 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Strengths and Weaknesses of Data for Open-set Embodied Assistance
Mar 05, 2026Embodied foundation models are increasingly performant in real-world domains such as robotics or autonomous driving. These models are often deployed in interactive or assistive settings, where it is important that these assistive models generalize to new users and new tasks. Diverse interactive data generation offers a promising avenue for providing data-efficient generalization capabilities for interactive embodied foundation models. In this paper, we investigate the generalization capabilities of a multimodal foundation model fine-tuned on diverse interactive assistance data in a synthetic domain. We explore generalization along two axes: a) assistance with unseen categories of user behavior and b) providing guidance in new configurations not encountered during training. We study a broad capability called \textbf{Open-Set Corrective Assistance}, in which the model needs to inspect lengthy user behavior and provide assistance through either corrective actions or language-based feedback. This task remains unsolved in prior work, which typically assumes closed corrective categories or relies on external planners, making it a challenging testbed for evaluating the limits of assistive data. To support this task, we generate synthetic assistive datasets in Overcooked and fine-tune a LLaMA-based model to evaluate generalization to novel tasks and user behaviors. Our approach provides key insights into the nature of assistive datasets required to enable open-set assistive intelligence. In particular, we show that performant models benefit from datasets that cover different aspects of assistance, including multimodal grounding, defect inference, and exposure to diverse scenarios.
Generating CAD Code with Vision-Language Models for 3D Designs
Oct 07, 2024



Generative AI has transformed the fields of Design and Manufacturing by providing efficient and automated methods for generating and modifying 3D objects. One approach involves using Large Language Models (LLMs) to generate Computer- Aided Design (CAD) scripting code, which can then be executed to render a 3D object; however, the resulting 3D object may not meet the specified requirements. Testing the correctness of CAD generated code is challenging due to the complexity and structure of 3D objects (e.g., shapes, surfaces, and dimensions) that are not feasible in code. In this paper, we introduce CADCodeVerify, a novel approach to iteratively verify and improve 3D objects generated from CAD code. Our approach works by producing ameliorative feedback by prompting a Vision-Language Model (VLM) to generate and answer a set of validation questions to verify the generated object and prompt the VLM to correct deviations. To evaluate CADCodeVerify, we introduce, CADPrompt, the first benchmark for CAD code generation, consisting of 200 natural language prompts paired with expert-annotated scripting code for 3D objects to benchmark progress. Our findings show that CADCodeVerify improves VLM performance by providing visual feedback, enhancing the structure of the 3D objects, and increasing the success rate of the compiled program. When applied to GPT-4, CADCodeVerify achieved a 7.30% reduction in Point Cloud distance and a 5.0% improvement in success rate compared to prior work
Towards the design of user-centric strategy recommendation systems for collaborative Human-AI tasks
Jan 17, 2023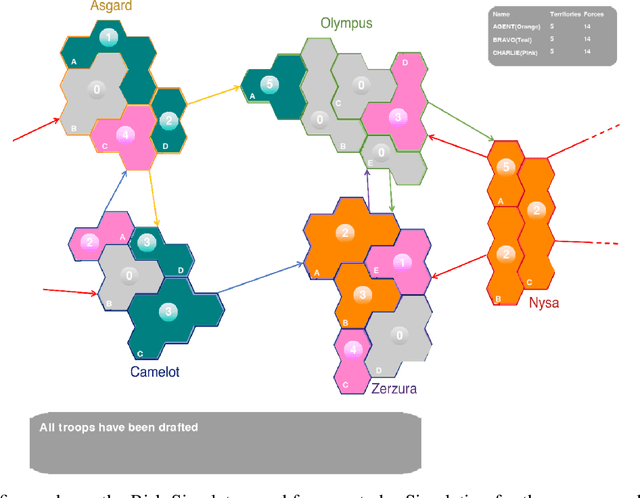

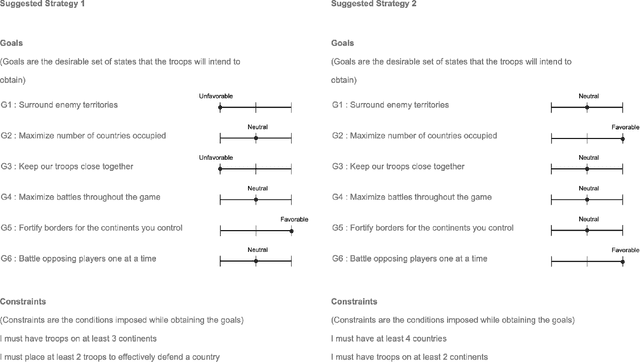
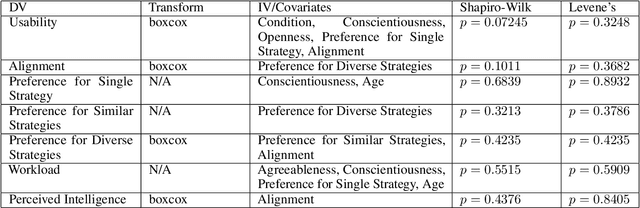
