 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection, Classification and Prevalence of Self-Admitted Aging Debt
Apr 24, 2025Context: Previous research on software aging is limited with focus on dynamic runtime indicators like memory and performance, often neglecting evolutionary indicators like source code comments and narrowly examining legacy issues within the TD context. Objective: We introduce the concept of Aging Debt (AD), representing the increased maintenance efforts and costs needed to keep software updated. We study AD through Self-Admitted Aging Debt (SAAD) observed in source code comments left by software developers. Method: We employ a mixed-methods approach, combining qualitative and quantitative analyses to detect and measure AD in software. This includes framing SAAD patterns from the source code comments after analysing the source code context, then utilizing the SAAD patterns to detect SAAD comments. In the process, we develop a taxonomy for SAAD that reflects the temporal aging of software and its associated debt. Then we utilize the taxonomy to quantify the different types of AD prevalent in OSS repositories. Results: Our proposed taxonomy categorizes temporal software aging into Active and Dormant types. Our extensive analysis of over 9,000+ Open Source Software (OSS) repositories reveals that more than 21% repositories exhibit signs of SAAD as observed from our gold standard SAAD dataset. Notably, Dormant AD emerges as the predominant category, highlighting a critical but often overlooked aspect of software maintenance. Conclusion: As software volume grows annually, so do evolutionary aging and maintenance challenges; our proposed taxonomy can aid researchers in detailed software aging studies and help practitioners develop improved and proactive maintenance strategies.
The Promise and Challenges of Using LLMs to Accelerate the Screening Process of Systematic Reviews
Apr 26, 2024
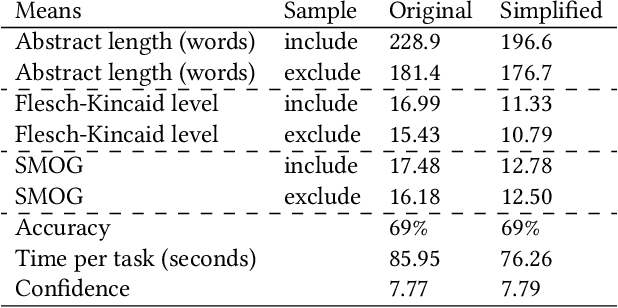
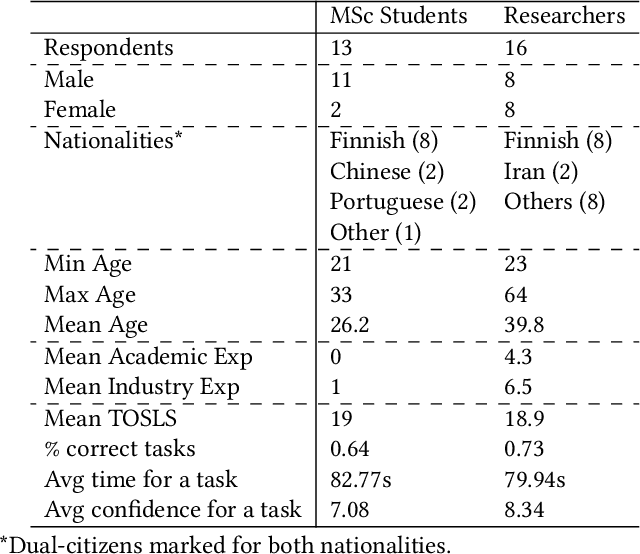
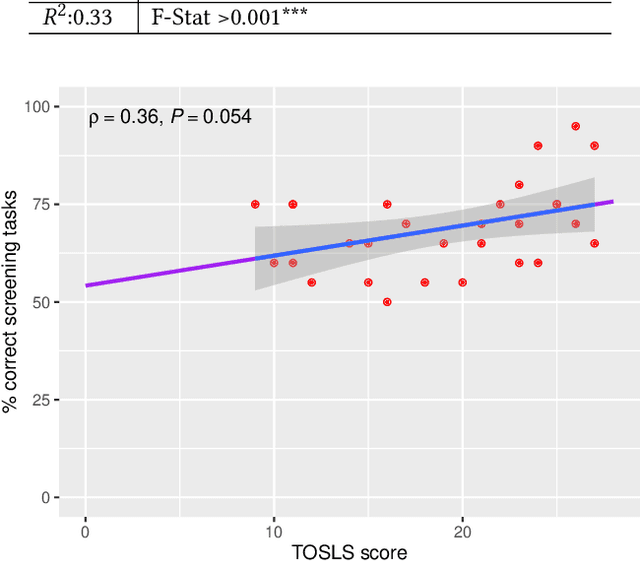
Systematic review (SR) is a popular research method in software engineering (SE). However, conducting an SR takes an average of 67 weeks. Thus, automating any step of the SR process could reduce the effort associated with SRs. Our objective is to investigate if Large Language Models (LLMs) can accelerate title-abstract screening by simplifying abstracts for human screeners, and automating title-abstract screening. We performed an experiment where humans screened titles and abstracts for 20 papers with both original and simplified abstracts from a prior SR. The experiment with human screeners was reproduced with GPT-3.5 and GPT-4 LLMs to perform the same screening tasks. We also studied if different prompting techniques (Zero-shot (ZS), One-shot (OS), Few-shot (FS), and Few-shot with Chain-of-Thought (FS-CoT)) improve the screening performance of LLMs. Lastly, we studied if redesigning the prompt used in the LLM reproduction of screening leads to improved performance. Text simplification did not increase the screeners' screening performance, but reduced the time used in screening. Screeners' scientific literacy skills and researcher status predict screening performance. Some LLM and prompt combinations perform as well as human screeners in the screening tasks. Our results indicate that the GPT-4 LLM is better than its predecessor, GPT-3.5. Additionally, Few-shot and One-shot prompting outperforms Zero-shot prompting. Using LLMs for text simplification in the screening process does not significantly improve human performance. Using LLMs to automate title-abstract screening seems promising, but current LLMs are not significantly more accurate than human screeners. To recommend the use of LLMs in the screening process of SRs, more research is needed. We recommend future SR studies publish replication packages with screening data to enable more conclusive experimenting with LLM screening.
