 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Realistic Simulation of Daily Human Activity
Nov 26, 2023For social robots like Astro which interact with and adapt to the daily movements of users within the home, realistic simulation of human activity is needed for feature development and testing. This paper presents a framework for simulating daily human activity patterns in home environments at scale, supporting manual configurability of different personas or activity patterns, variation of activity timings, and testing on multiple home layouts. We introduce a method for specifying day-to-day variation in schedules and present a bidirectional constraint propagation algorithm for generating schedules from templates. We validate the expressive power of our framework through a use case scenario analysis and demonstrate that our method can be used to generate data closely resembling human behavior from three public datasets and a self-collected dataset. Our contribution supports systematic testing of social robot behaviors at scale, enables procedural generation of synthetic datasets of human movement in different households, and can help minimize bias in training data, leading to more robust and effective robots for home environments.
A Joint Model for Dropped Pronoun Recovery and Conversational Discourse Parsing in Chinese Conversational Speech
Jun 07, 2021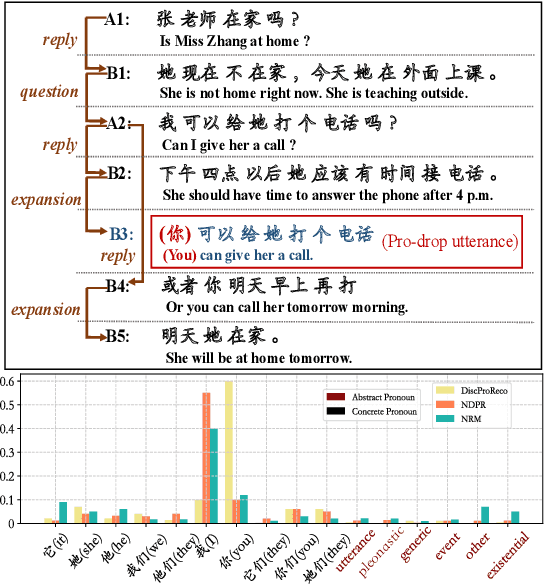
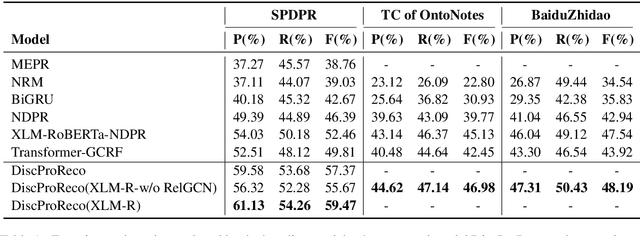
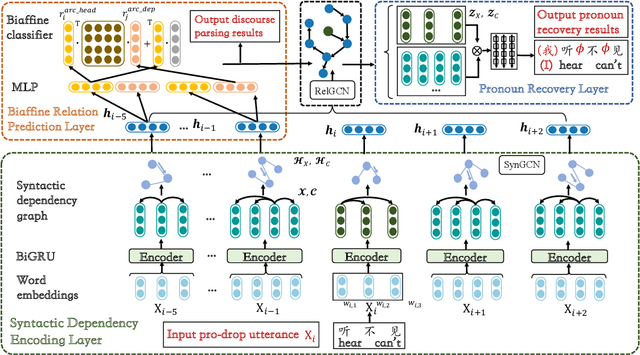
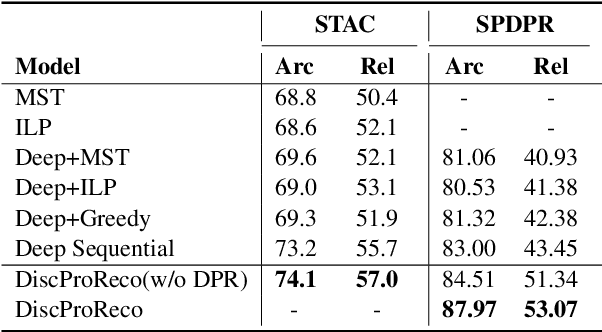
In this paper, we present a neural model for joint dropped pronoun recovery (DPR) and conversational discourse parsing (CDP) in Chinese conversational speech. We show that DPR and CDP are closely related, and a joint model benefits both tasks. We refer to our model as DiscProReco, and it first encodes the tokens in each utterance in a conversation with a directed Graph Convolutional Network (GCN). The token states for an utterance are then aggregated to produce a single state for each utterance. The utterance states are then fed into a biaffine classifier to construct a conversational discourse graph. A second (multi-relational) GCN is then applied to the utterance states to produce a discourse relation-augmented representation for the utterances, which are then fused together with token states in each utterance as input to a dropped pronoun recovery layer. The joint model is trained and evaluated on a new Structure Parsing-enhanced Dropped Pronoun Recovery (SPDPR) dataset that we annotated with both two types of information. Experimental results on the SPDPR dataset and other benchmarks show that DiscProReco significantly outperforms the state-of-the-art baselines of both tasks.
Transformer-GCRF: Recovering Chinese Dropped Pronouns with General Conditional Random Fields
Oct 07, 2020
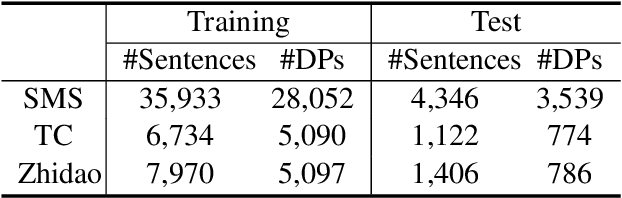
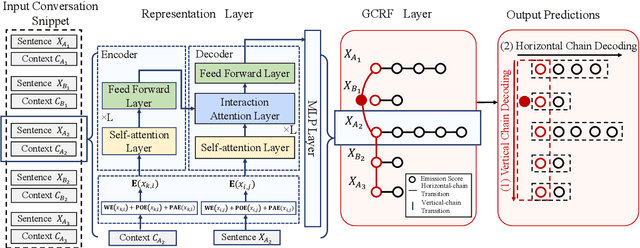
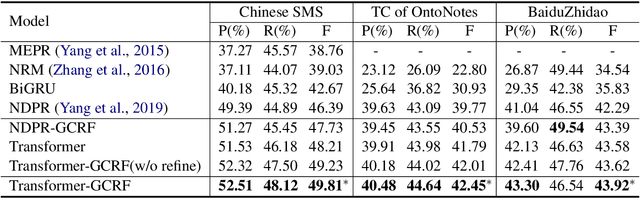
Pronouns are often dropped in Chinese conversations and recovering the dropped pronouns is important for NLP applications such as Machine Translation. Existing approaches usually formulate this as a sequence labeling task of predicting whether there is a dropped pronoun before each token and its type. Each utterance is considered to be a sequence and labeled independently. Although these approaches have shown promise, labeling each utterance independently ignores the dependencies between pronouns in neighboring utterances. Modeling these dependencies is critical to improving the performance of dropped pronoun recovery. In this paper, we present a novel framework that combines the strength of Transformer network with General Conditional Random Fields (GCRF) to model the dependencies between pronouns in neighboring utterances. Results on three Chinese conversation datasets show that the Transformer-GCRF model outperforms the state-of-the-art dropped pronoun recovery models. Exploratory analysis also demonstrates that the GCRF did help to capture the dependencies between pronouns in neighboring utterances, thus contributes to the performance improvements.