 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGet on the Train or be Left on the Station: Using LLMs for Software Engineering Research
Jun 15, 2025The adoption of Large Language Models (LLMs) is not only transforming software engineering (SE) practice but is also poised to fundamentally disrupt how research is conducted in the field. While perspectives on this transformation range from viewing LLMs as mere productivity tools to considering them revolutionary forces, we argue that the SE research community must proactively engage with and shape the integration of LLMs into research practices, emphasizing human agency in this transformation. As LLMs rapidly become integral to SE research - both as tools that support investigations and as subjects of study - a human-centric perspective is essential. Ensuring human oversight and interpretability is necessary for upholding scientific rigor, fostering ethical responsibility, and driving advancements in the field. Drawing from discussions at the 2nd Copenhagen Symposium on Human-Centered AI in SE, this position paper employs McLuhan's Tetrad of Media Laws to analyze the impact of LLMs on SE research. Through this theoretical lens, we examine how LLMs enhance research capabilities through accelerated ideation and automated processes, make some traditional research practices obsolete, retrieve valuable aspects of historical research approaches, and risk reversal effects when taken to extremes. Our analysis reveals opportunities for innovation and potential pitfalls that require careful consideration. We conclude with a call to action for the SE research community to proactively harness the benefits of LLMs while developing frameworks and guidelines to mitigate their risks, to ensure continued rigor and impact of research in an AI-augmented future.
Assessing the Use of AutoML for Data-Driven Software Engineering
Jul 20, 2023

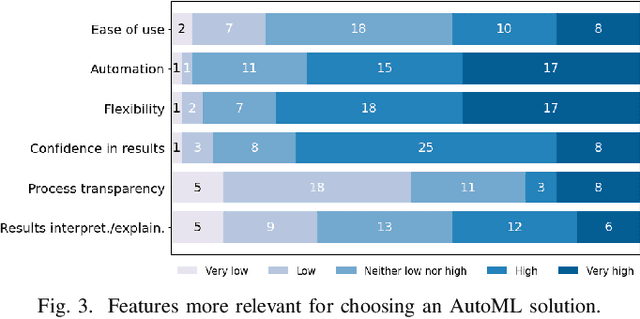

Background. Due to the widespread adoption of Artificial Intelligence (AI) and Machine Learning (ML) for building software applications, companies are struggling to recruit employees with a deep understanding of such technologies. In this scenario, AutoML is soaring as a promising solution to fill the AI/ML skills gap since it promises to automate the building of end-to-end AI/ML pipelines that would normally be engineered by specialized team members. Aims. Despite the growing interest and high expectations, there is a dearth of information about the extent to which AutoML is currently adopted by teams developing AI/ML-enabled systems and how it is perceived by practitioners and researchers. Method. To fill these gaps, in this paper, we present a mixed-method study comprising a benchmark of 12 end-to-end AutoML tools on two SE datasets and a user survey with follow-up interviews to further our understanding of AutoML adoption and perception. Results. We found that AutoML solutions can generate models that outperform those trained and optimized by researchers to perform classification tasks in the SE domain. Also, our findings show that the currently available AutoML solutions do not live up to their names as they do not equally support automation across the stages of the ML development workflow and for all the team members. Conclusions. We derive insights to inform the SE research community on how AutoML can facilitate their activities and tool builders on how to design the next generation of AutoML technologies.
A Preliminary Investigation of MLOps Practices in GitHub
Sep 23, 2022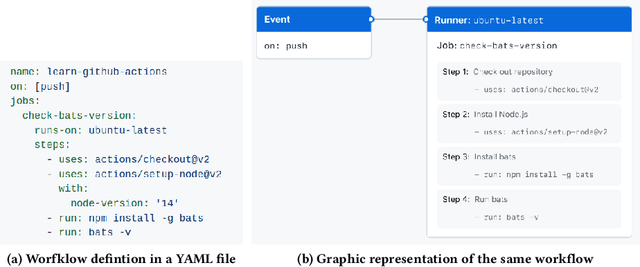

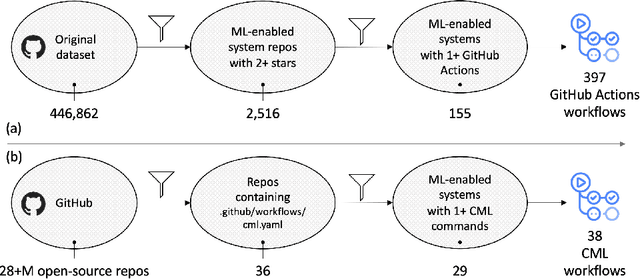

Background. The rapid and growing popularity of machine learning (ML) applications has led to an increasing interest in MLOps, that is, the practice of continuous integration and deployment (CI/CD) of ML-enabled systems. Aims. Since changes may affect not only the code but also the ML model parameters and the data themselves, the automation of traditional CI/CD needs to be extended to manage model retraining in production. Method. In this paper, we present an initial investigation of the MLOps practices implemented in a set of ML-enabled systems retrieved from GitHub, focusing on GitHub Actions and CML, two solutions to automate the development workflow. Results. Our preliminary results suggest that the adoption of MLOps workflows in open-source GitHub projects is currently rather limited. Conclusions. Issues are also identified, which can guide future research work.
