 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangFIR: Discovering Sparse Language-Specific Features from Monolingual Data for Language Steering
Apr 04, 2026Large language models (LLMs) show strong multilingual capabilities, yet reliably controlling the language of their outputs remains difficult. Representation-level steering addresses this by adding language-specific vectors to model activations at inference time, but identifying language-specific directions in the residual stream often relies on multilingual or parallel data that can be expensive to obtain. Sparse autoencoders (SAEs) decompose residual activations into interpretable, sparse feature directions and offer a natural basis for this search, yet existing SAE-based approaches face the same data constraint. We introduce LangFIR (Language Feature Identification via Random-token Filtering), a method that discovers language-specific SAE features using only a small amount of monolingual data and random-token sequences. Many SAE features consistently activated by target-language inputs do not encode language identity. Random-token sequences surface these language-agnostic features, allowing LangFIR to filter them out and isolate a sparse set of language-specific features. We show that these features are extremely sparse, highly selective for their target language, and causally important: directional ablation increases cross-entropy loss only for the corresponding language. Using these features to construct steering vectors for multilingual generation control, LangFIR achieves the best average accuracy BLEU across three models (Gemma 3 1B, Gemma 3 4B, and Llama 3.1 8B), three datasets, and twelve target languages, outperforming the strongest monolingual baseline by up to and surpassing methods that rely on parallel data. Our results suggest that language identity in multilingual LLMs is localized in a sparse set of feature directions discoverable with monolingual data. Code is available at https://anonymous.4open.science/r/LangFIR-C0F5/.
MobileDev-Bench: A Comprehensive Benchmark for Evaluating Language Models on Mobile Application Development
Mar 26, 2026Large language models (LLMs) have shown strong performance on automated software engineering tasks, yet existing benchmarks focus primarily on general-purpose libraries or web applications, leaving mobile application development largely unexplored despite its strict platform constraints, framework-driven lifecycles, and complex platform API interactions. We introduce MobileDev-Bench, a benchmark comprising 384 real-world issue-resolution tasks collected from 18 production mobile applications spanning Android Native (Java/Kotlin), React Native (TypeScript), and Flutter (Dart). Each task pairs an authentic developer-reported issue with executable test patches, enabling fully automated validation of model-generated fixes within mobile build environments. The benchmark exhibits substantial patch complexity: fixes modify 12.5 files and 324.9 lines on average, and 35.7% of instances require coordinated changes across multiple artifact types, such as source and manifest files. Evaluation of four state-of-the-art code-capable LLMs, GPT- 5.2, Claude Sonnet 4.5, Gemini Flash 2.5, and Qwen3-Coder, yields low end-to-end resolution rates of 3.39%-5.21%, revealing significant performance gaps compared to prior benchmarks. Further analysis reveals systematic failure modes, with fault localization across multi-file and multi-artifact changes emerging as the primary bottleneck.
A Large-Scale Study on the Development and Issues of Multi-Agent AI Systems
Jan 12, 2026The rapid emergence of multi-agent AI systems (MAS), including LangChain, CrewAI, and AutoGen, has shaped how large language model (LLM) applications are developed and orchestrated. However, little is known about how these systems evolve and are maintained in practice. This paper presents the first large-scale empirical study of open-source MAS, analyzing over 42K unique commits and over 4.7K resolved issues across eight leading systems. Our analysis identifies three distinct development profiles: sustained, steady, and burst-driven. These profiles reflect substantial variation in ecosystem maturity. Perfective commits constitute 40.8% of all changes, suggesting that feature enhancement is prioritized over corrective maintenance (27.4%) and adaptive updates (24.3%). Data about issues shows that the most frequent concerns involve bugs (22%), infrastructure (14%), and agent coordination challenges (10%). Issue reporting also increased sharply across all frameworks starting in 2023. Median resolution times range from under one day to about two weeks, with distributions skewed toward fast responses but a minority of issues requiring extended attention. These results highlight both the momentum and the fragility of the current ecosystem, emphasizing the need for improved testing infrastructure, documentation quality, and maintenance practices to ensure long-term reliability and sustainability.
Multi-Granular Node Pruning for Circuit Discovery
Dec 11, 2025Circuit discovery aims to identify minimal subnetworks that are responsible for specific behaviors in large language models (LLMs). Existing approaches primarily rely on iterative edge pruning, which is computationally expensive and limited to coarse-grained units such as attention heads or MLP blocks, overlooking finer structures like individual neurons. We propose a node-level pruning framework for circuit discovery that addresses both scalability and granularity limitations. Our method introduces learnable masks across multiple levels of granularity, from entire blocks to individual neurons, within a unified optimization objective. Granularity-specific sparsity penalties guide the pruning process, allowing a comprehensive compression in a single fine-tuning run. Empirically, our approach identifies circuits that are smaller in nodes than those discovered by prior methods; moreover, we demonstrate that many neurons deemed important by coarse methods are actually irrelevant, while still maintaining task performance. Furthermore, our method has a significantly lower memory footprint, 5-10x, as it does not require keeping intermediate activations in the memory to work.
