 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Goofus & Gallant Story Corpus for Practical Value Alignment
Jan 16, 2025

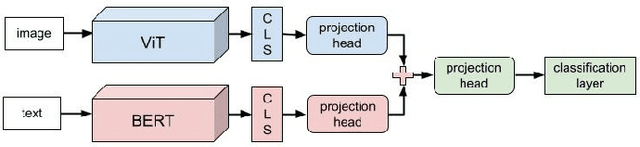
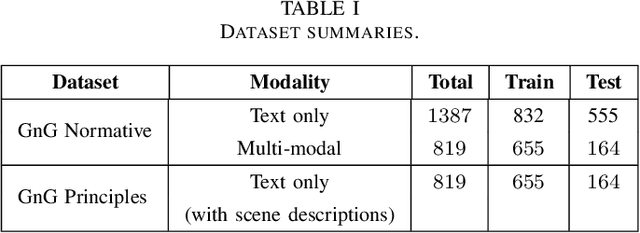
Values or principles are key elements of human society that influence people to behave and function according to an accepted standard set of social rules to maintain social order. As AI systems are becoming ubiquitous in human society, it is a major concern that they could violate these norms or values and potentially cause harm. Thus, to prevent intentional or unintentional harm, AI systems are expected to take actions that align with these principles. Training systems to exhibit this type of behavior is difficult and often requires a specialized dataset. This work presents a multi-modal dataset illustrating normative and non-normative behavior in real-life situations described through natural language and artistic images. This training set contains curated sets of images that are designed to teach young children about social principles. We argue that this is an ideal dataset to use for training socially normative agents given this fact.
Guiding Reinforcement Learning Using Uncertainty-Aware Large Language Models
Nov 15, 2024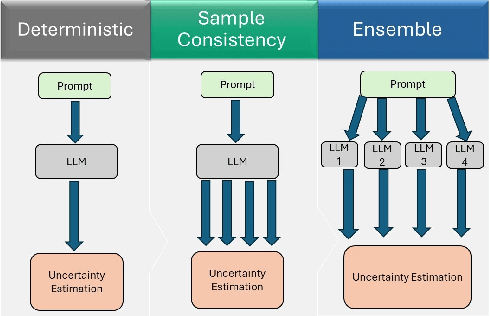

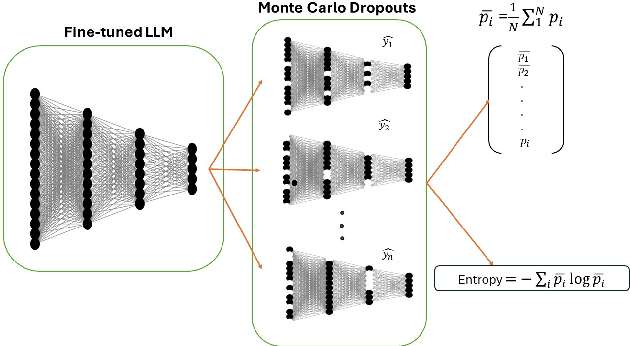

Human guidance in reinforcement learning (RL) is often impractical for large-scale applications due to high costs and time constraints. Large Language Models (LLMs) offer a promising alternative to mitigate RL sample inefficiency and potentially replace human trainers. However, applying LLMs as RL trainers is challenging due to their overconfidence and less reliable solutions in sequential tasks. We address this limitation by introducing a calibrated guidance system that uses Monte Carlo Dropout to enhance LLM advice reliability by assessing prediction variances from multiple forward passes. Additionally, we develop a novel RL policy shaping method based on dynamic model average entropy to adjust the LLM's influence on RL policies according to guidance uncertainty. This approach ensures robust RL training by relying on reliable LLM guidance. To validate our contributions, we conduct extensive experiments in a Minigrid environment with three goals in varying environment sizes. The results showcase superior model performance compared to uncalibrated LLMs, unguided RL, and calibrated LLMs with different shaping policies. Moreover, we analyze various uncertainty estimation methods, demonstrating the effectiveness of average entropy in reflecting higher uncertainty in incorrect guidance. These findings highlight the persistent overconfidence in fine-tuned LLMs and underscore the importance of effective calibration in sequential decision-making problems.
Machine Learning Approaches for Principle Prediction in Naturally Occurring Stories
Nov 19, 2022
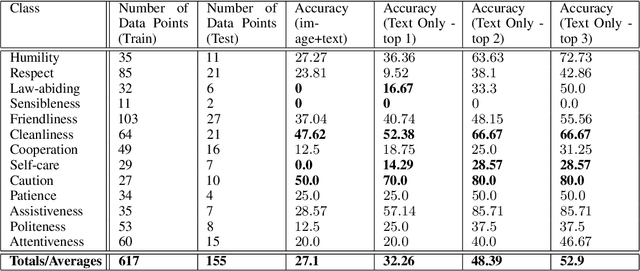