Artificial Intelligence is being employed by humans to collaboratively solve complicated tasks for search and rescue, manufacturing, etc. Efficient teamwork can be achieved by understanding user preferences and recommending different strategies for solving the particular task to humans. Prior work has focused on personalization of recommendation systems for relatively well-understood tasks in the context of e-commerce or social networks. In this paper, we seek to understand the important factors to consider while designing user-centric strategy recommendation systems for decision-making. We conducted a human-subjects experiment (n=60) for measuring the preferences of users with different personality types towards different strategy recommendation systems. We conducted our experiment across four types of strategy recommendation modalities that have been established in prior work: (1) Single strategy recommendation, (2) Multiple similar recommendations, (3) Multiple diverse recommendations, (4) All possible strategies recommendations. While these strategy recommendation schemes have been explored independently in prior work, our study is novel in that we employ all of them simultaneously and in the context of strategy recommendations, to provide us an in-depth overview of the perception of different strategy recommendation systems. We found that certain personality traits, such as conscientiousness, notably impact the preference towards a particular type of system (p < 0.01). Finally, we report an interesting relationship between usability, alignment and perceived intelligence wherein greater perceived alignment of recommendations with one's own preferences leads to higher perceived intelligence (p < 0.01) and higher usability (p < 0.01).
Towards Reconciling Usability and Usefulness of Explainable AI Methodologies
Jan 13, 2023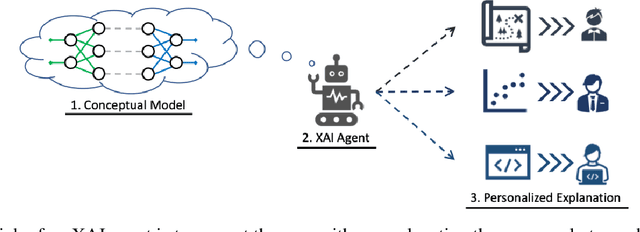
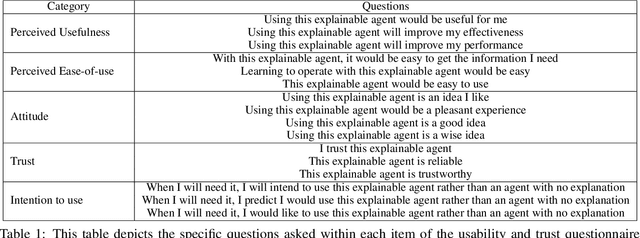

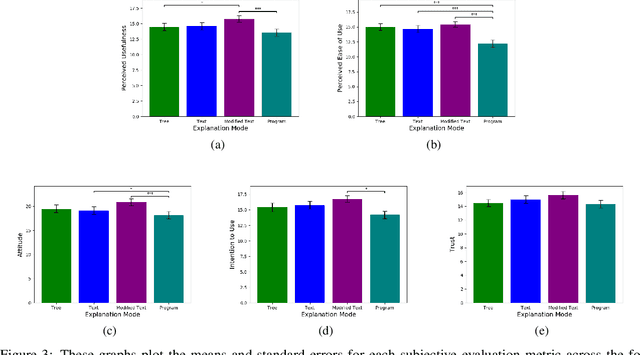
Interactive Artificial Intelligence (AI) agents are becoming increasingly prevalent in society. However, application of such systems without understanding them can be problematic. Black-box AI systems can lead to liability and accountability issues when they produce an incorrect decision. Explainable AI (XAI) seeks to bridge the knowledge gap, between developers and end-users, by offering insights into how an AI algorithm functions. Many modern algorithms focus on making the AI model "transparent", i.e. unveil the inherent functionality of the agent in a simpler format. However, these approaches do not cater to end-users of these systems, as users may not possess the requisite knowledge to understand these explanations in a reasonable amount of time. Therefore, to be able to develop suitable XAI methods, we need to understand the factors which influence subjective perception and objective usability. In this paper, we present a novel user-study which studies four differing XAI modalities commonly employed in prior work for explaining AI behavior, i.e. Decision Trees, Text, Programs. We study these XAI modalities in the context of explaining the actions of a self-driving car on a highway, as driving is an easily understandable real-world task and self-driving cars is a keen area of interest within the AI community. Our findings highlight internal consistency issues wherein participants perceived language explanations to be significantly more usable, however participants were better able to objectively understand the decision making process of the car through a decision tree explanation. Our work also provides further evidence of importance of integrating user-specific and situational criteria into the design of XAI systems. Our findings show that factors such as computer science experience, and watching the car succeed or fail can impact the perception and usefulness of the explanation.
