 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multi-turn Task Completion in Task-Oriented Dialog Systems via Prompt Chaining and Fine-Grained Feedback
Feb 18, 2025Task-oriented dialog (TOD) systems facilitate users in accomplishing complex, multi-turn tasks through natural language. While traditional approaches rely on extensive fine-tuning and annotated data for each domain, instruction-tuned large language models (LLMs) offer a more flexible alternative. However, LLMs struggle to reliably handle multi-turn task completion, particularly with accurately generating API calls and adapting to new domains without explicit demonstrations. To address these challenges, we propose RealTOD, a novel framework that enhances TOD systems through prompt chaining and fine-grained feedback mechanisms. Prompt chaining enables zero-shot domain adaptation via a two-stage prompting strategy, eliminating the need for human-curated demonstrations. Meanwhile, the fine-grained feedback mechanism improves task completion by verifying API calls against domain schemas and providing precise corrective feedback when errors are detected. We conduct extensive experiments on the SGD and BiTOD benchmarks using four LLMs. RealTOD improves API accuracy, surpassing AutoTOD by 37.74% on SGD and SimpleTOD by 11.26% on BiTOD. Human evaluations further confirm that LLMs integrated with RealTOD achieve superior task completion, fluency, and informativeness compared to existing methods.
Evaluating and Enhancing Out-of-Domain Generalization of Task-Oriented Dialog Systems for Task Completion without Turn-level Dialog Annotations
Feb 18, 2025
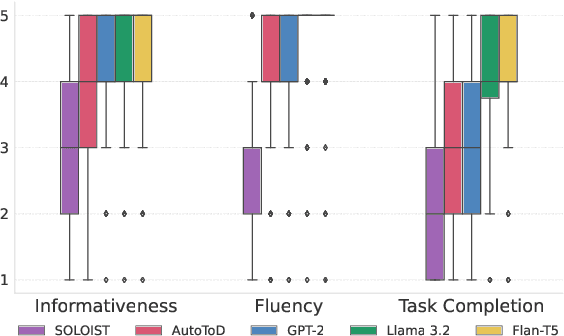
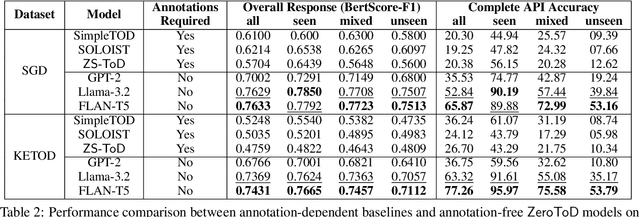

Traditional task-oriented dialog (ToD) systems rely heavily on labor-intensive turn-level annotations, such as dialogue states and policy labels, for training. This work explores whether large language models (LLMs) can be fine-tuned solely on natural language dialogs to perform ToD tasks, without requiring such annotations. We evaluate their ability to generalize to unseen domains and compare their performance with models trained on fully annotated data. Through extensive experiments with three open-source LLMs of varying sizes and two diverse ToD datasets, we find that models fine-tuned without turn-level annotations generate coherent and contextually appropriate responses. However, their task completion performance - measured by accurate execution of API calls - remains suboptimal, with the best models achieving only around 53% success in unseen domains. To improve task completion, we propose ZeroToD, a framework that incorporates a schema augmentation mechanism to enhance API call accuracy and overall task completion rates, particularly in out-of-domain settings. We also compare ZeroToD with fine-tuning-free alternatives, such as prompting off-the-shelf LLMs, and find that our framework enables smaller, fine-tuned models that outperform large-scale proprietary LLMs in task completion. Additionally, a human study evaluating informativeness, fluency, and task completion confirms our empirical findings. These findings suggest the feasibility of developing cost-effective, scalable, and zero-shot generalizable ToD systems for real-world applications.