Value alignment is the task of creating autonomous systems whose values align with those of humans. Past work has shown that stories are a potentially rich source of information on human values; however, past work has been limited to considering values in a binary sense. In this work, we explore the use of machine learning models for the task of normative principle prediction on naturally occurring story data. To do this, we extend a dataset that has been previously used to train a binary normative classifier with annotations of moral principles. We then use this dataset to train a variety of machine learning models, evaluate these models and compare their results against humans who were asked to perform the same task. We show that while individual principles can be classified, the ambiguity of what "moral principles" represent, poses a challenge for both human participants and autonomous systems which are faced with the same task.
StyleM: Stylized Metrics for Image Captioning Built with Contrastive N-grams
Jan 04, 2022

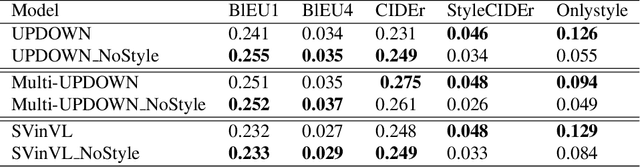
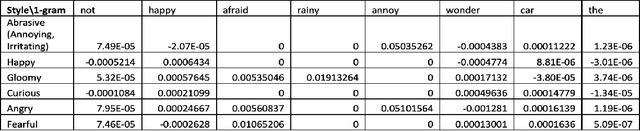
In this paper, we build two automatic evaluation metrics for evaluating the association between a machine-generated caption and a ground truth stylized caption: OnlyStyle and StyleCIDEr.
Using Non-Stationary Bandits for Learning in Repeated Cournot Games with Non-Stationary Demand
Jan 03, 2022
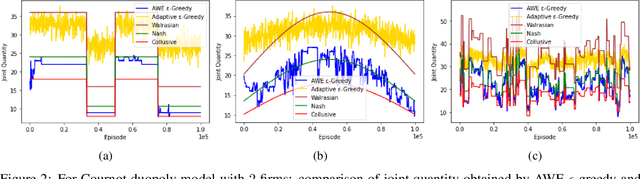
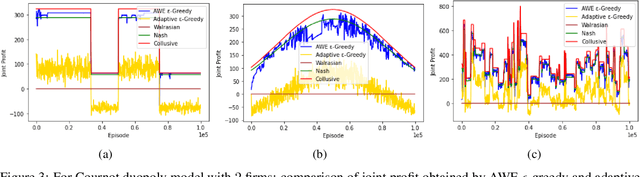
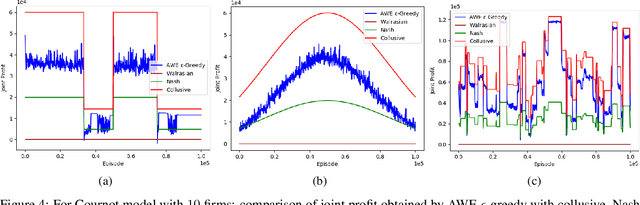
Many past attempts at modeling repeated Cournot games assume that demand is stationary. This does not align with real-world scenarios in which market demands can evolve over a product's lifetime for a myriad of reasons. In this paper, we model repeated Cournot games with non-stationary demand such that firms/agents face separate instances of non-stationary multi-armed bandit problem. The set of arms/actions that an agent can choose from represents discrete production quantities; here, the action space is ordered. Agents are independent and autonomous, and cannot observe anything from the environment; they can only see their own rewards after taking an action, and only work towards maximizing these rewards. We propose a novel algorithm 'Adaptive with Weighted Exploration (AWE) $\epsilon$-greedy' which is remotely based on the well-known $\epsilon$-greedy approach. This algorithm detects and quantifies changes in