FedPC: Federated Learning for Language Generation with Personal and Context Preference Embeddings
Oct 07, 2022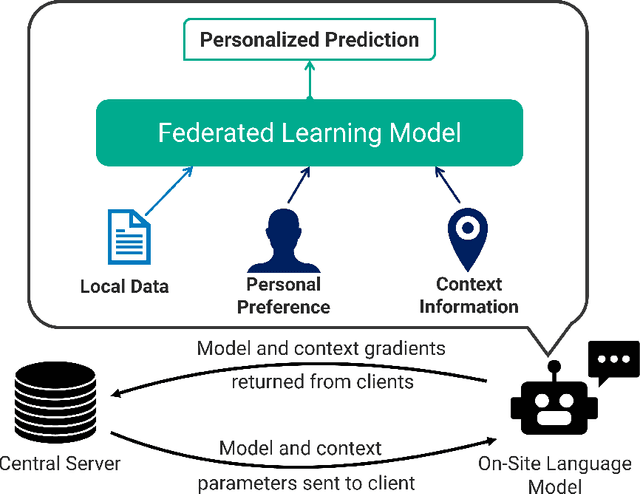
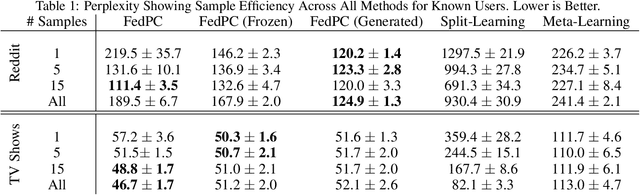
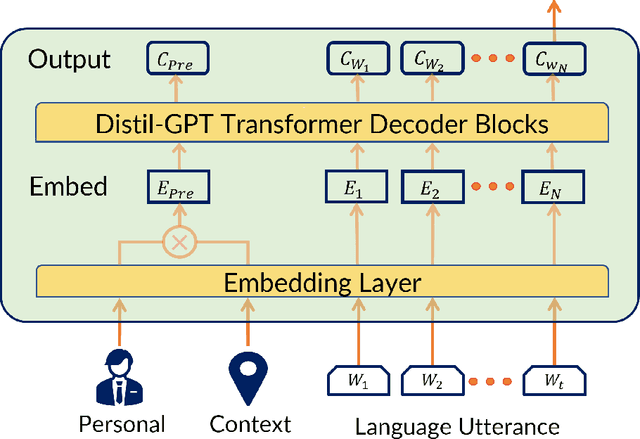
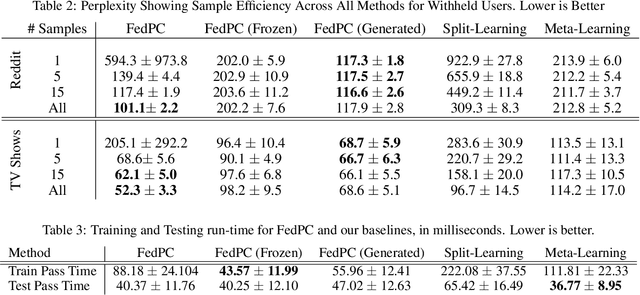
Federated learning is a training paradigm that learns from multiple distributed users without aggregating data on a centralized server. Such a paradigm promises the ability to deploy machine-learning at-scale to a diverse population of end-users without first collecting a large, labeled dataset for all possible tasks. As federated learning typically averages learning updates across a decentralized population, there is a growing need for personalization of federated learning systems (i.e conversational agents must be able to personalize to a specific user's preferences). In this work, we propose a new direction for personalization research within federated learning, leveraging both personal embeddings and shared context embeddings. We also present an approach to predict these ``preference'' embeddings, enabling personalization without backpropagation. Compared to state-of-the-art personalization baselines, our approach achieves a 50\% improvement in test-time perplexity using 0.001\% of the memory required by baseline approaches, and achieving greater sample- and compute-efficiency.
