 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Voice and Biofeedback to Predict User Engagement during Requirements Interviews
Apr 06, 2021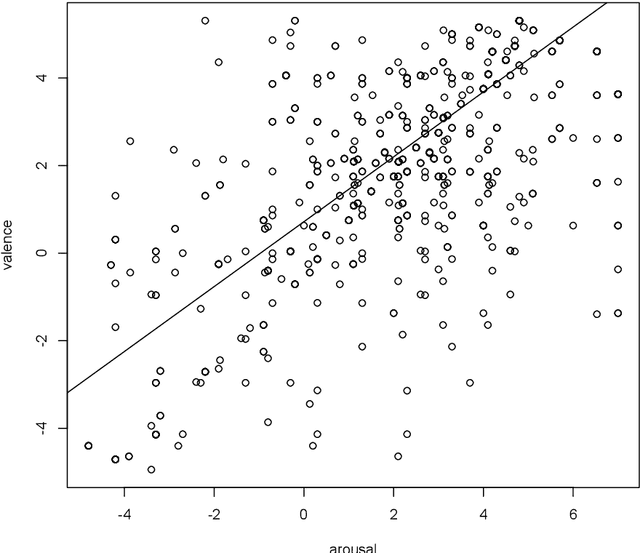

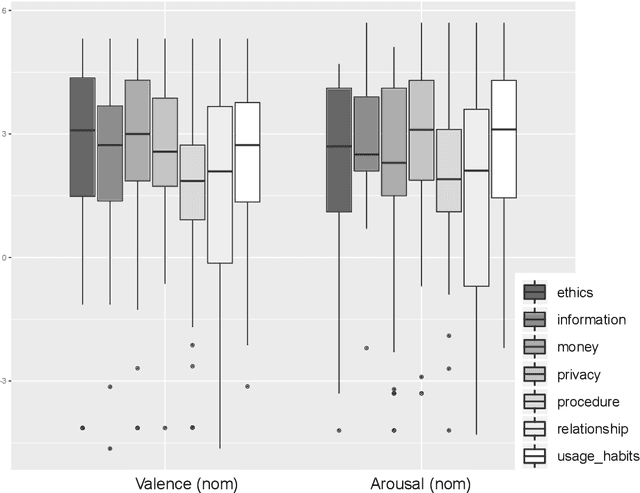

Capturing users engagement is crucial for gathering feedback about the features of a software product. In a market-driven context, current approaches to collect and analyze users feedback are based on techniques leveraging information extracted from product reviews and social media. These approaches are hardly applicable in bespoke software development, or in contexts in which one needs to gather information from specific users. In such cases, companies need to resort to face-to-face interviews to get feedback on their products. In this paper, we propose to utilize biometric data, in terms of physiological and voice features, to complement interviews with information about the engagement of the user on the discussed product-relevant topics. We evaluate our approach by interviewing users while gathering their physiological data (i.e., biofeedback) using an Empatica E4 wristband, and capturing their voice through the default audio-recorder of a common laptop. Our results show that we can predict users' engagement by training supervised machine learning algorithms on biometric data, and that voice features alone can be sufficiently effective. The performance of the prediction algorithms is maximised when pre-processing the training data with the synthetic minority oversampling technique (SMOTE). The results of our work suggest that biofeedback and voice analysis can be used to facilitate prioritization of requirements oriented to product improvement, and to steer the interview based on users' engagement. Furthermore, the usage of voice features can be particularly helpful for emotion-aware requirements elicitation in remote communication, either performed by human analysts or voice-based chatbots.
Love, Joy, Anger, Sadness, Fear, and Surprise: SE Needs Special Kinds of AI: A Case Study on Text Mining and SE
Apr 23, 2020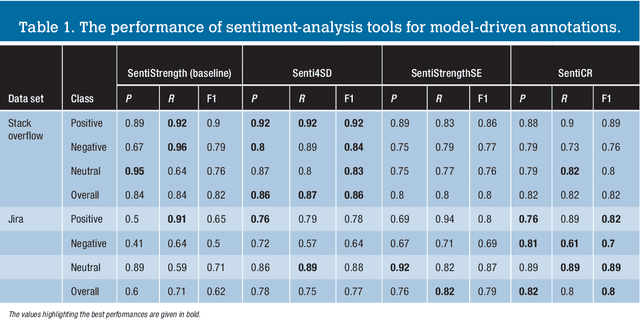
Do you like your code? What kind of code makes developers happiest? What makes them angriest? Is it possible to monitor the mood of a large team of coders to determine when and where a codebase needs additional help?