* Presented at ESEM '22, the 16th ACM / IEEE International Symposium on Empirical Software Engineering and Measurement
Pynblint: a Static Analyzer for Python Jupyter Notebooks
May 24, 2022Jupyter Notebook is the tool of choice of many data scientists in the early stages of ML workflows. The notebook format, however, has been criticized for inducing bad programming practices; indeed, researchers have already shown that open-source repositories are inundated by poor-quality notebooks. Low-quality output from the prototypical stages of ML workflows constitutes a clear bottleneck towards the productization of ML models. To foster the creation of better notebooks, we developed Pynblint, a static analyzer for Jupyter notebooks written in Python. The tool checks the compliance of notebooks (and surrounding repositories) with a set of empirically validated best practices and provides targeted recommendations when violations are detected.
* 2 pages
Eliciting Best Practices for Collaboration with Computational Notebooks
Feb 15, 2022
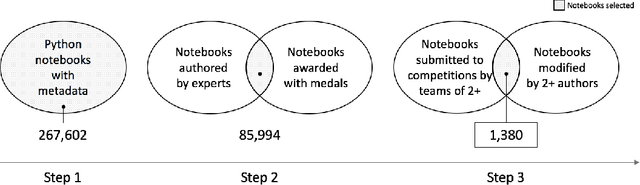
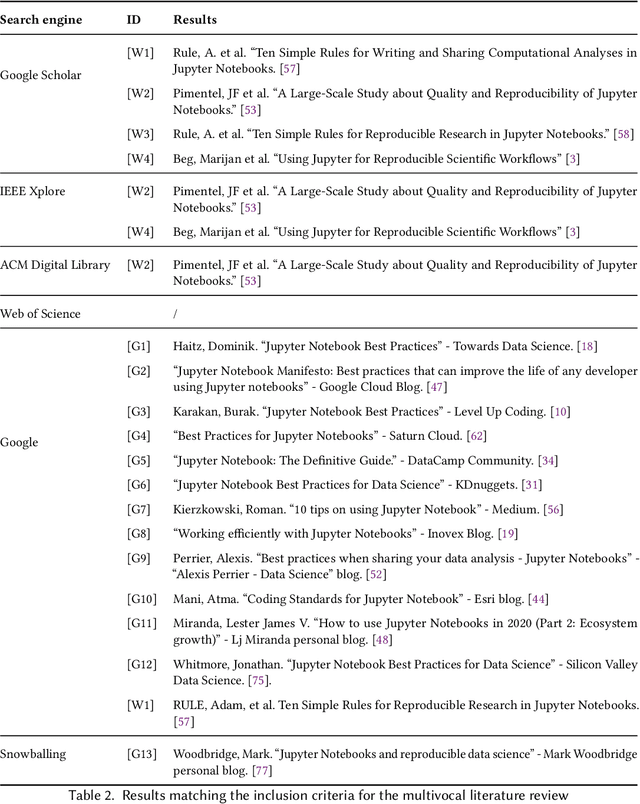
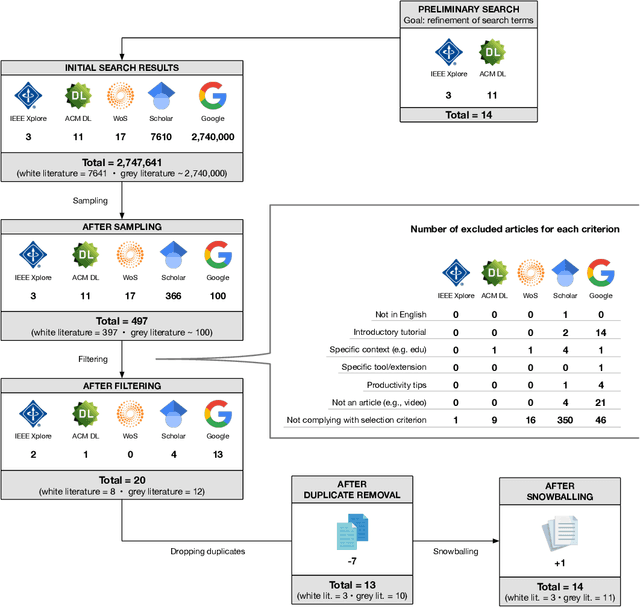
Despite the widespread adoption of computational notebooks, little is known about best practices for their usage in collaborative contexts. In this paper, we fill this gap by eliciting a catalog of best practices for collaborative data science with computational notebooks. With this aim, we first look for best practices through a multivocal literature review. Then, we conduct interviews with professional data scientists to assess their awareness of these best practices. Finally, we assess the adoption of best practices through the analysis of 1,380 Jupyter notebooks retrieved from the Kaggle platform. Findings reveal that experts