 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileDev-Bench: A Comprehensive Benchmark for Evaluating Language Models on Mobile Application Development
Mar 26, 2026Large language models (LLMs) have shown strong performance on automated software engineering tasks, yet existing benchmarks focus primarily on general-purpose libraries or web applications, leaving mobile application development largely unexplored despite its strict platform constraints, framework-driven lifecycles, and complex platform API interactions. We introduce MobileDev-Bench, a benchmark comprising 384 real-world issue-resolution tasks collected from 18 production mobile applications spanning Android Native (Java/Kotlin), React Native (TypeScript), and Flutter (Dart). Each task pairs an authentic developer-reported issue with executable test patches, enabling fully automated validation of model-generated fixes within mobile build environments. The benchmark exhibits substantial patch complexity: fixes modify 12.5 files and 324.9 lines on average, and 35.7% of instances require coordinated changes across multiple artifact types, such as source and manifest files. Evaluation of four state-of-the-art code-capable LLMs, GPT- 5.2, Claude Sonnet 4.5, Gemini Flash 2.5, and Qwen3-Coder, yields low end-to-end resolution rates of 3.39%-5.21%, revealing significant performance gaps compared to prior benchmarks. Further analysis reveals systematic failure modes, with fault localization across multi-file and multi-artifact changes emerging as the primary bottleneck.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
A Large-Scale Study on the Development and Issues of Multi-Agent AI Systems
Jan 12, 2026The rapid emergence of multi-agent AI systems (MAS), including LangChain, CrewAI, and AutoGen, has shaped how large language model (LLM) applications are developed and orchestrated. However, little is known about how these systems evolve and are maintained in practice. This paper presents the first large-scale empirical study of open-source MAS, analyzing over 42K unique commits and over 4.7K resolved issues across eight leading systems. Our analysis identifies three distinct development profiles: sustained, steady, and burst-driven. These profiles reflect substantial variation in ecosystem maturity. Perfective commits constitute 40.8% of all changes, suggesting that feature enhancement is prioritized over corrective maintenance (27.4%) and adaptive updates (24.3%). Data about issues shows that the most frequent concerns involve bugs (22%), infrastructure (14%), and agent coordination challenges (10%). Issue reporting also increased sharply across all frameworks starting in 2023. Median resolution times range from under one day to about two weeks, with distributions skewed toward fast responses but a minority of issues requiring extended attention. These results highlight both the momentum and the fragility of the current ecosystem, emphasizing the need for improved testing infrastructure, documentation quality, and maintenance practices to ensure long-term reliability and sustainability.
INTERPOS: Interaction Rhythm Guided Positional Morphing for Mobile App Recommender Systems
Jun 14, 2025The mobile app market has expanded exponentially, offering millions of apps with diverse functionalities, yet research in mobile app recommendation remains limited. Traditional sequential recommender systems utilize the order of items in users' historical interactions to predict the next item for the users. Position embeddings, well-established in transformer-based architectures for natural language processing tasks, effectively distinguish token positions in sequences. In sequential recommendation systems, position embeddings can capture the order of items in a user's historical interaction sequence. Nevertheless, this ordering does not consider the time elapsed between two interactions of the same user (e.g., 1 day, 1 week, 1 month), referred to as "user rhythm". In mobile app recommendation datasets, the time between consecutive user interactions is notably longer compared to other domains like movies, posing significant challenges for sequential recommender systems. To address this phenomenon in the mobile app domain, we introduce INTERPOS, an Interaction Rhythm Guided Positional Morphing strategy for autoregressive mobile app recommender systems. INTERPOS incorporates rhythm-guided position embeddings, providing a more comprehensive representation that considers both the sequential order of interactions and the temporal gaps between them. This approach enables a deep understanding of users' rhythms at a fine-grained level, capturing the intricacies of their interaction patterns over time. We propose three strategies to incorporate the morphed positional embeddings in two transformer-based sequential recommendation system architectures. Our extensive evaluations show that INTERPOS outperforms state-of-the-art models using 7 mobile app recommendation datasets on NDCG@K and HIT@K metrics. The source code of INTERPOS is available at https://github.com/dlgrad/INTERPOS.