EmoTxt: A Toolkit for Emotion Recognition from Text
Jan 19, 2018
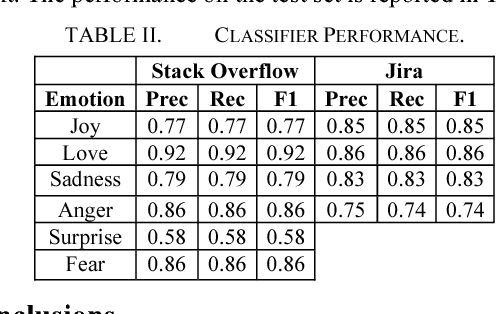
We present EmoTxt, a toolkit for emotion recognition from text, trained and tested on a gold standard of about 9K question, answers, and comments from online interactions. We provide empirical evidence of the performance of EmoTxt. To the best of our knowledge, EmoTxt is the first open-source toolkit supporting both emotion recognition from text and training of custom emotion classification models.
Sentiment Polarity Detection for Software Development
Sep 25, 2017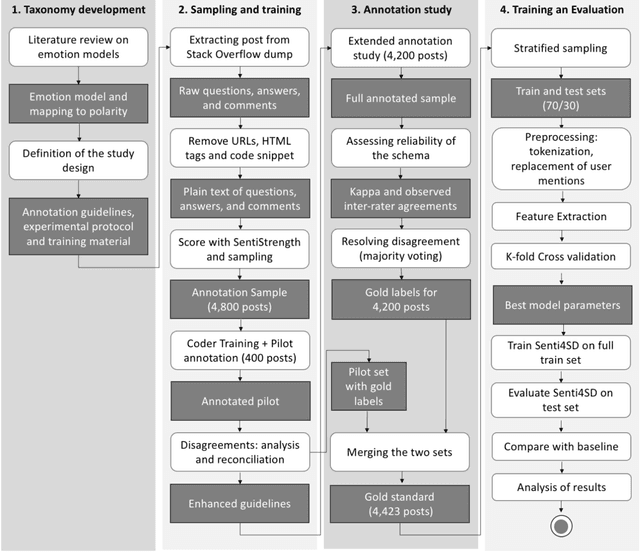
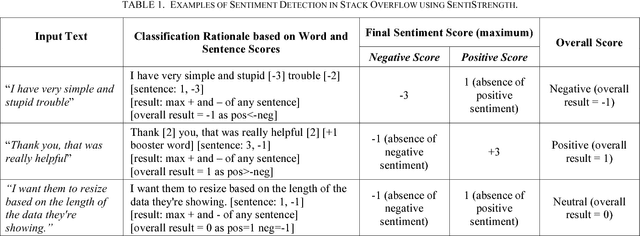

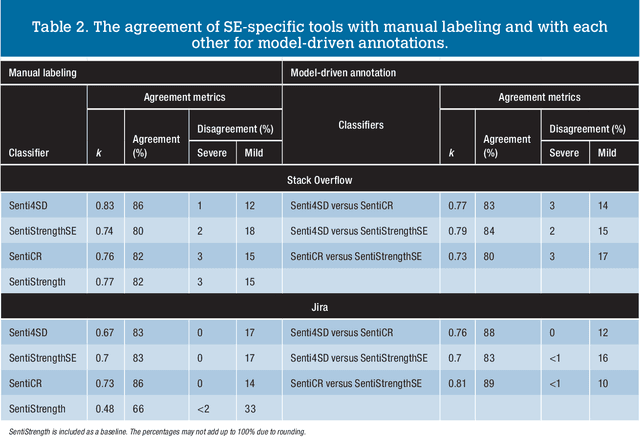
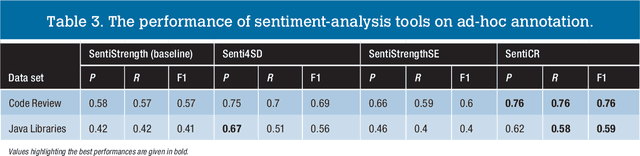
The role of sentiment analysis is increasingly emerging to study software developers' emotions by mining crowd-generated content within social software engineering tools. However, off-the-shelf sentiment analysis tools have been trained on non-technical domains and general-purpose social media, thus resulting in misclassifications of technical jargon and problem reports. Here, we present Senti4SD, a classifier specifically trained to support sentiment analysis in developers' communication channels. Senti4SD is trained and validated using a gold standard of Stack Overflow questions, answers, and comments manually annotated for sentiment polarity. It exploits a suite of both lexicon- and keyword-based features, as well as semantic features based on word embedding. With respect to a mainstream off-the-shelf tool, which we use as a baseline, Senti4SD reduces the misclassifications of neutral and positive posts as emotionally negative. To encourage replications, we release a lab package including the classifier, the word embedding space, and the gold standard with annotation guidelines.