Evaluating Sparse Autoencoders for Monosemantic Representation
Aug 20, 2025A key barrier to interpreting large language models is polysemanticity, where neurons activate for multiple unrelated concepts. Sparse autoencoders (SAEs) have been proposed to mitigate this issue by transforming dense activations into sparse, more interpretable features. While prior work suggests that SAEs promote monosemanticity, there has been no quantitative comparison with their base models. This paper provides the first systematic evaluation of SAEs against base models concerning monosemanticity. We introduce a fine-grained concept separability score based on the Jensen-Shannon distance, which captures how distinctly a neuron's activation distributions vary across concepts. Using Gemma-2-2B and multiple SAE variants across five benchmarks, we show that SAEs reduce polysemanticity and achieve higher concept separability. However, greater sparsity of SAEs does not always yield better separability and often impairs downstream performance. To assess practical utility, we evaluate concept-level interventions using two strategies: full neuron masking and partial suppression. We find that, compared to base models, SAEs enable more precise concept-level control when using partial suppression. Building on this, we propose Attenuation via Posterior Probabilities (APP), a new intervention method that uses concept-conditioned activation distributions for targeted suppression. APP outperforms existing approaches in targeted concept removal.
INTERPOS: Interaction Rhythm Guided Positional Morphing for Mobile App Recommender Systems
Jun 14, 2025The mobile app market has expanded exponentially, offering millions of apps with diverse functionalities, yet research in mobile app recommendation remains limited. Traditional sequential recommender systems utilize the order of items in users' historical interactions to predict the next item for the users. Position embeddings, well-established in transformer-based architectures for natural language processing tasks, effectively distinguish token positions in sequences. In sequential recommendation systems, position embeddings can capture the order of items in a user's historical interaction sequence. Nevertheless, this ordering does not consider the time elapsed between two interactions of the same user (e.g., 1 day, 1 week, 1 month), referred to as "user rhythm". In mobile app recommendation datasets, the time between consecutive user interactions is notably longer compared to other domains like movies, posing significant challenges for sequential recommender systems. To address this phenomenon in the mobile app domain, we introduce INTERPOS, an Interaction Rhythm Guided Positional Morphing strategy for autoregressive mobile app recommender systems. INTERPOS incorporates rhythm-guided position embeddings, providing a more comprehensive representation that considers both the sequential order of interactions and the temporal gaps between them. This approach enables a deep understanding of users' rhythms at a fine-grained level, capturing the intricacies of their interaction patterns over time. We propose three strategies to incorporate the morphed positional embeddings in two transformer-based sequential recommendation system architectures. Our extensive evaluations show that INTERPOS outperforms state-of-the-art models using 7 mobile app recommendation datasets on NDCG@K and HIT@K metrics. The source code of INTERPOS is available at https://github.com/dlgrad/INTERPOS.
* 10 pages, 8 tables, 3 figures