Natural Language Task-Oriented Dialog System 2.0
Jul 21, 2024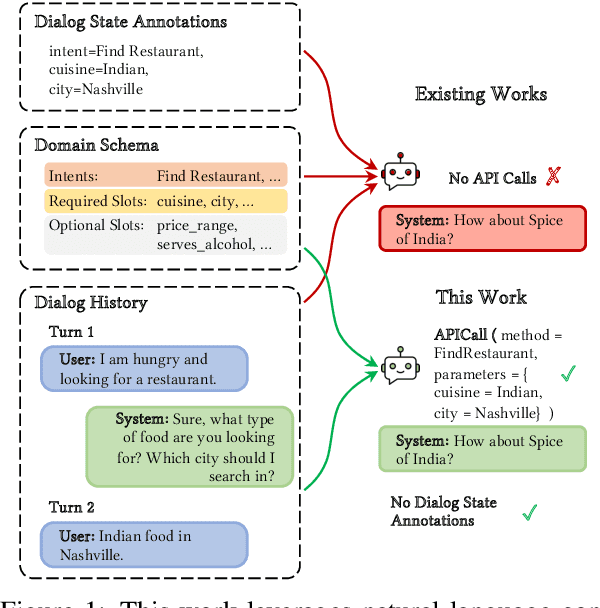



Task-oriented dialog (TOD) systems play a crucial role in facilitating efficient interactions between users and machines by focusing on achieving specific goals through natural language communication. These systems traditionally rely on manually annotated metadata, such as dialog states and policy annotations, which is labor-intensive, expensive, inconsistent, and prone to errors, thereby limiting the potential to leverage the vast amounts of available conversational data. A critical aspect of TOD systems involves accessing and integrating information from external sources to effectively engage users. The process of determining when and how to query external resources represents a fundamental challenge in system design, however existing approaches expect this information to provided in the context. In this paper, we introduce Natural Language Task Oriented Dialog System (NL-ToD), a novel model that removes the dependency on manually annotated turn-wise data by utilizing dialog history and domain schemas to create a Zero Shot Generalizable TOD system. We also incorporate query generation as a core task of the system, where the output of the system could be a response to the user or an API query to communicate with an external resource. To achieve a more granular analysis of the system output, we classify the output into multiple categories: slot filling, retrieval, and query generation. Our analysis reveals that slot filling is the most challenging TOD task for all models. Experimental results on three popular TOD datasets (SGD, KETOD and BiToD) shows the effectiveness of our approach as NL-ToD outperforms state-of-the-art approaches, particularly with a \textbf{31.4\%} and \textbf{82.1\%} improvement in the BLEU-4 score on the SGD and KETOD dataset.
Zero-Shot Generalizable End-to-End Task-Oriented Dialog System using Context Summarization and Domain Schema
Mar 28, 2023Task-oriented dialog systems empower users to accomplish their goals by facilitating intuitive and expressive natural language interactions. State-of-the-art approaches in task-oriented dialog systems formulate the problem as a conditional sequence generation task and fine-tune pre-trained causal language models in the supervised setting. This requires labeled training data for each new domain or task, and acquiring such data is prohibitively laborious and expensive, thus making it a bottleneck for scaling systems to a wide range of domains. To overcome this challenge, we introduce a novel Zero-Shot generalizable end-to-end Task-oriented Dialog system, ZS-ToD, that leverages domain schemas to allow for robust generalization to unseen domains and exploits effective summarization of the dialog history. We employ GPT-2 as a backbone model and introduce a two-step training process where the goal of the first step is to learn the general structure of the dialog data and the second step optimizes the response generation as well as intermediate outputs, such as dialog state and system actions. As opposed to state-of-the-art systems that are trained to fulfill certain intents in the given domains and memorize task-specific conversational patterns, ZS-ToD learns generic task-completion skills by comprehending domain semantics via domain schemas and generalizing to unseen domains seamlessly. We conduct an extensive experimental evaluation on SGD and SGD-X datasets that span up to 20 unique domains and ZS-ToD outperforms state-of-the-art systems on key metrics, with an improvement of +17% on joint goal accuracy and +5 on inform. Additionally, we present a detailed ablation study to demonstrate the effectiveness of the proposed components and training mechanism