* 10 pages, 8 tables, 3 figures
What Users Value and Critique: Large-Scale Analysis of User Feedback on AI-Powered Mobile Apps
Jun 12, 2025
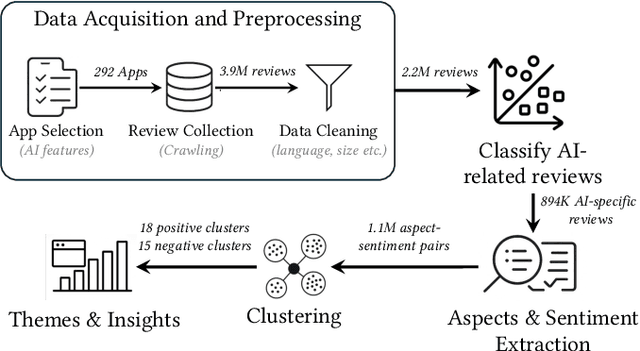
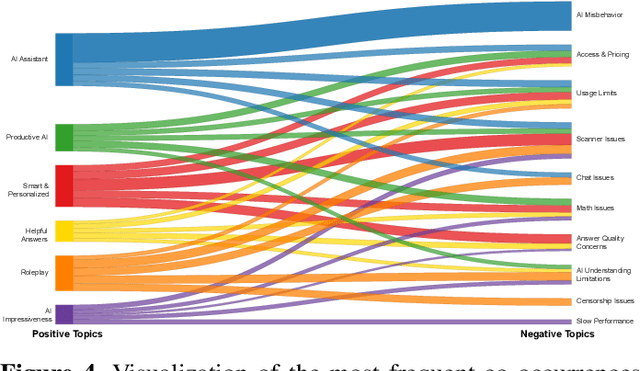
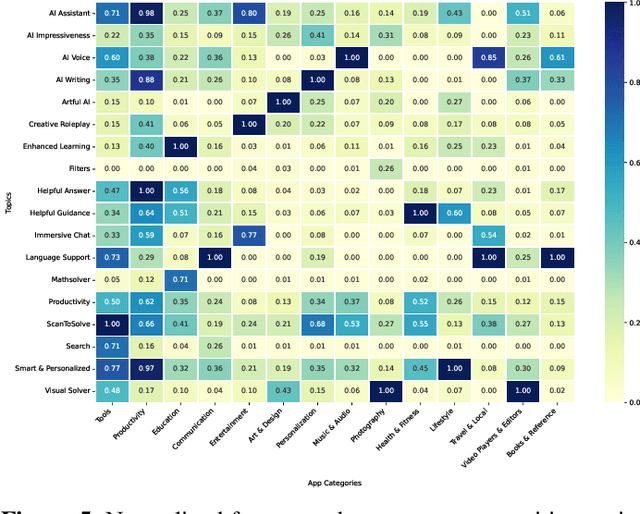
Artificial Intelligence (AI)-powered features have rapidly proliferated across mobile apps in various domains, including productivity, education, entertainment, and creativity. However, how users perceive, evaluate, and critique these AI features remains largely unexplored, primarily due to the overwhelming volume of user feedback. In this work, we present the first comprehensive, large-scale study of user feedback on AI-powered mobile apps, leveraging a curated dataset of 292 AI-driven apps across 14 categories with 894K AI-specific reviews from Google Play. We develop and validate a multi-stage analysis pipeline that begins with a human-labeled benchmark and systematically evaluates large language models (LLMs) and prompting strategies. Each stage, including review classification, aspect-sentiment extraction, and clustering, is validated for accuracy and consistency. Our pipeline enables scalable, high-precision analysis of user feedback, extracting over one million aspect-sentiment pairs clustered into 18 positive and 15 negative user topics. Our analysis reveals that users consistently focus on a narrow set of themes: positive comments emphasize productivity, reliability, and personalized assistance, while negative feedback highlights technical failures (e.g., scanning and recognition), pricing concerns, and limitations in language support. Our pipeline surfaces both satisfaction with one feature and frustration with another within the same review. These fine-grained, co-occurring sentiments are often missed by traditional approaches that treat positive and negative feedback in isolation or rely on coarse-grained analysis. To this end, our approach provides a more faithful reflection of the real-world user experiences with AI-powered apps. Category-aware analysis further uncovers both universal drivers of satisfaction and domain-specific frustrations.
