 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Promise and Challenges of Using LLMs to Accelerate the Screening Process of Systematic Reviews
Apr 26, 2024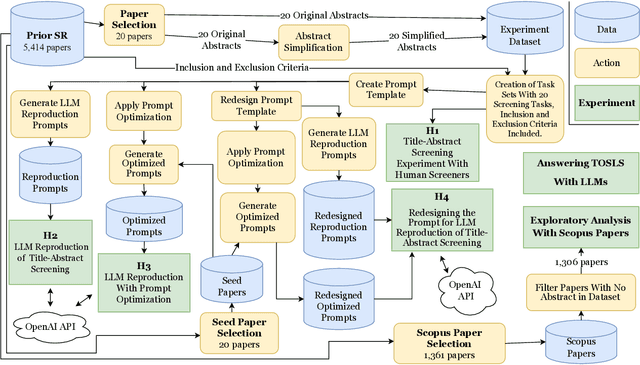
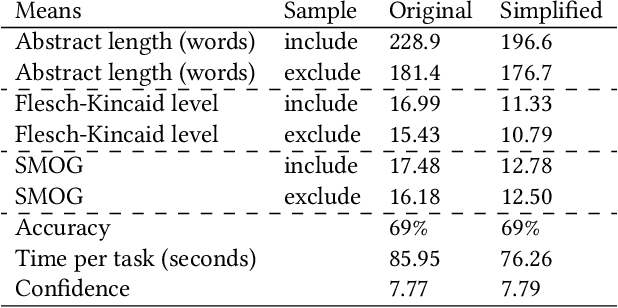
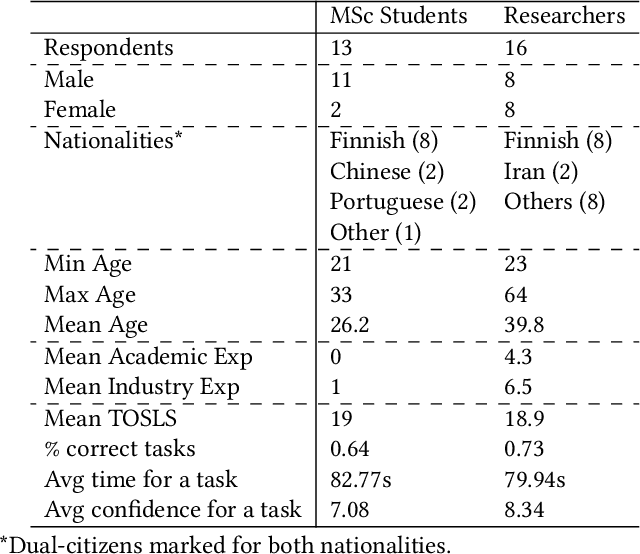
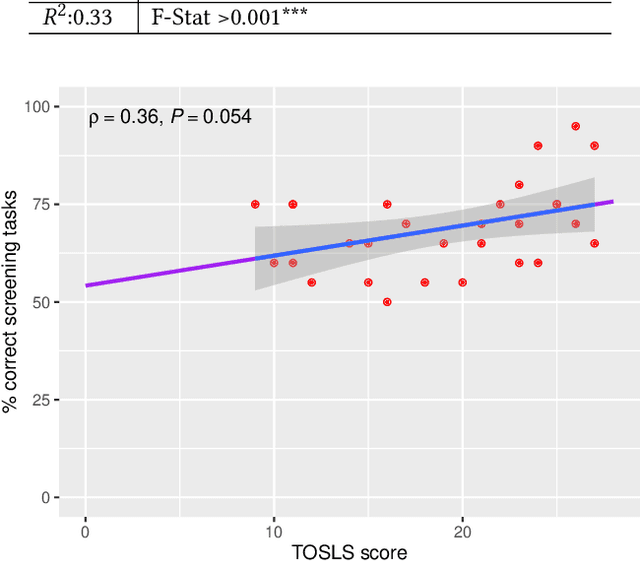
Systematic review (SR) is a popular research method in software engineering (SE). However, conducting an SR takes an average of 67 weeks. Thus, automating any step of the SR process could reduce the effort associated with SRs. Our objective is to investigate if Large Language Models (LLMs) can accelerate title-abstract screening by simplifying abstracts for human screeners, and automating title-abstract screening. We performed an experiment where humans screened titles and abstracts for 20 papers with both original and simplified abstracts from a prior SR. The experiment with human screeners was reproduced with GPT-3.5 and GPT-4 LLMs to perform the same screening tasks. We also studied if different prompting techniques (Zero-shot (ZS), One-shot (OS), Few-shot (FS), and Few-shot with Chain-of-Thought (FS-CoT)) improve the screening performance of LLMs. Lastly, we studied if redesigning the prompt used in the LLM reproduction of screening leads to improved performance. Text simplification did not increase the screeners' screening performance, but reduced the time used in screening. Screeners' scientific literacy skills and researcher status predict screening performance. Some LLM and prompt combinations perform as well as human screeners in the screening tasks. Our results indicate that the GPT-4 LLM is better than its predecessor, GPT-3.5. Additionally, Few-shot and One-shot prompting outperforms Zero-shot prompting. Using LLMs for text simplification in the screening process does not significantly improve human performance. Using LLMs to automate title-abstract screening seems promising, but current LLMs are not significantly more accurate than human screeners. To recommend the use of LLMs in the screening process of SRs, more research is needed. We recommend future SR studies publish replication packages with screening data to enable more conclusive experimenting with LLM screening.