are mostly aware of the best practices and tend to adopt them in their daily work. Nonetheless, they do not consistently follow all the recommendations as, depending on specific contexts, some are deemed unfeasible or counterproductive due to the lack of proper tool support. As such, we envision the design of notebook solutions that allow data scientists not to have to prioritize exploration and rapid prototyping over writing code of quality.
Using Personality Detection Tools for Software Engineering Research: How Far Can We Go?
Oct 22, 2021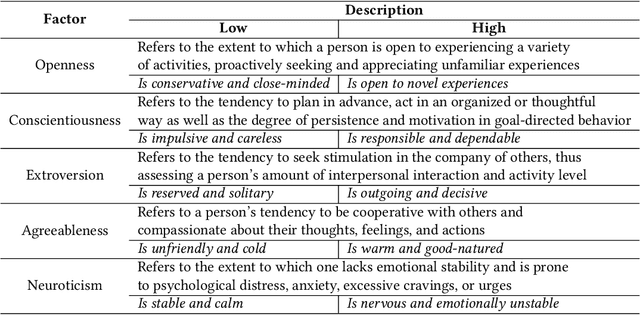
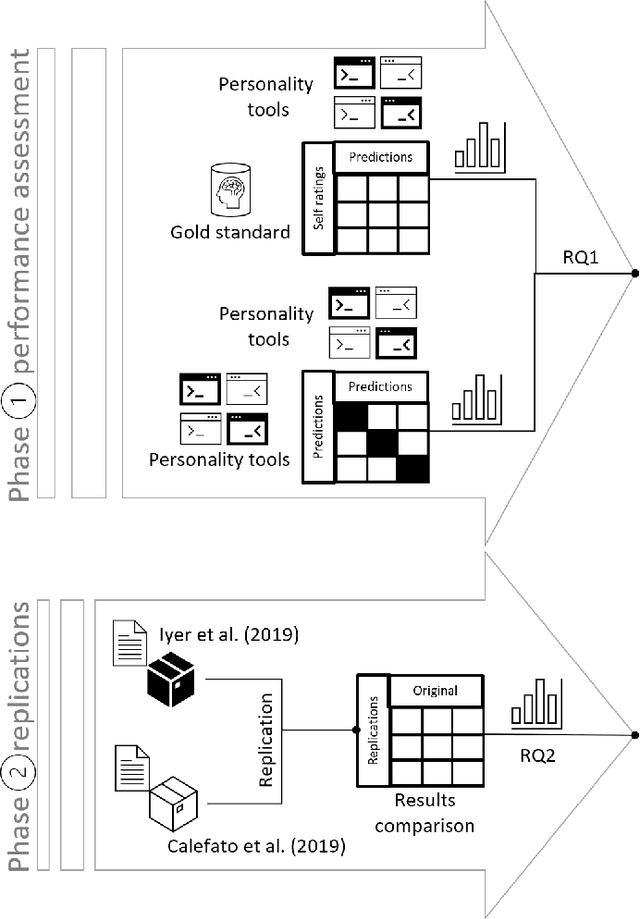
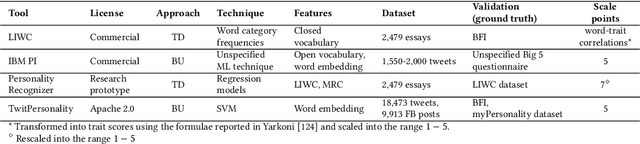
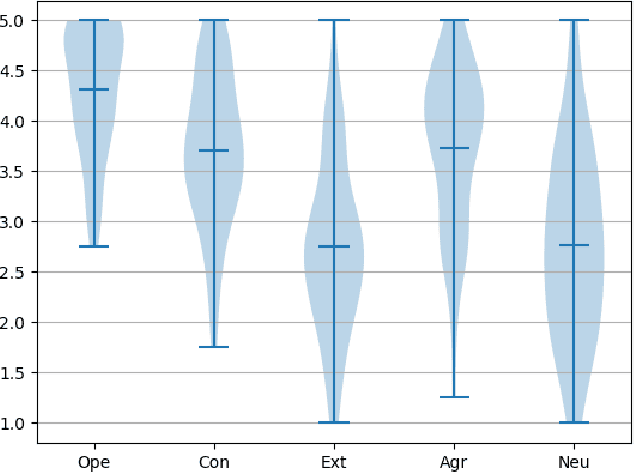
Assessing the personality of software engineers may help to match individual traits with the characteristics of development activities such as code review and testing, as well as support managers in team composition. However, self-assessment questionnaires are not a practical solution for collecting multiple observations on a large scale. Instead, automatic personality detection, while overcoming these limitations, is based on off-the-shelf solutions trained on non-technical corpora, which might not be readily applicable to technical domains like Software Engineering (SE). In this paper, we first assess the performance of general-purpose personality detection tools when applied to a technical corpus of developers' emails retrieved from the public archives of the Apache Software Foundation. We observe a general low accuracy of predictions and an overall disagreement among the tools. Second, we replicate two previous research studies in SE by replacing the personality detection tool used to infer developers' personalities from pull-request discussions and emails. We observe that the original results are not confirmed, i.e., changing the tool used in the original study leads to diverging conclusions. Our results suggest a need for personality detection tools specially targeted for the software engineering domain.