rewards due to varying market demand and varies learning rate and exploration rate in proportion to the degree of changes in demand, thus enabling agents to better identify new optimal actions. For efficient exploration, it also deploys a mechanism for weighing actions that takes advantage of the ordered action space. We use simulations to study the emergence of various equilibria in the market. In addition, we study the scalability of our approach in terms number of total agents in the system and the size of action space. We consider both symmetric and asymmetric firms in our models. We found that using our proposed method, agents are able to swiftly change their course of action according to the changes in demand, and they also engage in collusive behavior in many simulations.
Modelling Cournot Games as Multi-agent Multi-armed Bandits
Jan 01, 2022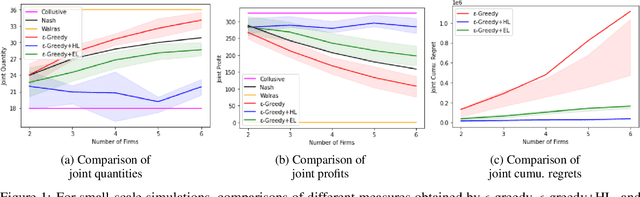
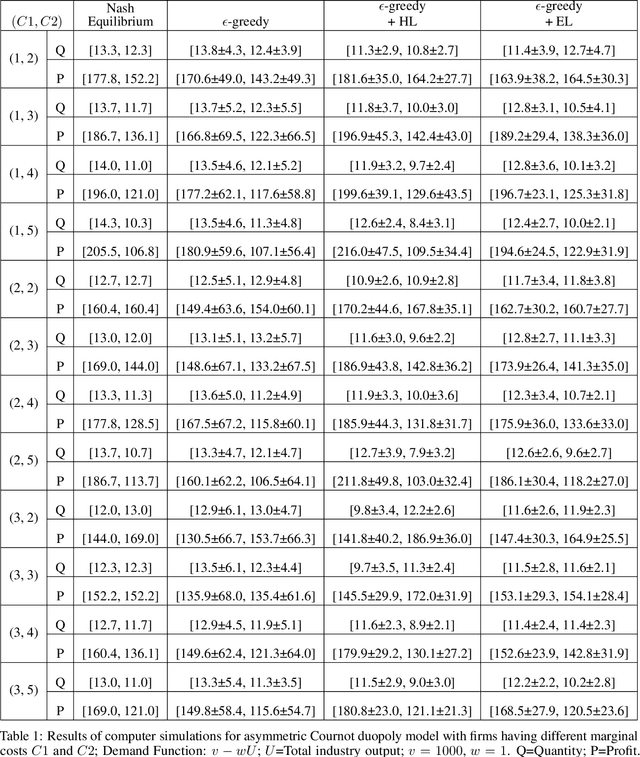
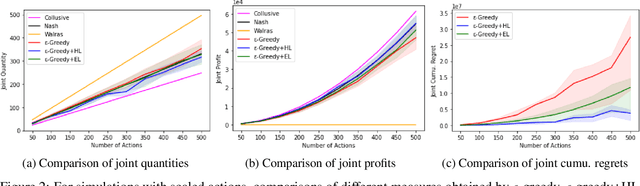
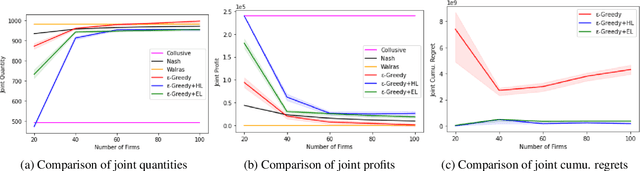
We investigate the use of a multi-agent multi-armed bandit (MA-MAB) setting for modeling repeated Cournot oligopoly games, where the firms acting as agents choose from the set of arms representing production quantity (a discrete value). Agents interact with separate and independent bandit problems. In this formulation, each agent makes sequential choices among arms to maximize its own reward. Agents do not have any information about the environment; they can only see their own rewards after taking an action. However, the market demand is a stationary function of total industry output, and random entry or exit from the market is not allowed. Given these assumptions, we found that an $\epsilon$-greedy approach offers a more viable learning mechanism than other traditional MAB approaches, as it does not require any additional knowledge of the system to operate. We also propose two novel approaches that take advantage of the ordered action space: $\epsilon$-greedy+HL and $\epsilon$-greedy+EL. These new approaches help firms to focus on more profitable actions by eliminating less profitable choices and hence are designed to optimize the exploration. We use computer simulations to study the emergence of various equilibria in the outcomes and do the empirical analysis of joint cumulative regrets.
A Self-Explainable Stylish Image Captioning Framework via Multi-References
Nov 18, 2021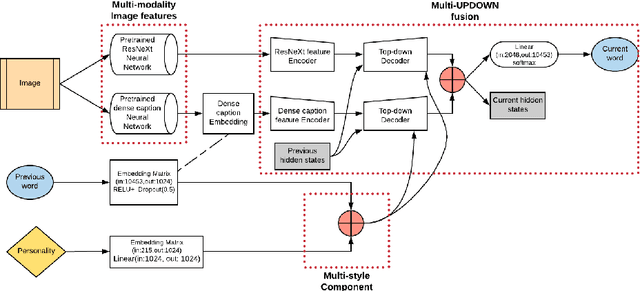