Optimized 3D Gaussian Splatting using Coarse-to-Fine Image Frequency Modulation
Mar 18, 2025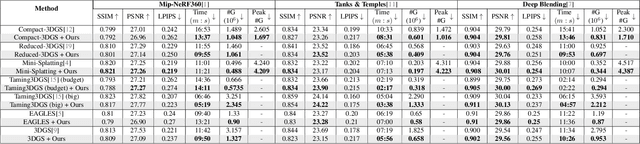
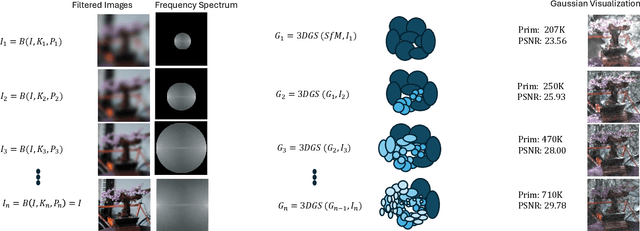
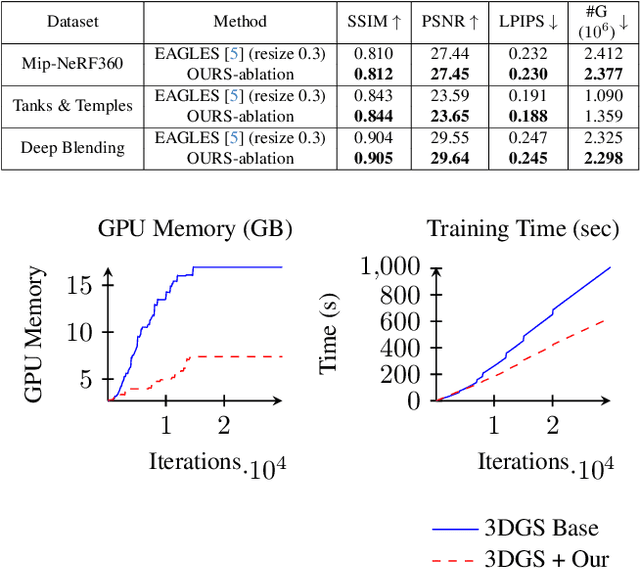

The field of Novel View Synthesis has been revolutionized by 3D Gaussian Splatting (3DGS), which enables high-quality scene reconstruction that can be rendered in real-time. 3DGS-based techniques typically suffer from high GPU memory and disk storage requirements which limits their practical application on consumer-grade devices. We propose Opti3DGS, a novel frequency-modulated coarse-to-fine optimization framework that aims to minimize the number of Gaussian primitives used to represent a scene, thus reducing memory and storage demands. Opti3DGS leverages image frequency modulation, initially enforcing a coarse scene representation and progressively refining it by modulating frequency details in the training images. On the baseline 3DGS, we demonstrate an average reduction of 62% in Gaussians, a 40% reduction in the training GPU memory requirements and a 20% reduction in optimization time without sacrificing the visual quality. Furthermore, we show that our method integrates seamlessly with many 3DGS-based techniques, consistently reducing the number of Gaussian primitives while maintaining, and often improving, visual quality. Additionally, Opti3DGS inherently produces a level-of-detail scene representation at no extra cost, a natural byproduct of the optimization pipeline. Results and code will be made publicly available.
Looking into Black Box Code Language Models
Jul 05, 2024



Language Models (LMs) have shown their application for tasks pertinent to code and several code~LMs have been proposed recently. The majority of the studies in this direction only focus on the improvements in performance of the LMs on different benchmarks, whereas LMs are considered black boxes. Besides this, a handful of works attempt to understand the role of attention layers in the code~LMs. Nonetheless, feed-forward layers remain under-explored which consist of two-thirds of a typical transformer model's parameters. In this work, we attempt to gain insights into the inner workings of code language models by examining the feed-forward layers. To conduct our investigations, we use two state-of-the-art code~LMs, Codegen-Mono and Ploycoder, and three widely used programming languages, Java, Go, and Python. We focus on examining the organization of stored concepts, the editability of these concepts, and the roles of different layers and input context size variations for output generation. Our empirical findings demonstrate that lower layers capture syntactic patterns while higher layers encode abstract concepts and semantics. We show concepts of interest can be edited within feed-forward layers without compromising code~LM performance. Additionally, we observe initial layers serve as ``thinking'' layers, while later layers are crucial for predicting subsequent code tokens. Furthermore, we discover earlier layers can accurately predict smaller contexts, but larger contexts need critical later layers' contributions. We anticipate these findings will facilitate better understanding, debugging, and testing of code~LMs.
