 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalizing Task-oriented Dialog Systems via Zero-shot Generalizable Reward Function
Mar 24, 2023Task-oriented dialog systems enable users to accomplish tasks using natural language. State-of-the-art systems respond to users in the same way regardless of their personalities, although personalizing dialogues can lead to higher levels of adoption and better user experiences. Building personalized dialog systems is an important, yet challenging endeavor and only a handful of works took on the challenge. Most existing works rely on supervised learning approaches and require laborious and expensive labeled training data for each user profile. Additionally, collecting and labeling data for each user profile is virtually impossible. In this work, we propose a novel framework, P-ToD, to personalize task-oriented dialog systems capable of adapting to a wide range of user profiles in an unsupervised fashion using a zero-shot generalizable reward function. P-ToD uses a pre-trained GPT-2 as a backbone model and works in three phases. Phase one performs task-specific training. Phase two kicks off unsupervised personalization by leveraging the proximal policy optimization algorithm that performs policy gradients guided by the zero-shot generalizable reward function. Our novel reward function can quantify the quality of the generated responses even for unseen profiles. The optional final phase fine-tunes the personalized model using a few labeled training examples. We conduct extensive experimental analysis using the personalized bAbI dialogue benchmark for five tasks and up to 180 diverse user profiles. The experimental results demonstrate that P-ToD, even when it had access to zero labeled examples, outperforms state-of-the-art supervised personalization models and achieves competitive performance on BLEU and ROUGE metrics when compared to a strong fully-supervised GPT-2 baseline
Using Non-Stationary Bandits for Learning in Repeated Cournot Games with Non-Stationary Demand
Jan 03, 2022
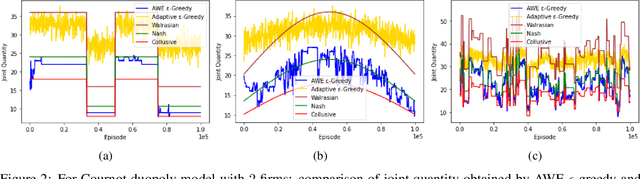
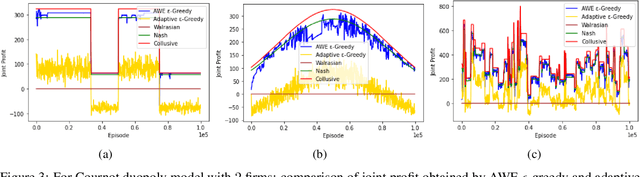
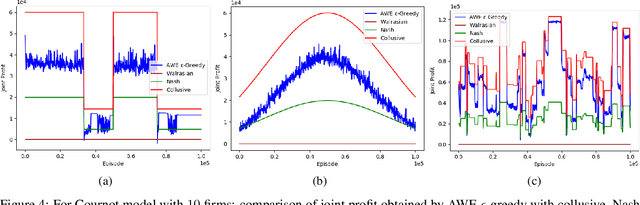
Many past attempts at modeling repeated Cournot games assume that demand is stationary. This does not align with real-world scenarios in which market demands can evolve over a product's lifetime for a myriad of reasons. In this paper, we model repeated Cournot games with non-stationary demand such that firms/agents face separate instances of non-stationary multi-armed bandit problem. The set of arms/actions that an agent can choose from represents discrete production quantities; here, the action space is ordered. Agents are independent and autonomous, and cannot observe anything from the environment; they can only see their own rewards after taking an action, and only work towards maximizing these rewards. We propose a novel algorithm 'Adaptive with Weighted Exploration (AWE) $\epsilon$-greedy' which is remotely based on the well-known $\epsilon$-greedy approach. This algorithm detects and quantifies changes in rewards due to varying market demand and varies learning rate and exploration rate in proportion to the degree of changes in demand, thus enabling agents to better identify new optimal actions. For efficient exploration, it also deploys a mechanism for weighing actions that takes advantage of the ordered action space. We use simulations to study the emergence of various equilibria in the market. In addition, we study the scalability of our approach in terms number of total agents in the system and the size of action space. We consider both symmetric and asymmetric firms in our models. We found that using our proposed method, agents are able to swiftly change their course of action according to the changes in demand, and they also engage in collusive behavior in many simulations.
