 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINTERPOS: Interaction Rhythm Guided Positional Morphing for Mobile App Recommender Systems
Jun 14, 2025The mobile app market has expanded exponentially, offering millions of apps with diverse functionalities, yet research in mobile app recommendation remains limited. Traditional sequential recommender systems utilize the order of items in users' historical interactions to predict the next item for the users. Position embeddings, well-established in transformer-based architectures for natural language processing tasks, effectively distinguish token positions in sequences. In sequential recommendation systems, position embeddings can capture the order of items in a user's historical interaction sequence. Nevertheless, this ordering does not consider the time elapsed between two interactions of the same user (e.g., 1 day, 1 week, 1 month), referred to as "user rhythm". In mobile app recommendation datasets, the time between consecutive user interactions is notably longer compared to other domains like movies, posing significant challenges for sequential recommender systems. To address this phenomenon in the mobile app domain, we introduce INTERPOS, an Interaction Rhythm Guided Positional Morphing strategy for autoregressive mobile app recommender systems. INTERPOS incorporates rhythm-guided position embeddings, providing a more comprehensive representation that considers both the sequential order of interactions and the temporal gaps between them. This approach enables a deep understanding of users' rhythms at a fine-grained level, capturing the intricacies of their interaction patterns over time. We propose three strategies to incorporate the morphed positional embeddings in two transformer-based sequential recommendation system architectures. Our extensive evaluations show that INTERPOS outperforms state-of-the-art models using 7 mobile app recommendation datasets on NDCG@K and HIT@K metrics. The source code of INTERPOS is available at https://github.com/dlgrad/INTERPOS.
* 10 pages, 8 tables, 3 figures
Zero-Shot Generalizable End-to-End Task-Oriented Dialog System using Context Summarization and Domain Schema
Mar 28, 2023Task-oriented dialog systems empower users to accomplish their goals by facilitating intuitive and expressive natural language interactions. State-of-the-art approaches in task-oriented dialog systems formulate the problem as a conditional sequence generation task and fine-tune pre-trained causal language models in the supervised setting. This requires labeled training data for each new domain or task, and acquiring such data is prohibitively laborious and expensive, thus making it a bottleneck for scaling systems to a wide range of domains. To overcome this challenge, we introduce a novel Zero-Shot generalizable end-to-end Task-oriented Dialog system, ZS-ToD, that leverages domain schemas to allow for robust generalization to unseen domains and exploits effective summarization of the dialog history. We employ GPT-2 as a backbone model and introduce a two-step training process where the goal of the first step is to learn the general structure of the dialog data and the second step optimizes the response generation as well as intermediate outputs, such as dialog state and system actions. As opposed to state-of-the-art systems that are trained to fulfill certain intents in the given domains and memorize task-specific conversational patterns, ZS-ToD learns generic task-completion skills by comprehending domain semantics via domain schemas and generalizing to unseen domains seamlessly. We conduct an extensive experimental evaluation on SGD and SGD-X datasets that span up to 20 unique domains and ZS-ToD outperforms state-of-the-art systems on key metrics, with an improvement of +17% on joint goal accuracy and +5 on inform. Additionally, we present a detailed ablation study to demonstrate the effectiveness of the proposed components and training mechanism
Personalizing Task-oriented Dialog Systems via Zero-shot Generalizable Reward Function
Mar 24, 2023Task-oriented dialog systems enable users to accomplish tasks using natural language. State-of-the-art systems respond to users in the same way regardless of their personalities, although personalizing dialogues can lead to higher levels of adoption and better user experiences. Building personalized dialog systems is an important, yet challenging endeavor and only a handful of works took on the challenge. Most existing works rely on supervised learning approaches and require laborious and expensive labeled training data for each user profile. Additionally, collecting and labeling data for each user profile is virtually impossible. In this work, we propose a novel framework, P-ToD, to personalize task-oriented dialog systems capable of adapting to a wide range of user profiles in an unsupervised fashion using a zero-shot generalizable reward function. P-ToD uses a pre-trained GPT-2 as a backbone model and works in three phases. Phase one performs task-specific training. Phase two kicks off unsupervised personalization by leveraging the proximal policy optimization algorithm that performs policy gradients guided by the zero-shot generalizable reward function. Our novel reward function can quantify the quality of the generated responses even for unseen profiles. The optional final phase fine-tunes the personalized model using a few labeled training examples. We conduct extensive experimental analysis using the personalized bAbI dialogue benchmark for five tasks and up to 180 diverse user profiles. The experimental results demonstrate that P-ToD, even when it had access to zero labeled examples, outperforms state-of-the-art supervised personalization models and achieves competitive performance on BLEU and ROUGE metrics when compared to a strong fully-supervised GPT-2 baseline
MobileRec: A Large-Scale Dataset for Mobile Apps Recommendation
Mar 12, 2023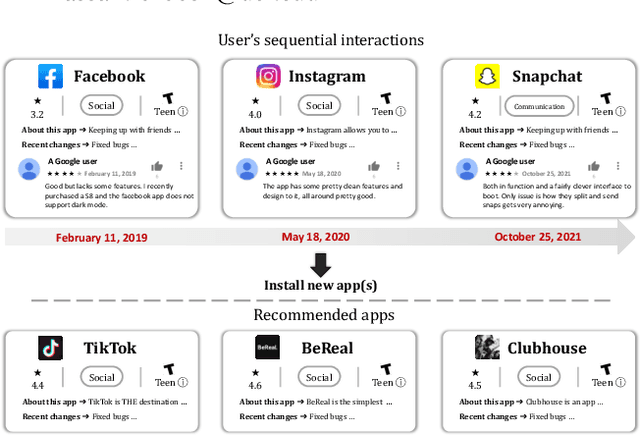


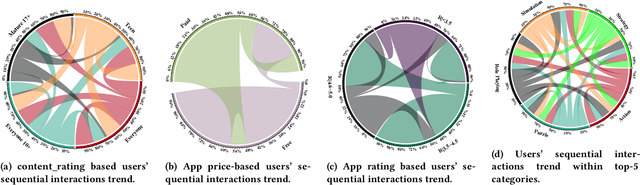
Recommender systems have become ubiquitous in our digital lives, from recommending products on e-commerce websites to suggesting movies and music on streaming platforms. Existing recommendation datasets, such as Amazon Product Reviews and MovieLens, greatly facilitated the research and development of recommender systems in their respective domains. While the number of mobile users and applications (aka apps) has increased exponentially over the past decade, research in mobile app recommender systems has been significantly constrained, primarily due to the lack of high-quality benchmark datasets, as opposed to recommendations for products, movies, and news. To facilitate research for app recommendation systems, we introduce a large-scale dataset, called MobileRec. We constructed MobileRec from users' activity on the Google play store. MobileRec contains 19.3 million user interactions (i.e., user reviews on apps) with over 10K unique apps across 48 categories. MobileRec records the sequential activity of a total of 0.7 million distinct users. Each of these users has interacted with no fewer than five distinct apps, which stands in contrast to previous datasets on mobile apps that recorded only a single interaction per user. Furthermore, MobileRec presents users' ratings as well as sentiments on installed apps, and each app contains rich metadata such as app name, category, description, and overall rating, among others. We demonstrate that MobileRec can serve as an excellent testbed for app recommendation through a comparative study of several state-of-the-art recommendation approaches. The quantitative results can act as a baseline for other researchers to compare their results against. The MobileRec dataset is available at https://huggingface.co/datasets/recmeapp/mobilerec.