* Cite as: Calefato, F., Lanubile, F., Maiorano, F., Novielli N. Empir Software Eng (2017). https://doi.org/10.1007/s10664-017-9546-9 Full-text view-only version here: http://rdcu.be/vZrG, Empir Software Eng (2017)
Bootstrapping a Lexicon for Emotional Arousal in Software Engineering
Mar 27, 2017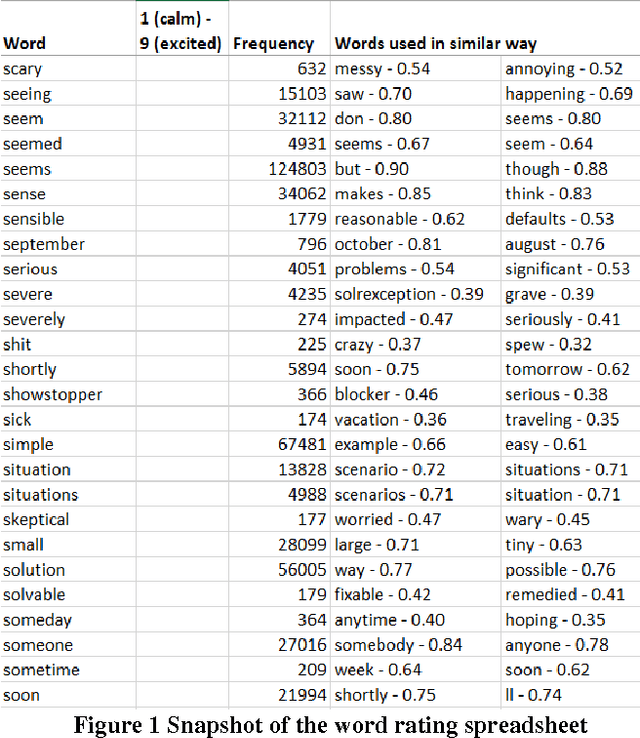
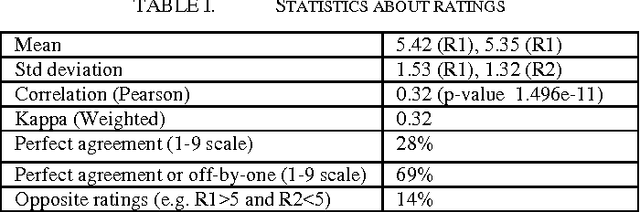
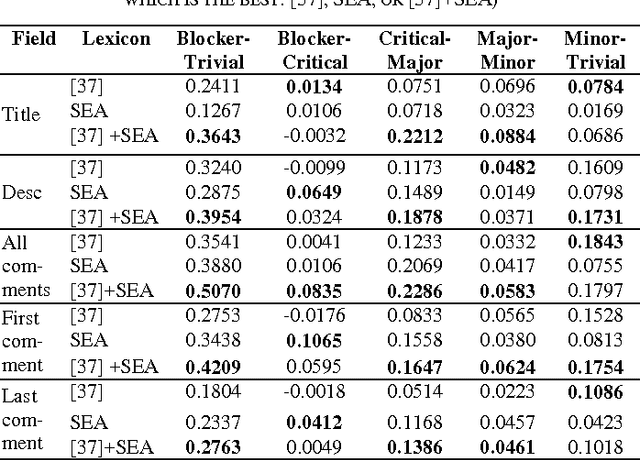
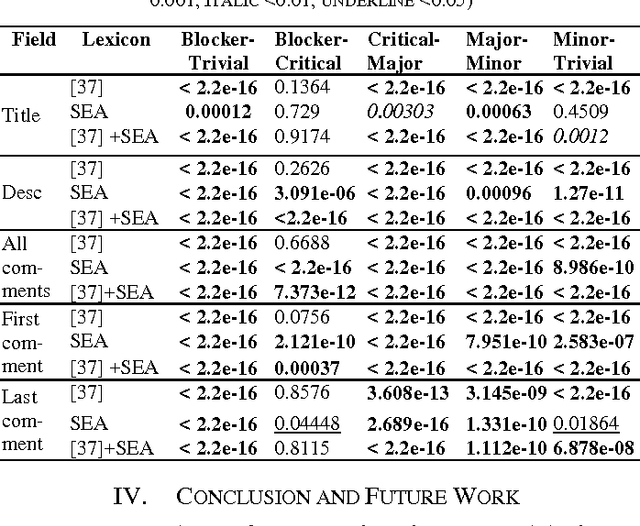
Emotional arousal increases activation and performance but may also lead to burnout in software development. We present the first version of a Software Engineering Arousal lexicon (SEA) that is specifically designed to address the problem of emotional arousal in the software developer ecosystem. SEA is built using a bootstrapping approach that combines word embedding model trained on issue-tracking data and manual scoring of items in the lexicon. We show that our lexicon is able to differentiate between issue priorities, which are a source of emotional activation and then act as a proxy for arousal. The best performance is obtained by combining SEA (428 words) with a previously created general purpose lexicon by Warriner et al. (13,915 words) and it achieves Cohen's d effect sizes up to 0.5.