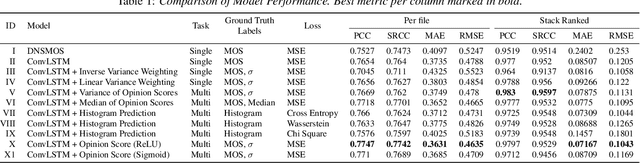
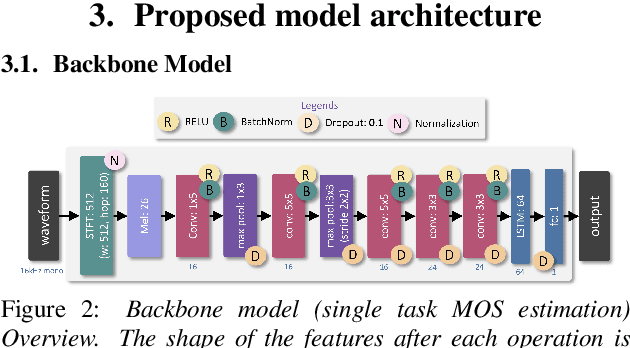
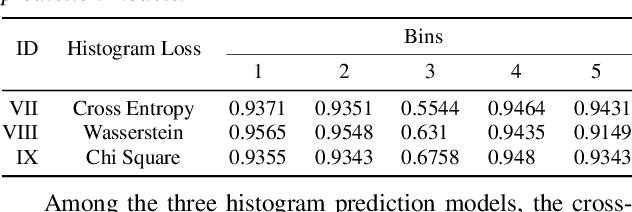
Deep noise suppressors (DNS) have become an attractive solution to remove background noise, reverberation, and distortions from speech and are widely used in telephony/voice applications. They are also occasionally prone to introducing artifacts and lowering the perceptual quality of the speech. Subjective listening tests that use multiple human judges to derive a mean opinion score (MOS) are a popular way to measure these models' performance. Deep neural network based non-intrusive MOS estimation models have recently emerged as a popular cost-efficient alternative to these tests. These models are trained with only the MOS labels, often discarding the secondary statistics of the opinion scores. In this paper, we investigate several ways to integrate the distribution of opinion scores (e.g. variance, histogram information) to improve the MOS estimation performance. Our model is trained on a corpus of 419K denoised samples by 320 different DNS models and model variations and evaluated on 18K test samples from DNSMOS. We show that with very minor modification of a single task MOS estimation pipeline, these freely available labels can provide up to a 0.016 RMSE and 1% SRCC improvement.