LogLead -- Fast and Integrated Log Loader, Enhancer, and Anomaly Detector
Nov 20, 2023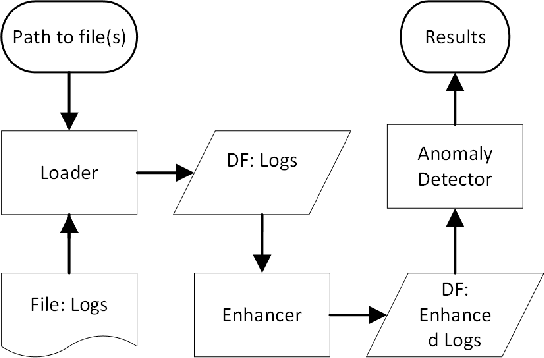
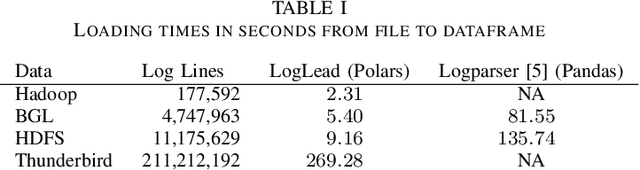

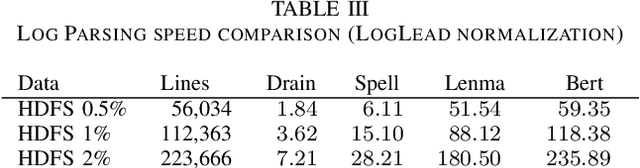
This paper introduces LogLead, a tool designed for efficient log analysis. LogLead combines three essential steps in log processing: loading, enhancing, and anomaly detection. The tool leverages Polars, a high-speed DataFrame library. We currently have 7 Loaders out of which 4 is for public data sets (HDFS, Hadoop, BGL, and Thunderbird). We have multiple enhancers with three parsers (Drain, Spell, LenMa), Bert embedding creation and other log representation techniques like bag-of-words. LogLead integrates to 5 supervised and 4 unsupervised machine learning algorithms for anomaly detection from SKLearn. By integrating diverse datasets, log representation methods and anomaly detectors, LogLead facilitates comprehensive benchmarking in log analysis research. We demonstrate that log loading from raw file to dataframe is over 10x faster with LogLead is compared to past solutions. We demonstrate roughly 2x improvement in Drain parsing speed by off-loading log message normalization to LogLead. We demonstrate a brief benchmarking on HDFS suggesting that log representations beyond bag-of-words provide limited benefits. Screencast demonstrating the tool: https://youtu.be/8stdbtTfJVo
PENTACET data -- 23 Million Contextual Code Comments and 500,000 SATD comments
Mar 24, 2023Most Self-Admitted Technical Debt (SATD) research utilizes explicit SATD features such as 'TODO' and 'FIXME' for SATD detection. A closer look reveals several SATD research uses simple SATD ('Easy to Find') code comments without the contextual data (preceding and succeeding source code context). This work addresses this gap through PENTACET (or 5C dataset) data. PENTACET is a large Curated Contextual Code Comments per Contributor and the most extensive SATD data. We mine 9,096 Open Source Software Java projects with a total of 435 million LOC. The outcome is a dataset with 23 million code comments, preceding and succeeding source code context for each comment, and more than 500,000 comments labeled as SATD, including both 'Easy to Find' and 'Hard to Find' SATD. We believe PENTACET data will further SATD research using Artificial Intelligence techniques.