Towards Productizing AI/ML Models: An Industry Perspective from Data Scientists
Mar 18, 2021The transition from AI/ML models to production-ready AI-based systems is a challenge for both data scientists and software engineers. In this paper, we report the results of a workshop conducted in a consulting company to understand how this transition is perceived by practitioners. Starting from the need for making AI experiments reproducible, the main themes that emerged are related to the use of the Jupyter Notebook as the primary prototyping tool, and the lack of support for software engineering best practices as well as data science specific functionalities.
Love, Joy, Anger, Sadness, Fear, and Surprise: SE Needs Special Kinds of AI: A Case Study on Text Mining and SE
Apr 23, 2020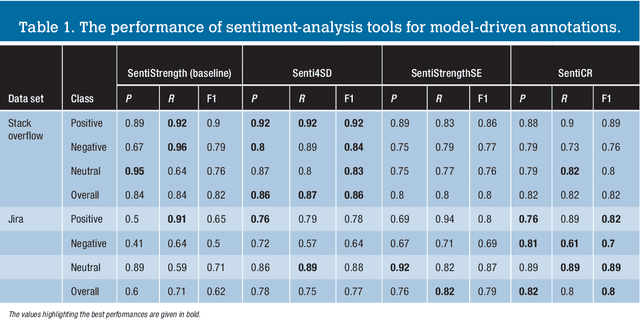
Do you like your code? What kind of code makes developers happiest? What makes them angriest? Is it possible to monitor the mood of a large team of coders to determine when and where a codebase needs additional help?
EmoTxt: A Toolkit for Emotion Recognition from Text
Jan 19, 2018
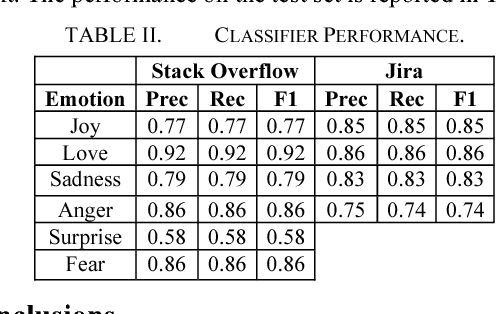
We present EmoTxt, a toolkit for emotion recognition from text, trained and tested on a gold standard of about 9K question, answers, and comments from online interactions. We provide empirical evidence of the performance of EmoTxt. To the best of our knowledge, EmoTxt is the first open-source toolkit supporting both emotion recognition from text and training of custom emotion classification models.