What Users Value and Critique: Large-Scale Analysis of User Feedback on AI-Powered Mobile Apps
Jun 12, 2025
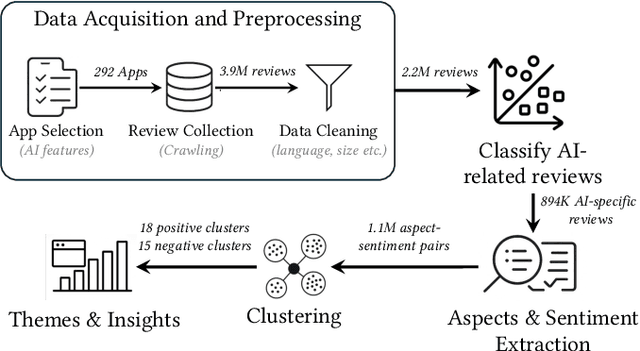
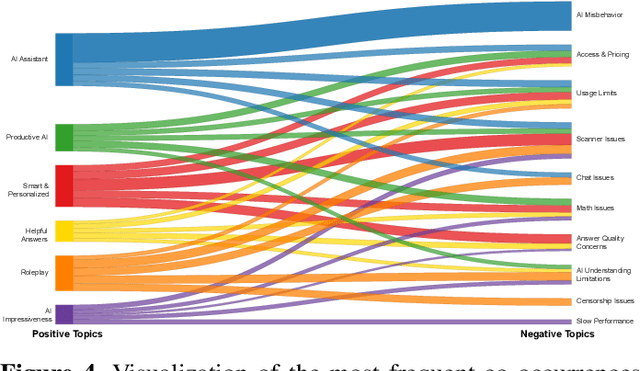
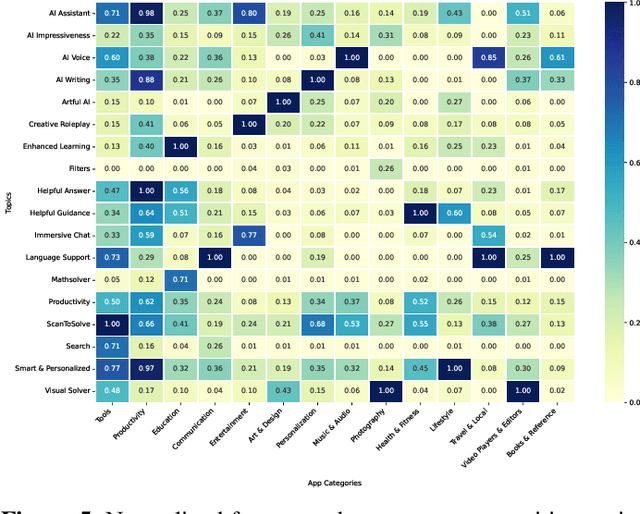
Artificial Intelligence (AI)-powered features have rapidly proliferated across mobile apps in various domains, including productivity, education, entertainment, and creativity. However, how users perceive, evaluate, and critique these AI features remains largely unexplored, primarily due to the overwhelming volume of user feedback. In this work, we present the first comprehensive, large-scale study of user feedback on AI-powered mobile apps, leveraging a curated dataset of 292 AI-driven apps across 14 categories with 894K AI-specific reviews from Google Play. We develop and validate a multi-stage analysis pipeline that begins with a human-labeled benchmark and systematically evaluates large language models (LLMs) and prompting strategies. Each stage, including review classification, aspect-sentiment extraction, and clustering, is validated for accuracy and consistency. Our pipeline enables scalable, high-precision analysis of user feedback, extracting over one million aspect-sentiment pairs clustered into 18 positive and 15 negative user topics. Our analysis reveals that users consistently focus on a narrow set of themes: positive comments emphasize productivity, reliability, and personalized assistance, while negative feedback highlights technical failures (e.g., scanning and recognition), pricing concerns, and limitations in language support. Our pipeline surfaces both satisfaction with one feature and frustration with another within the same review. These fine-grained, co-occurring sentiments are often missed by traditional approaches that treat positive and negative feedback in isolation or rely on coarse-grained analysis. To this end, our approach provides a more faithful reflection of the real-world user experiences with AI-powered apps. Category-aware analysis further uncovers both universal drivers of satisfaction and domain-specific frustrations.
Improving Multi-turn Task Completion in Task-Oriented Dialog Systems via Prompt Chaining and Fine-Grained Feedback
Feb 18, 2025Task-oriented dialog (TOD) systems facilitate users in accomplishing complex, multi-turn tasks through natural language. While traditional approaches rely on extensive fine-tuning and annotated data for each domain, instruction-tuned large language models (LLMs) offer a more flexible alternative. However, LLMs struggle to reliably handle multi-turn task completion, particularly with accurately generating API calls and adapting to new domains without explicit demonstrations. To address these challenges, we propose RealTOD, a novel framework that enhances TOD systems through prompt chaining and fine-grained feedback mechanisms. Prompt chaining enables zero-shot domain adaptation via a two-stage prompting strategy, eliminating the need for human-curated demonstrations. Meanwhile, the fine-grained feedback mechanism improves task completion by verifying API calls against domain schemas and providing precise corrective feedback when errors are detected. We conduct extensive experiments on the SGD and BiTOD benchmarks using four LLMs. RealTOD improves API accuracy, surpassing AutoTOD by 37.74% on SGD and SimpleTOD by 11.26% on BiTOD. Human evaluations further confirm that LLMs integrated with RealTOD achieve superior task completion, fluency, and informativeness compared to existing methods.