OneLog: Towards End-to-End Training in Software Log Anomaly Detection
Apr 15, 2021
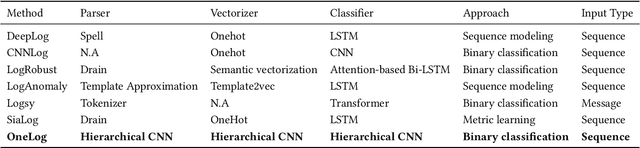


In recent years, with the growth of online services and IoT devices, software log anomaly detection has become a significant concern for both academia and industry. However, at the time of writing this paper, almost all contributions to the log anomaly detection task, follow the same traditional architecture based on parsing, vectorizing, and classifying. This paper proposes OneLog, a new approach that uses a large deep model based on instead of multiple small components. OneLog utilizes a character-based convolutional neural network (CNN) originating from traditional NLP tasks. This allows the model to take advantage of multiple datasets at once and take advantage of numbers and punctuations, which were removed in previous architectures. We evaluate OneLog using four open data sets Hadoop Distributed File System (HDFS), BlueGene/L (BGL), Hadoop, and OpenStack. We evaluate our model with single and multi-project datasets. Additionally, we evaluate robustness with synthetically evolved datasets and ahead-of-time anomaly detection test that indicates capabilities to predict anomalies before occurring. To the best of our knowledge, our multi-project model outperforms state-of-the-art methods in HDFS, Hadoop, and BGL datasets, respectively setting getting F1 scores of 99.99, 99.99, and 99.98. However, OneLog's performance on the Openstack is unsatisfying with F1 score of only 21.18. Furthermore, Onelogs performance suffers very little from noise showing F1 scores of 99.95, 99.92, and 99.98 in HDFS, Hadoop, and BGL.
Measuring LDA Topic Stability from Clusters of Replicated Runs
Aug 24, 2018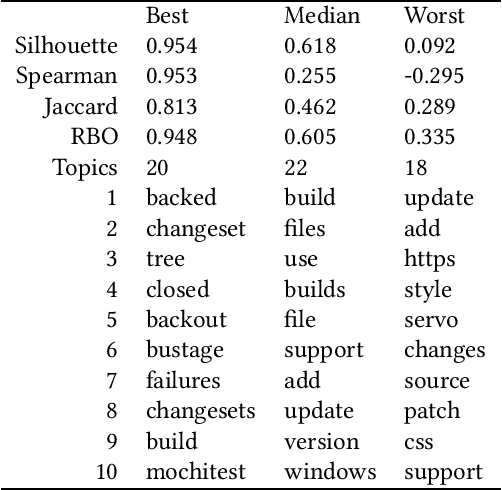
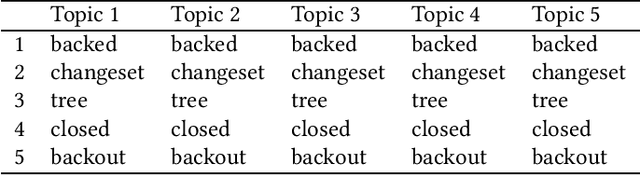
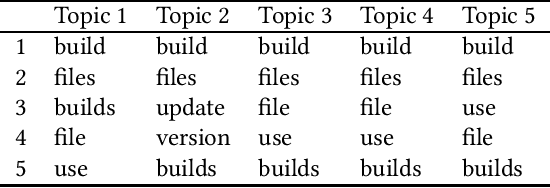
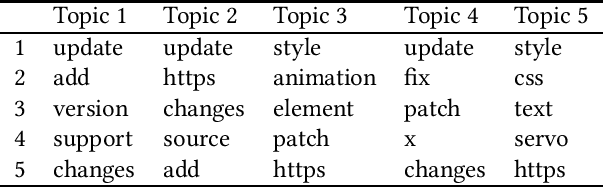
Background: Unstructured and textual data is increasing rapidly and Latent Dirichlet Allocation (LDA) topic modeling is a popular data analysis methods for it. Past work suggests that instability of LDA topics may lead to systematic errors. Aim: We propose a method that relies on replicated LDA runs, clustering, and providing a stability metric for the topics. Method: We generate k LDA topics and replicate this process n times resulting in n*k topics. Then we use K-medioids to cluster the n*k topics to k clusters. The k clusters now represent the original LDA topics and we present them like normal LDA topics showing the ten most probable words. For the clusters, we try multiple stability metrics, out of which we recommend Rank-Biased Overlap, showing the stability of the topics inside the clusters. Results: We provide an initial validation where our method is used for 270,000 Mozilla Firefox commit messages with k=20 and n=20. We show how our topic stability metrics are related to the contents of the topics. Conclusions: Advances in text mining enable us to analyze large masses of text in software engineering but non-deterministic algorithms, such as LDA, may lead to unreplicable conclusions. Our approach makes LDA stability transparent and is also complementary rather than alternative to many prior works that focus on LDA parameter tuning.