Commander's Intent: A Dataset and Modeling Approach for Human-AI Task Specification in Strategic Play
Aug 17, 2022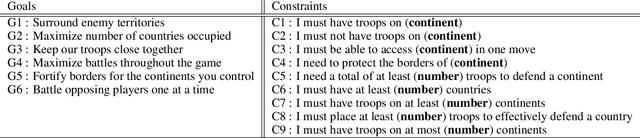
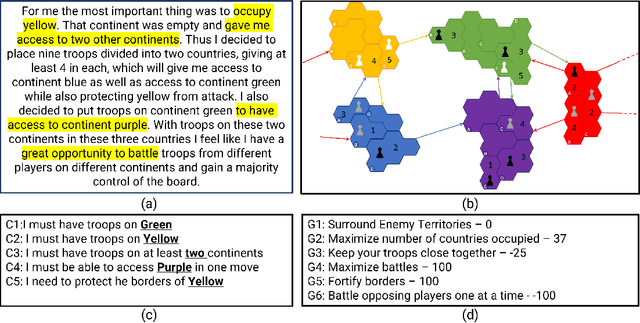
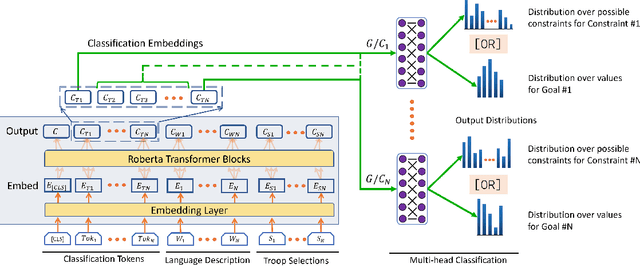
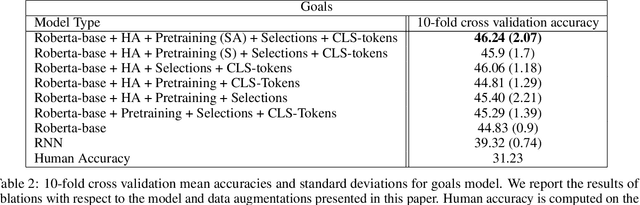
Effective Human-AI teaming requires the ability to communicate the goals of the team and constraints under which you need the agent to operate. Providing the ability to specify the shared intent or operation criteria of the team can enable an AI agent to perform its primary function while still being able to cater to the specific desires of the current team. While significant work has been conducted to instruct an agent to perform a task, via language or demonstrations, prior work lacks a focus on building agents which can operate within the parameters specified by a team. Worse yet, there is a dearth of research pertaining to enabling humans to provide their specifications through unstructured, naturalist language. In this paper, we propose the use of goals and constraints as a scaffold to modulate and evaluate autonomous agents. We contribute to this field by presenting a novel dataset, and an associated data collection protocol, which maps language descriptions to goals and constraints corresponding to specific strategies developed by human participants for the board game Risk. Leveraging state-of-the-art language models and augmentation procedures, we develop a machine learning framework which can be used to identify goals and constraints from unstructured strategy descriptions. To empirically validate our approach we conduct a human-subjects study to establish a human-baseline for our dataset. Our results show that our machine learning architecture is better able to interpret unstructured language descriptions into strategy specifications than human raters tasked with performing the same machine translation task (F(1,272.53) = 17.025, p < 0.001).