Toward Open-domain Slot Filling via Self-supervised Co-training
Mar 24, 2023



Slot filling is one of the critical tasks in modern conversational systems. The majority of existing literature employs supervised learning methods, which require labeled training data for each new domain. Zero-shot learning and weak supervision approaches, among others, have shown promise as alternatives to manual labeling. Nonetheless, these learning paradigms are significantly inferior to supervised learning approaches in terms of performance. To minimize this performance gap and demonstrate the possibility of open-domain slot filling, we propose a Self-supervised Co-training framework, called SCot, that requires zero in-domain manually labeled training examples and works in three phases. Phase one acquires two sets of complementary pseudo labels automatically. Phase two leverages the power of the pre-trained language model BERT, by adapting it for the slot filling task using these sets of pseudo labels. In phase three, we introduce a self-supervised cotraining mechanism, where both models automatically select highconfidence soft labels to further improve the performance of the other in an iterative fashion. Our thorough evaluations show that SCot outperforms state-of-the-art models by 45.57% and 37.56% on SGD and MultiWoZ datasets, respectively. Moreover, our proposed framework SCot achieves comparable performance when compared to state-of-the-art fully supervised models.
MobileRec: A Large-Scale Dataset for Mobile Apps Recommendation
Mar 12, 2023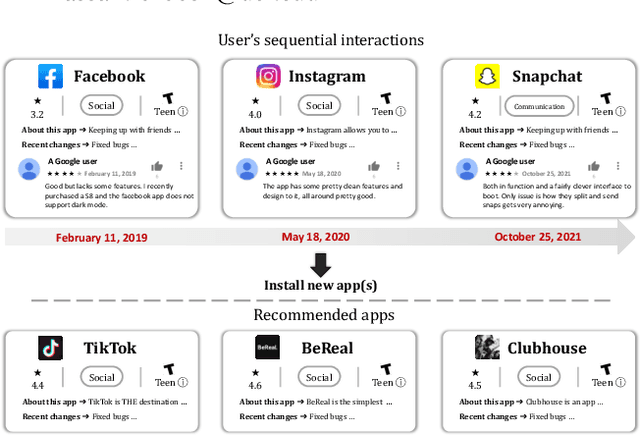


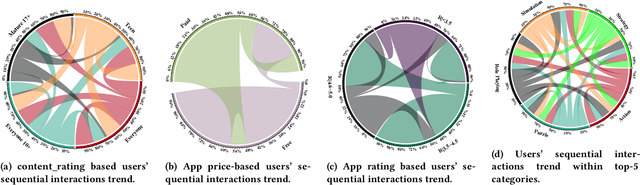
Recommender systems have become ubiquitous in our digital lives, from recommending products on e-commerce websites to suggesting movies and music on streaming platforms. Existing recommendation datasets, such as Amazon Product Reviews and MovieLens, greatly facilitated the research and development of recommender systems in their respective domains. While the number of mobile users and applications (aka apps) has increased exponentially over the past decade, research in mobile app recommender systems has been significantly constrained, primarily due to the lack of high-quality benchmark datasets, as opposed to recommendations for products, movies, and news. To facilitate research for app recommendation systems, we introduce a large-scale dataset, called MobileRec. We constructed MobileRec from users' activity on the Google play store. MobileRec contains 19.3 million user interactions (i.e., user reviews on apps) with over 10K unique apps across 48 categories. MobileRec records the sequential activity of a total of 0.7 million distinct users. Each of these users has interacted with no fewer than five distinct apps, which stands in contrast to previous datasets on mobile apps that recorded only a single interaction per user. Furthermore, MobileRec presents users' ratings as well as sentiments on installed apps, and each app contains rich metadata such as app name, category, description, and overall rating, among others. We demonstrate that MobileRec can serve as an excellent testbed for app recommendation through a comparative study of several state-of-the-art recommendation approaches. The quantitative results can act as a baseline for other researchers to compare their results against. The MobileRec dataset is available at https://huggingface.co/datasets/recmeapp/mobilerec.