MobileConvRec: A Conversational Dataset for Mobile Apps Recommendations
May 28, 2024Existing recommendation systems have focused on two paradigms: 1- historical user-item interaction-based recommendations and 2- conversational recommendations. Conversational recommendation systems facilitate natural language dialogues between users and the system, allowing the system to solicit users' explicit needs while enabling users to inquire about recommendations and provide feedback. Due to substantial advancements in natural language processing, conversational recommendation systems have gained prominence. Existing conversational recommendation datasets have greatly facilitated research in their respective domains. Despite the exponential growth in mobile users and apps in recent years, research in conversational mobile app recommender systems has faced substantial constraints. This limitation can primarily be attributed to the lack of high-quality benchmark datasets specifically tailored for mobile apps. To facilitate research for conversational mobile app recommendations, we introduce MobileConvRec. MobileConvRec simulates conversations by leveraging real user interactions with mobile apps on the Google Play store, originally captured in large-scale mobile app recommendation dataset MobileRec. The proposed conversational recommendation dataset synergizes sequential user-item interactions, which reflect implicit user preferences, with comprehensive multi-turn conversations to effectively grasp explicit user needs. MobileConvRec consists of over 12K multi-turn recommendation-related conversations spanning 45 app categories. Moreover, MobileConvRec presents rich metadata for each app such as permissions data, security and privacy-related information, and binary executables of apps, among others. We demonstrate that MobileConvRec can serve as an excellent testbed for conversational mobile app recommendation through a comparative study of several pre-trained large language models.
Proactive Prioritization of App Issues via Contrastive Learning
Mar 12, 2023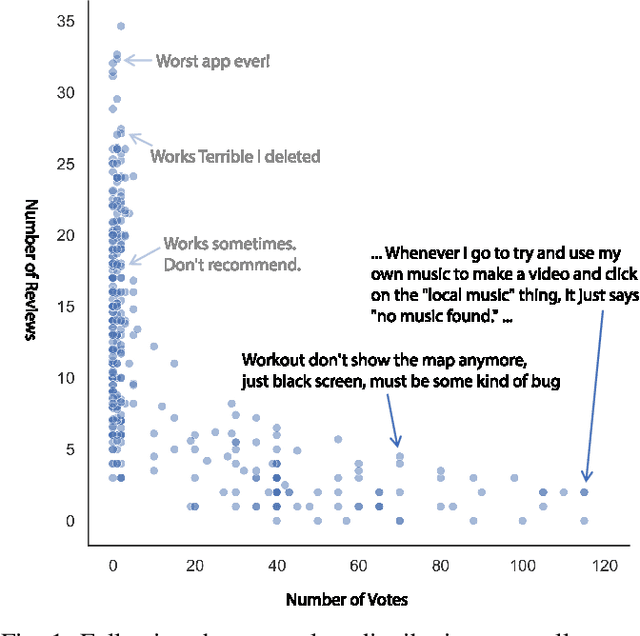
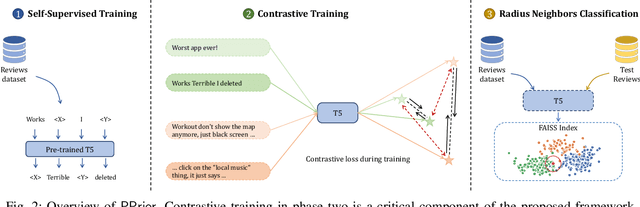
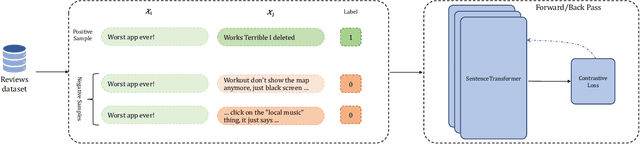
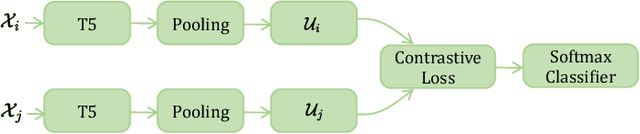
Mobile app stores produce a tremendous amount of data in the form of user reviews, which is a huge source of user requirements and sentiments; such reviews allow app developers to proactively address issues in their apps. However, only a small number of reviews capture common issues and sentiments which creates a need for automatically identifying prominent reviews. Unfortunately, most existing work in text ranking and popularity prediction focuses on social contexts where other signals are available, which renders such works ineffective in the context of app reviews. In this work, we propose a new framework, PPrior, that enables proactive prioritization of app issues through identifying prominent reviews (ones predicted to receive a large number