Evaluating and Enhancing Out-of-Domain Generalization of Task-Oriented Dialog Systems for Task Completion without Turn-level Dialog Annotations
Feb 18, 2025
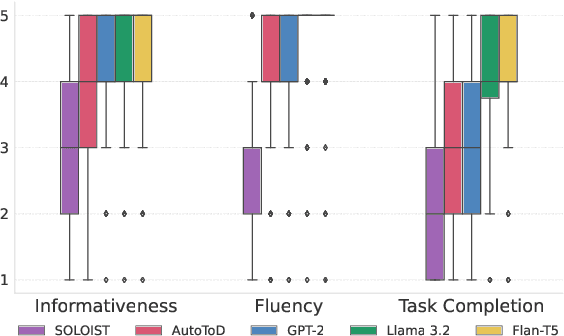
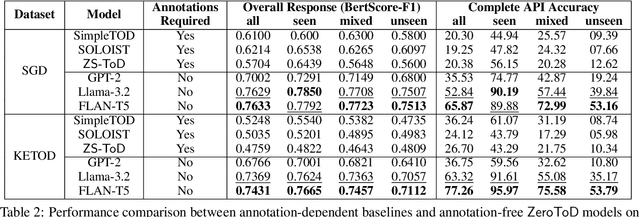

Traditional task-oriented dialog (ToD) systems rely heavily on labor-intensive turn-level annotations, such as dialogue states and policy labels, for training. This work explores whether large language models (LLMs) can be fine-tuned solely on natural language dialogs to perform ToD tasks, without requiring such annotations. We evaluate their ability to generalize to unseen domains and compare their performance with models trained on fully annotated data. Through extensive experiments with three open-source LLMs of varying sizes and two diverse ToD datasets, we find that models fine-tuned without turn-level annotations generate coherent and contextually appropriate responses. However, their task completion performance - measured by accurate execution of API calls - remains suboptimal, with the best models achieving only around 53% success in unseen domains. To improve task completion, we propose ZeroToD, a framework that incorporates a schema augmentation mechanism to enhance API call accuracy and overall task completion rates, particularly in out-of-domain settings. We also compare ZeroToD with fine-tuning-free alternatives, such as prompting off-the-shelf LLMs, and find that our framework enables smaller, fine-tuned models that outperform large-scale proprietary LLMs in task completion. Additionally, a human study evaluating informativeness, fluency, and task completion confirms our empirical findings. These findings suggest the feasibility of developing cost-effective, scalable, and zero-shot generalizable ToD systems for real-world applications.
Natural Language Task-Oriented Dialog System 2.0
Jul 21, 2024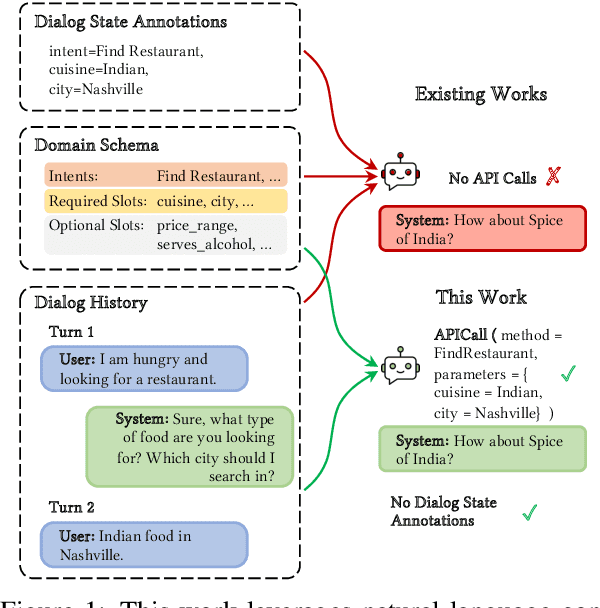



Task-oriented dialog (TOD) systems play a crucial role in facilitating efficient interactions between users and machines by focusing on achieving specific goals through natural language communication. These systems traditionally rely on manually annotated metadata, such as dialog states and policy annotations, which is labor-intensive, expensive, inconsistent, and prone to errors, thereby limiting the potential to leverage the vast amounts of available conversational data. A critical aspect of TOD systems involves accessing and integrating information from external sources to effectively engage users. The process of determining when and how to query external resources represents a fundamental challenge in system design, however existing approaches expect this information to provided in the context. In this paper, we introduce Natural Language Task Oriented Dialog System (NL-ToD), a novel model that removes the dependency on manually annotated turn-wise data by utilizing dialog history and domain schemas to create a Zero Shot Generalizable TOD system. We also incorporate query generation as a core task of the system, where the output of the system could be a response to the user or an API query to communicate with an external resource. To achieve a more granular analysis of the system output, we classify the output into multiple categories: slot filling, retrieval, and query generation. Our analysis reveals that slot filling is the most challenging TOD task for all models. Experimental results on three popular TOD datasets (SGD, KETOD and BiToD) shows the effectiveness of our approach as NL-ToD outperforms state-of-the-art approaches, particularly with a \textbf{31.4\%} and \textbf{82.1\%} improvement in the BLEU-4 score on the SGD and KETOD dataset.