Modelling Cournot Games as Multi-agent Multi-armed Bandits
Jan 01, 2022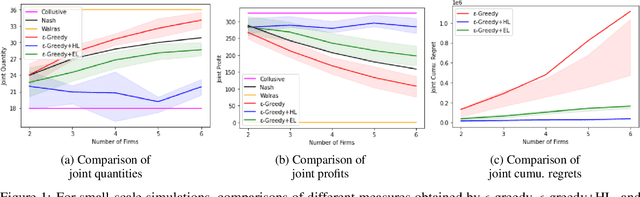
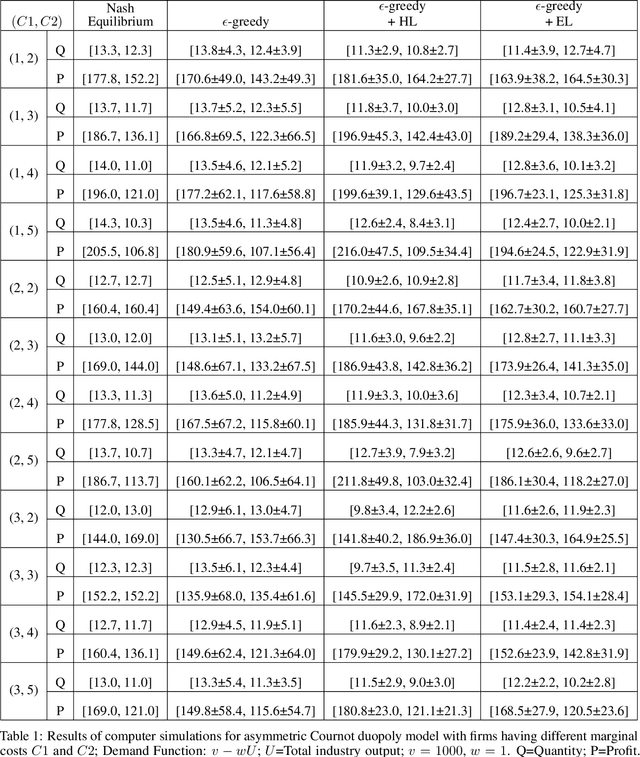
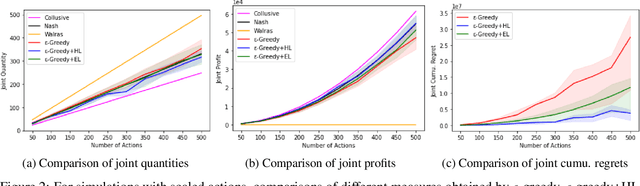
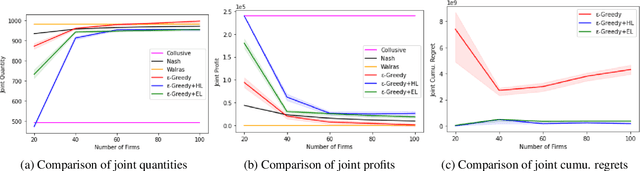
We investigate the use of a multi-agent multi-armed bandit (MA-MAB) setting for modeling repeated Cournot oligopoly games, where the firms acting as agents choose from the set of arms representing production quantity (a discrete value). Agents interact with separate and independent bandit problems. In this formulation, each agent makes sequential choices among arms to maximize its own reward. Agents do not have any information about the environment; they can only see their own rewards after taking an action. However, the market demand is a stationary function of total industry output, and random entry or exit from the market is not allowed. Given these assumptions, we found that an $\epsilon$-greedy approach offers a more viable learning mechanism than other traditional MAB approaches, as it does not require any additional knowledge of the system to operate. We also propose two novel approaches that take advantage of the ordered action space: $\epsilon$-greedy+HL and $\epsilon$-greedy+EL. These new approaches help firms to focus on more profitable actions by eliminating less profitable choices and hence are designed to optimize the exploration. We use computer simulations to study the emergence of various equilibria in the outcomes and do the empirical analysis of joint cumulative regrets.
Reinforcement Learning for Decentralized Stable Matching
May 03, 2020
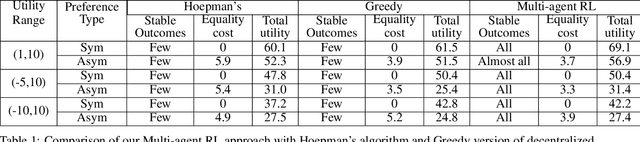
When it comes to finding a match/partner in the real world, it is usually an independent and autonomous task performed by people/entities. For a person, a match can be several things such as a romantic partner, business partner, school, roommate, etc. Our purpose in this paper is to train autonomous agents to find suitable matches for themselves using reinforcement learning. We consider the decentralized two-sided stable matching problem, where an agent is allowed to have at most one partner at a time from the opposite set. Each agent receives some utility for being in a match with a member of the opposite set. We formulate the problem spatially as a grid world environment and having autonomous agents acting independently makes our environment very uncertain and dynamic. We run experiments with various instances of both complete and incomplete weighted preference lists for agents. Agents learn their policies separately, using separate training modules. Our goal is to train agents to find partners such that the outcome is a stable matching if one exists and also a matching with set-equality, meaning the outcome is approximately equally likable by agents from both the sets.