 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Zero-shot Intent Detection via Commonsense Knowledge
Feb 04, 2021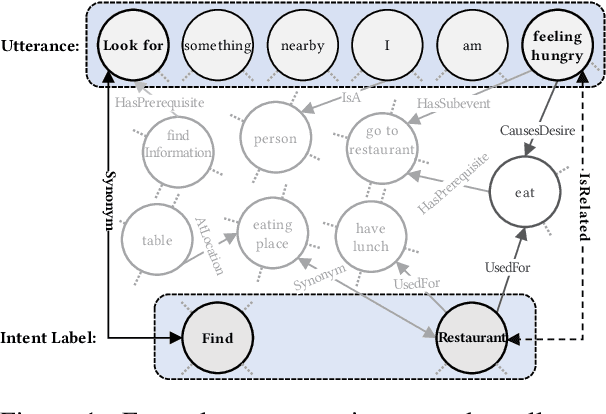
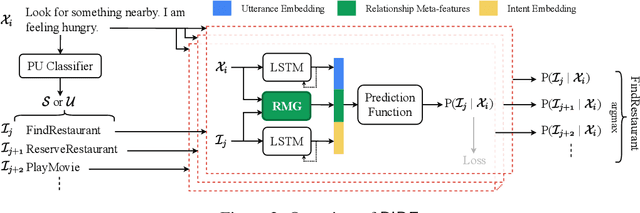
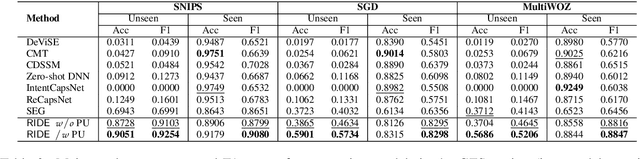
Identifying user intents from natural language utterances is a crucial step in conversational systems that has been extensively studied as a supervised classification problem. However, in practice, new intents emerge after deploying an intent detection model. Thus, these models should seamlessly adapt and classify utterances with both seen and unseen intents -- unseen intents emerge after deployment and they do not have training data. The few existing models that target this setting rely heavily on the scarcely available training data and overfit to seen intents data, resulting in a bias to misclassify utterances with unseen intents into seen ones. We propose RIDE: an intent detection model that leverages commonsense knowledge in an unsupervised fashion to overcome the issue of training data scarcity. RIDE computes robust and generalizable relationship meta-features that capture deep semantic relationships between utterances and intent labels; these features are computed by considering how the concepts in an utterance are linked to those in an intent label via commonsense knowledge. Our extensive experimental analysis on three widely-used intent detection benchmarks shows that relationship meta-features significantly increase the accuracy of detecting both seen and unseen intents and that RIDE outperforms the state-of-the-art model for unseen intents.
Linguistically-Enriched and Context-Aware Zero-shot Slot Filling
Jan 16, 2021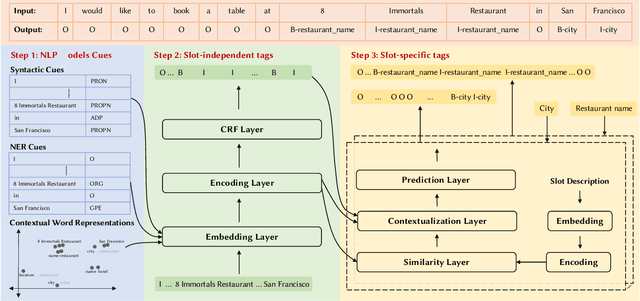
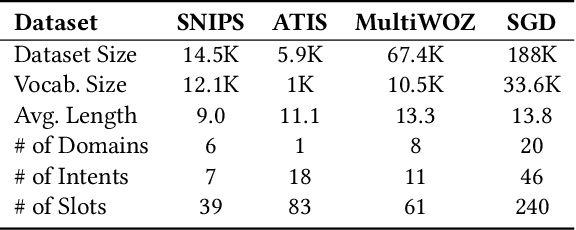
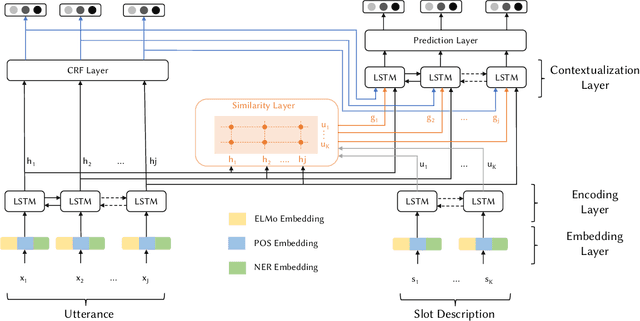
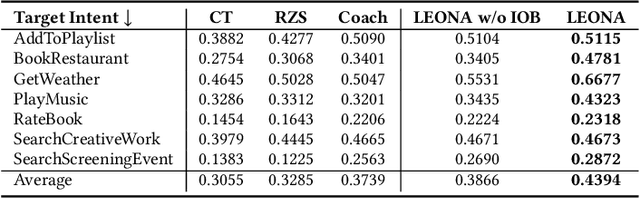
Slot filling is identifying contiguous spans of words in an utterance that correspond to certain parameters (i.e., slots) of a user request/query. Slot filling is one of the most important challenges in modern task-oriented dialog systems. Supervised learning approaches have proven effective at tackling this challenge, but they need a significant amount of labeled training data in a given domain. However, new domains (i.e., unseen in training) may emerge after deployment. Thus, it is imperative that these models seamlessly adapt and fill slots from both seen and unseen domains -- unseen domains contain unseen slot types with no training data, and even seen slots in unseen domains are typically presented in different contexts. This setting is commonly referred to as zero-shot slot filling. Little work has focused on this setting, with limited experimental evaluation. Existing models that mainly rely on context-independent embedding-based similarity measures fail to detect slot values in unseen domains or