The Evolution of Sentiment Analysis - A Review of Research Topics, Venues, and Top Cited Papers
Nov 21, 2017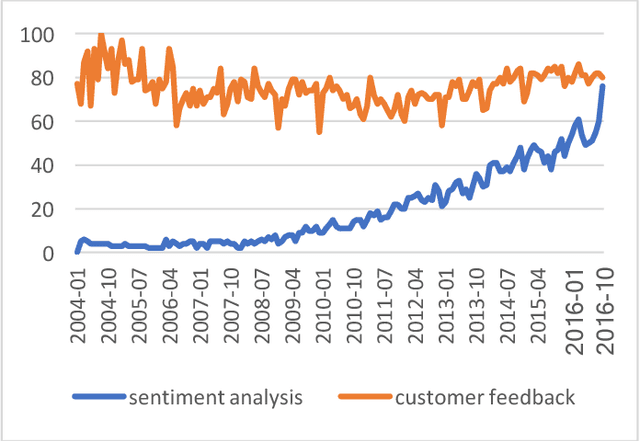
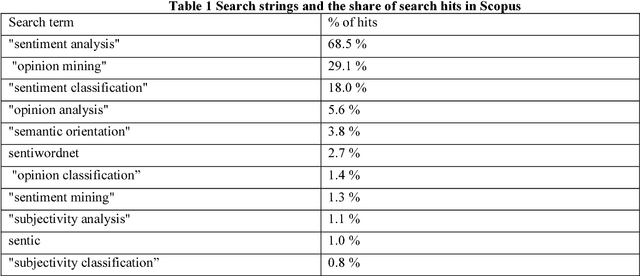


Sentiment analysis is one of the fastest growing research areas in computer science, making it challenging to keep track of all the activities in the area. We present a computer-assisted literature review, where we utilize both text mining and qualitative coding, and analyze 6,996 papers from Scopus. We find that the roots of sentiment analysis are in the studies on public opinion analysis at the beginning of 20th century and in the text subjectivity analysis performed by the computational linguistics community in 1990's. However, the outbreak of computer-based sentiment analysis only occurred with the availability of subjective texts on the Web. Consequently, 99% of the papers have been published after 2004. Sentiment analysis papers are scattered to multiple publication venues, and the combined number of papers in the top-15 venues only represent ca. 30% of the papers in total. We present the top-20 cited papers from Google Scholar and Scopus and a taxonomy of research topics. In recent years, sentiment analysis has shifted from analyzing online product reviews to social