Sentiment Polarity Detection for Software Development
Sep 25, 2017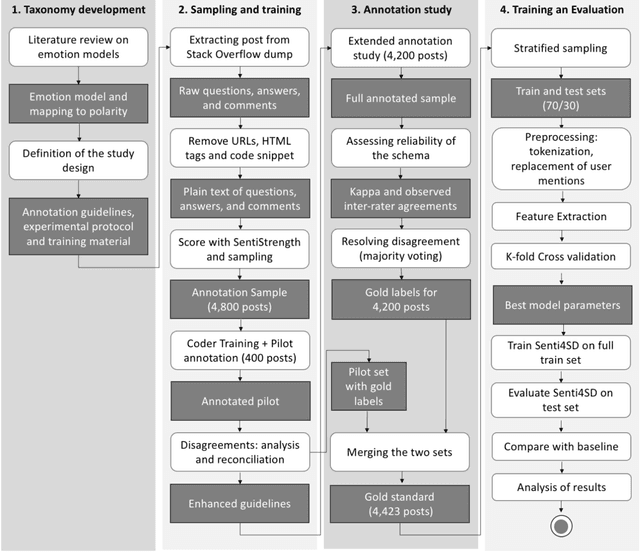
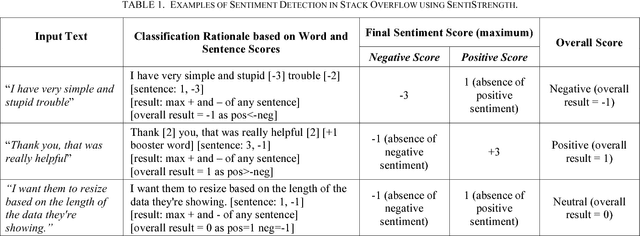
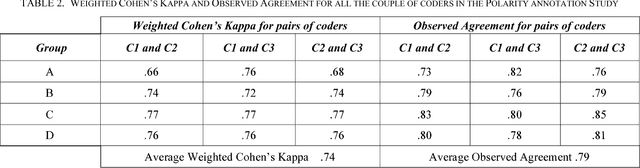

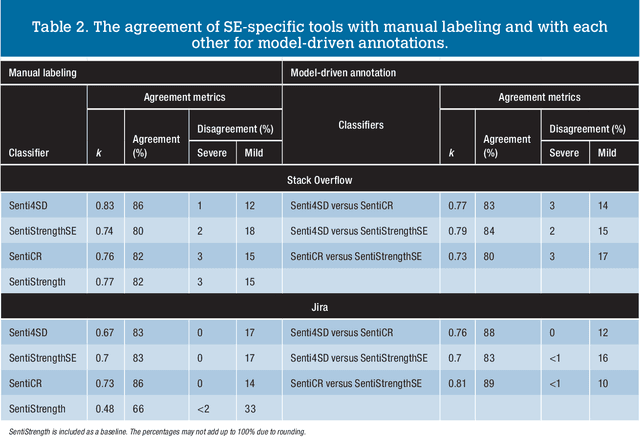
The role of sentiment analysis is increasingly emerging to study software developers' emotions by mining crowd-generated content within social software engineering tools. However, off-the-shelf sentiment analysis tools have been trained on non-technical domains and general-purpose social media, thus resulting in misclassifications of technical jargon and problem reports. Here, we present Senti4SD, a classifier specifically trained to support sentiment analysis in developers' communication channels. Senti4SD is trained and validated using a gold standard of Stack Overflow questions, answers, and comments manually annotated for sentiment polarity. It exploits a suite of both lexicon- and keyword-based features, as well as semantic features based on word embedding. With respect to a mainstream off-the-shelf tool, which we use as a baseline, Senti4SD reduces the misclassifications of neutral and positive posts as emotionally negative. To encourage replications, we release a lab package including the classifier, the word embedding space, and the gold standard with annotation guidelines.
* Cite as: Calefato, F., Lanubile, F., Maiorano, F., Novielli N. Empir Software Eng (2017). https://doi.org/10.1007/s10664-017-9546-9 Full-text view-only version here: http://rdcu.be/vZrG, Empir Software Eng (2017)