do so only partially. We propose a new zero-shot slot filling neural model, LEONA, which works in three steps. Step one acquires domain-oblivious, context-aware representations of the utterance word by exploiting (a) linguistic features; (b) named entity recognition cues; (c) contextual embeddings from pre-trained language models. Step two fine-tunes these rich representations and produces slot-independent tags for each word. Step three exploits generalizable context-aware utterance-slot similarity features at the word level, uses slot-independent tags, and contextualizes them to produce slot-specific predictions for each word. Our thorough evaluation on four diverse public datasets demonstrates that our approach consistently outperforms the SOTA models by 17.52%, 22.15%, 17.42%, and 17.95% on average for unseen domains on SNIPS, ATIS, MultiWOZ, and SGD datasets, respectively.
AARSynth: App-Aware Response Synthesis for User Reviews
Aug 28, 2020Responding to user reviews promptly and satisfactorily improves application ratings, which is key to application popularity and success. The proliferation of such reviews makes it virtually impossible for developers to keep up with responding manually. To address this challenge, recent work has shown the possibility of automatic response generation. However, because the training review-response pairs are aggregated from many different apps, it remains challenging for such models to generate app-specific responses, which, on the other hand, are often desirable as apps have different features and concerns. Solving the challenge by simply building a model per app (i.e., training with review-response pairs of a single app) may be insufficient because individual apps have limited review-response pairs, and such pairs typically lack the relevant information needed to respond to a new review. To enable app-specific response generation, this work proposes AARSynth: an app-aware response synthesis system. The key idea behind AARSynth is to augment the seq2seq model with information specific to a given app. Given a new user review, it first retrieves the top-K most relevant app reviews and the most relevant snippet from the app description. The retrieved information and the new user review are then fed into a fused machine learning model that integrates the seq2seq model with a machine reading comprehension model. The latter helps digest the retrieved reviews and app description. Finally, the fused model generates a response that is customized to the given app. We evaluated AARSynth using a large corpus of reviews and responses from Google Play. The results show that AARSynth outperforms the state-of-the-art system by 22.2% on BLEU-4 score. Furthermore, our human study shows that AARSynth produces a statistically significant improvement in response quality compared to the state-of-the-art system.