media texts from Twitter and Facebook. Many topics beyond product reviews like stock markets, elections, disasters, medicine, software engineering and cyberbullying extend the utilization of sentiment analysis
* 29 pages, 14 figures
Bootstrapping a Lexicon for Emotional Arousal in Software Engineering
Mar 27, 2017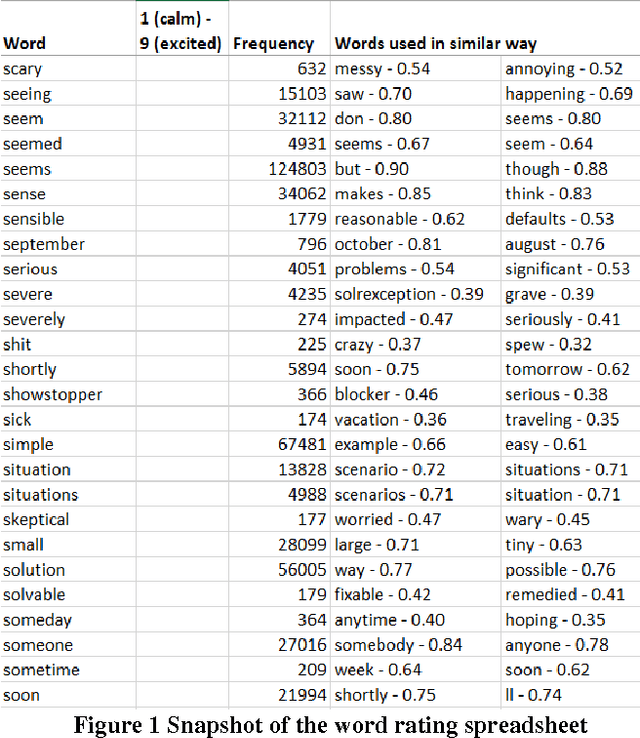
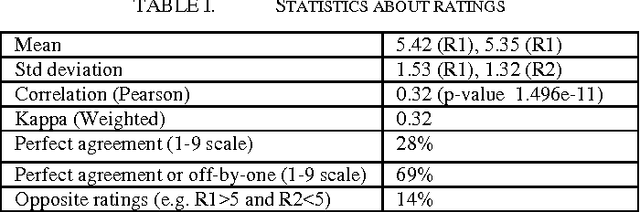
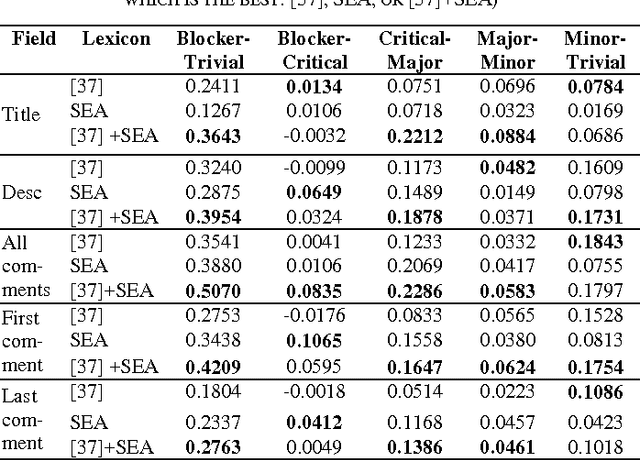
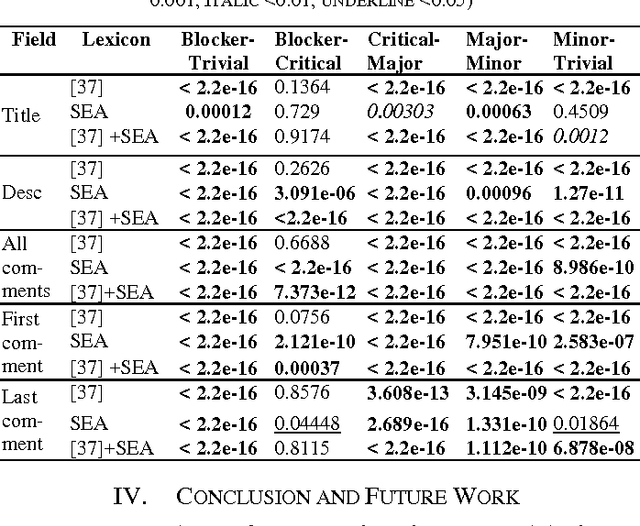
Emotional arousal increases activation and performance but may also lead to burnout in software development. We present the first version of a Software Engineering Arousal lexicon (SEA) that is specifically designed to address the problem of emotional arousal in the software developer ecosystem. SEA is built using a bootstrapping approach that combines word embedding model trained on issue-tracking data and manual scoring of items in the lexicon. We show that our lexicon is able to differentiate between issue priorities, which are a source of emotional activation and then act as a proxy for arousal. The best performance is obtained by combining SEA (428 words) with a previously created general purpose lexicon by Warriner et al. (13,915 words) and it achieves Cohen's d effect sizes up to 0.5.