Proactive Prioritization of App Issues via Contrastive Learning
Mar 12, 2023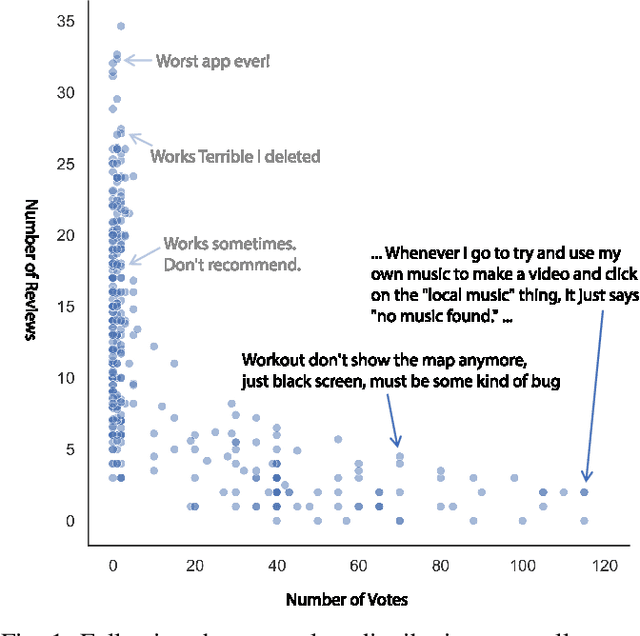
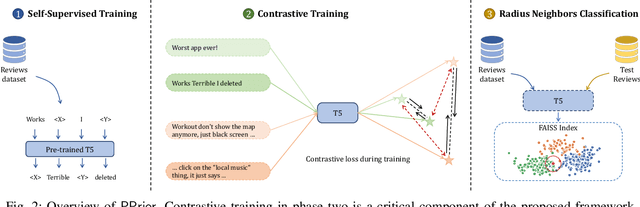
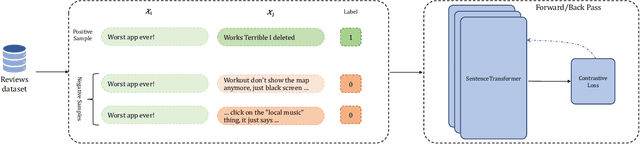
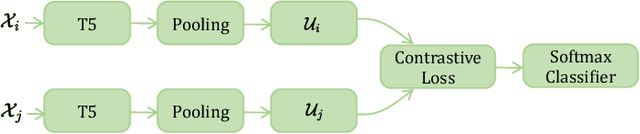
Mobile app stores produce a tremendous amount of data in the form of user reviews, which is a huge source of user requirements and sentiments; such reviews allow app developers to proactively address issues in their apps. However, only a small number of reviews capture common issues and sentiments which creates a need for automatically identifying prominent reviews. Unfortunately, most existing work in text ranking and popularity prediction focuses on social contexts where other signals are available, which renders such works ineffective in the context of app reviews. In this work, we propose a new framework, PPrior, that enables proactive prioritization of app issues through identifying prominent reviews (ones predicted to receive a large number of votes in a given time window). Predicting highly-voted reviews is challenging given that, unlike social posts, social network features of users are not available. Moreover, there is an issue of class imbalance, since a large number of user reviews receive little to no votes. PPrior employs a pre-trained T5 model and works in three phases. Phase one adapts the pre-trained T5 model to the user reviews data in a self-supervised fashion. In phase two, we leverage contrastive training to learn a generic and task-independent representation of user reviews. Phase three uses radius neighbors classifier t o m ake t he final predictions. This phase also uses FAISS index for scalability and efficient search. To conduct extensive experiments, we acquired a large dataset of over 2.1 million user reviews from Google Play. Our experimental results demonstrate the effectiveness of the proposed framework when compared against several state-of-the-art approaches. Moreover, the accuracy of PPrior in predicting prominent reviews is comparable to that of experienced app developers.