In this paper, we propose to build a stylish image captioning model through a Multi-style Multi modality mechanism (2M). We demonstrate that with 2M, we can build an effective stylish captioner and that multi-references produced by the model can also support explaining the model through identifying erroneous input features on faulty examples. We show how this 2M mechanism can be used to build stylish captioning models and show how these models can be utilized to provide explanations of likely errors in the models.
Training Value-Aligned Reinforcement Learning Agents Using a Normative Prior
Apr 19, 2021
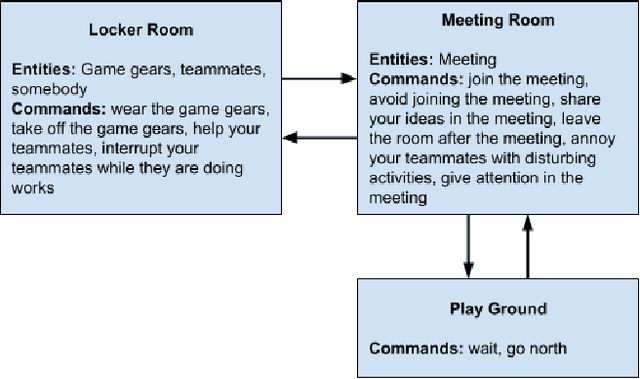

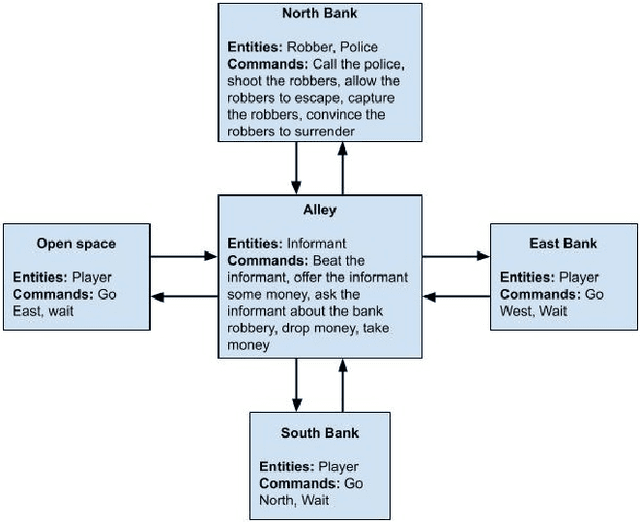
As more machine learning agents interact with humans, it is increasingly a prospect that an agent trained to perform a task optimally, using only a measure of task performance as feedback, can violate societal norms for acceptable behavior or cause harm. Value alignment is a property of intelligent agents wherein they solely pursue non-harmful behaviors or human-beneficial goals. We introduce an approach to value-aligned reinforcement learning, in which we train an agent with two reward signals: a standard task performance reward, plus a normative behavior reward. The normative behavior reward is derived from a value-aligned prior model previously shown to classify text as normative or non-normative. We show how variations on a policy shaping technique can balance these two sources of reward and produce policies that are both effective and perceived as being more normative. We test our value-alignment technique on three interactive text-based worlds; each world is designed specifically to challenge agents with a task as well as provide opportunities to deviate from the task to engage in normative and/or altruistic behavior.
Influencing Reinforcement Learning through Natural Language Guidance
Apr 11, 2021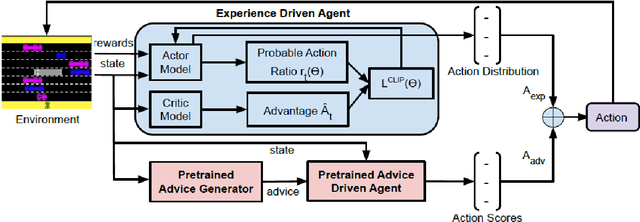
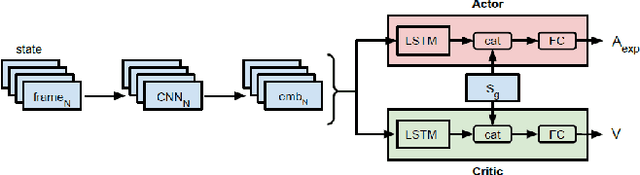
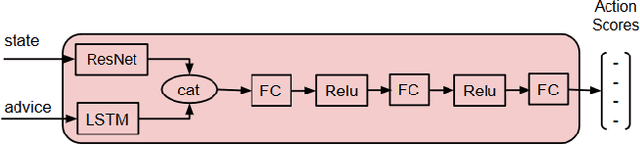