Interpretable Policy Specification and Synthesis through Natural Language and RL
Jan 18, 2021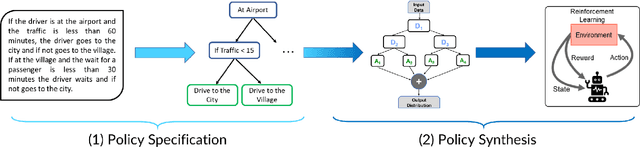
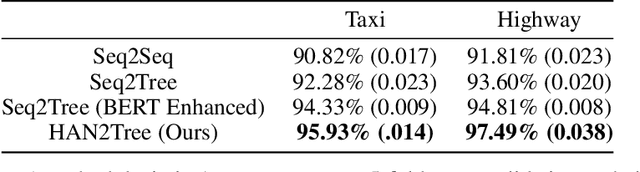
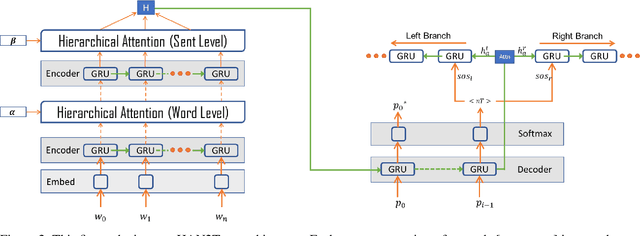

Policy specification is a process by which a human can initialize a robot's behaviour and, in turn, warm-start policy optimization via Reinforcement Learning (RL). While policy specification/design is inherently a collaborative process, modern methods based on Learning from Demonstration or Deep RL lack the model interpretability and accessibility to be classified as such. Current state-of-the-art methods for policy specification rely on black-box models, which are an insufficient means of collaboration for non-expert users: These models provide no means of inspecting policies learnt by the agent and are not focused on creating a usable modality for teaching robot behaviour. In this paper, we propose a novel machine learning framework that enables humans to 1) specify, through natural language, interpretable policies in the form of easy-to-understand decision trees, 2) leverage these policies to warm-start reinforcement learning and 3) outperform baselines that lack our natural language initialization mechanism. We train our approach by collecting a first-of-its-kind corpus mapping free-form natural language policy descriptions to decision tree-based policies. We show that our novel framework translates natural language to decision trees with a 96% and 97% accuracy on a held-out corpus across two domains, respectively. Finally, we validate that policies initialized with natural language commands are able to significantly outperform relevant baselines (p < 0.001) that do not benefit from our natural language-based warm-start technique.
Automated Rationale Generation: A Technique for Explainable AI and its Effects on Human Perceptions
Jan 11, 2019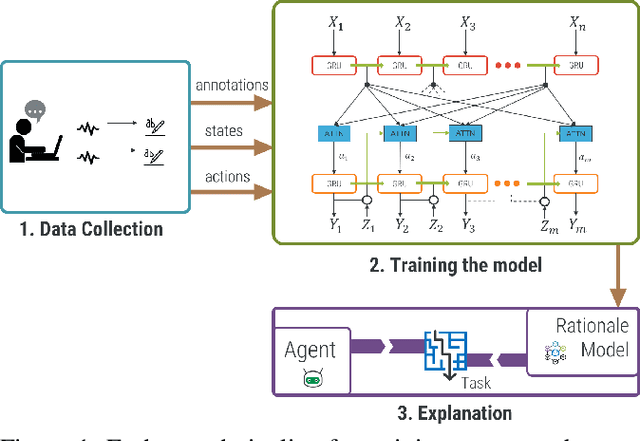


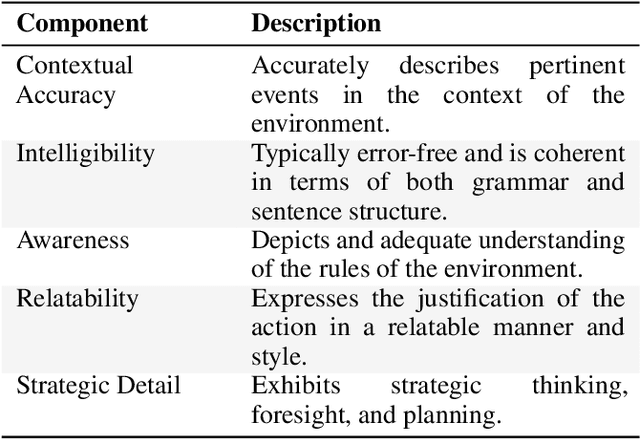
Automated rationale generation is an approach for real-time explanation generation whereby a computational model learns to translate an autonomous agent's internal state and action data representations into natural language. Training on human explanation data can enable agents to learn to generate human-like explanations for their behavior. In this paper, using the context of an agent that plays Frogger, we describe (a) how to collect a corpus of explanations, (b) how to train a neural rationale generator to produce different styles of rationales, and (c) how people perceive these rationales. We conducted two user studies. The first study establishes the plausibility of each type of generated rationale and situates their user perceptions along the dimensions of confidence, humanlike-ness, adequate justification, and understandability. The second study further explores user preferences between the generated rationales with regard to confidence in the autonomous agent, communicating failure and unexpected behavior. Overall, we find alignment between the intended differences in features of the generated rationales and the perceived differences by users. Moreover, context permitting, participants preferred detailed rationales to form a stable mental model of the agent's behavior.