of votes in a given time window). Predicting highly-voted reviews is challenging given that, unlike social posts, social network features of users are not available. Moreover, there is an issue of class imbalance, since a large number of user reviews receive little to no votes. PPrior employs a pre-trained T5 model and works in three phases. Phase one adapts the pre-trained T5 model to the user reviews data in a self-supervised fashion. In phase two, we leverage contrastive training to learn a generic and task-independent representation of user reviews. Phase three uses radius neighbors classifier t o m ake t he final predictions. This phase also uses FAISS index for scalability and efficient search. To conduct extensive experiments, we acquired a large dataset of over 2.1 million user reviews from Google Play. Our experimental results demonstrate the effectiveness of the proposed framework when compared against several state-of-the-art approaches. Moreover, the accuracy of PPrior in predicting prominent reviews is comparable to that of experienced app developers.
MobileRec: A Large-Scale Dataset for Mobile Apps Recommendation
Mar 12, 2023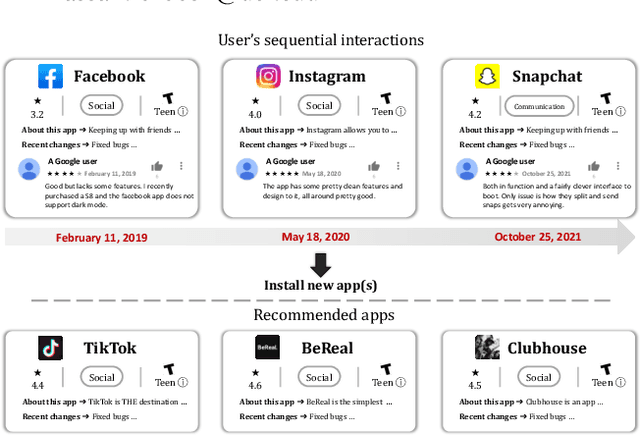


Recommender systems have become ubiquitous in our digital lives, from recommending products on e-commerce websites to suggesting movies and music on streaming platforms. Existing recommendation datasets, such as Amazon Product Reviews and MovieLens, greatly facilitated the research and development of recommender systems in their respective domains. While the number of mobile users and applications (aka apps) has increased exponentially over the past decade, research in mobile app recommender systems has been significantly constrained, primarily due to the lack of high-quality benchmark datasets, as opposed to recommendations for products, movies, and news. To facilitate research for app recommendation systems, we introduce a large-scale dataset, called MobileRec. We constructed MobileRec from users' activity on the Google play store. MobileRec contains 19.3 million user interactions (i.e., user reviews on apps) with over 10K unique apps across 48 categories. MobileRec records the sequential activity of a total of 0.7 million distinct users. Each of these users has interacted with no fewer than five distinct apps, which stands in contrast to previous datasets on mobile apps that recorded only a single interaction per user. Furthermore, MobileRec presents users' ratings as well as sentiments on installed apps, and each app contains rich metadata such as app name, category, description, and overall rating, among others. We demonstrate that MobileRec can serve as an excellent testbed for app recommendation through a comparative study of several state-of-the-art recommendation approaches. The quantitative results can act as a baseline for other researchers to compare their results against. The MobileRec dataset is available at https://huggingface.co/datasets/recmeapp/mobilerec.