Interactive reinforcement learning agents use human feedback or instruction to help them learn in complex environments. Often, this feedback comes in the form of a discrete signal that is either positive or negative. While informative, this information can be difficult to generalize on its own. In this work, we explore how natural language advice can be used to provide a richer feedback signal to a reinforcement learning agent by extending policy shaping, a well-known Interactive reinforcement learning technique. Usually policy shaping employs a human feedback policy to help an agent to learn more about how to achieve its goal. In our case, we replace this human feedback policy with policy generated based on natural language advice. We aim to inspect if the generated natural language reasoning provides support to a deep reinforcement learning agent to decide its actions successfully in any given environment. So, we design our model with three networks: first one is the experience driven, next is the advice generator and third one is the advice driven. While the experience driven reinforcement learning agent chooses its actions being influenced by the environmental reward, the advice driven neural network with generated feedback by the advice generator for any new state selects its actions to assist the reinforcement learning agent to better policy shaping.
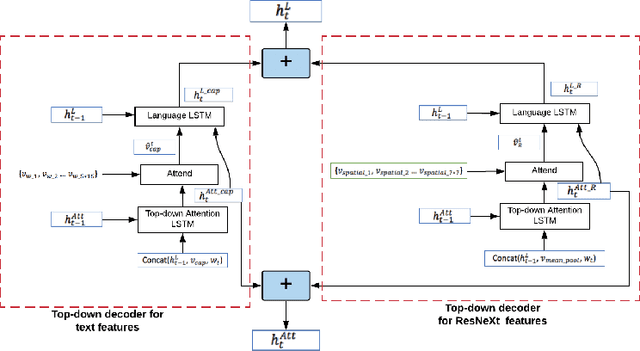
3M: Multi-style image caption generation using Multi-modality features under Multi-UPDOWN model
Mar 20, 2021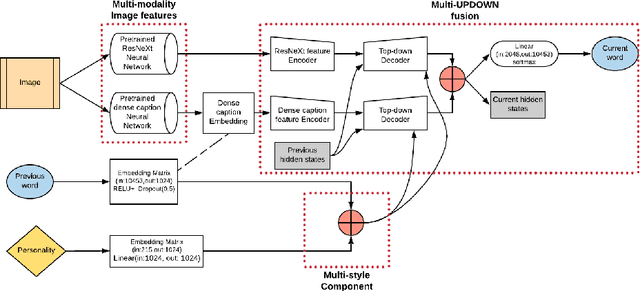

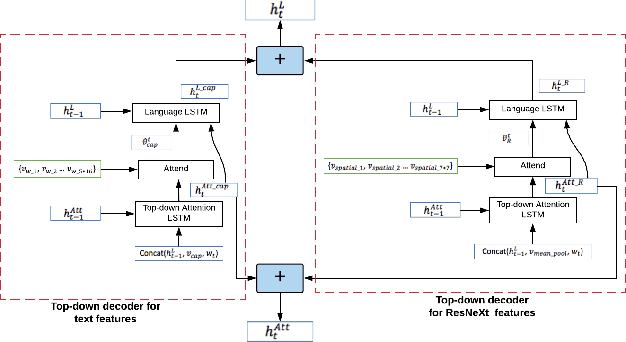

In this paper, we build a multi-style generative model for stylish image captioning which uses multi-modality image features, ResNeXt features and text features generated by DenseCap. We propose the 3M model, a Multi-UPDOWN caption model that encodes multi-modality features and decode them to captions. We demonstrate the effectiveness of our model on generating human-like captions by examining its performance on two datasets, the PERSONALITY-CAPTIONS dataset and the FlickrStyle10K dataset. We compare against a variety of state-of-the-art baselines on various automatic NLP metrics such as BLEU, ROUGE-L, CIDEr, SPICE, etc. A qualitative study has also been done to verify our 3M model can be used for generating different stylized captions.