Controllable Neural Story Generation via Reinforcement Learning
Sep 27, 2018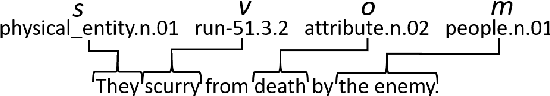
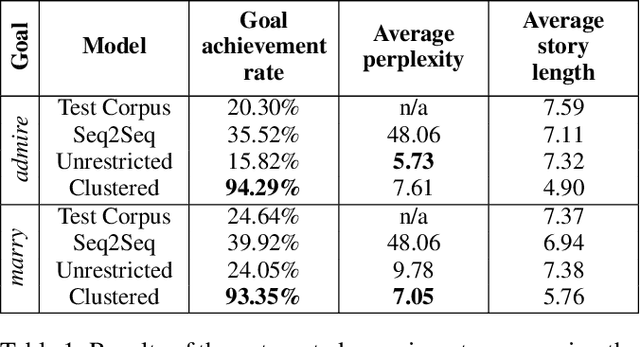
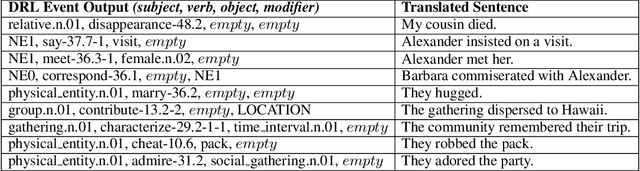
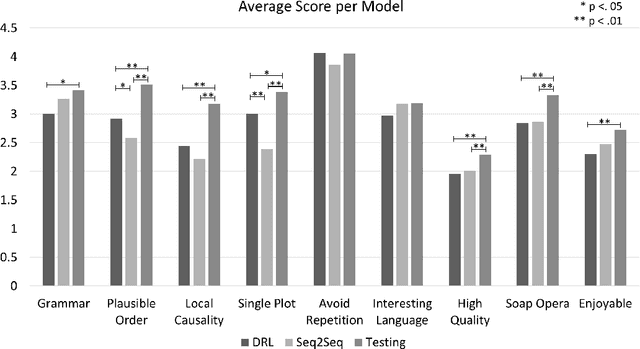
Open story generation is the problem of automatically creating a story for any domain without retraining. Neural language models can be trained on large corpora across many domains and then used to generate stories. However, stories generated via language models tend to lack direction and coherence. We introduce a policy gradient reinforcement learning approach to open story generation that learns to achieve a given narrative goal state. In this work, the goal is for a story to end with a specific type of event, given in advance. However, a reward based on achieving the given goal is too sparse for effective learning. We use reward shaping to provide the reinforcement learner with a partial reward at every step. We show that our technique can train a model that generates a story that reaches the goal 94% of the time and reduces model perplexity. A human subject evaluation shows that stories generated by our technique are perceived to have significantly higher plausible event ordering and plot coherence over a baseline language modeling technique without perceived degradation of overall quality, enjoyability, or local causality.