 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Productizing AI/ML Models: An Industry Perspective from Data Scientists
Mar 18, 2021The transition from AI/ML models to production-ready AI-based systems is a challenge for both data scientists and software engineers. In this paper, we report the results of a workshop conducted in a consulting company to understand how this transition is perceived by practitioners. Starting from the need for making AI experiments reproducible, the main themes that emerged are related to the use of the Jupyter Notebook as the primary prototyping tool, and the lack of support for software engineering best practices as well as data science specific functionalities.
ManTIME: Temporal expression identification and normalization in the TempEval-3 challenge
Apr 30, 2013
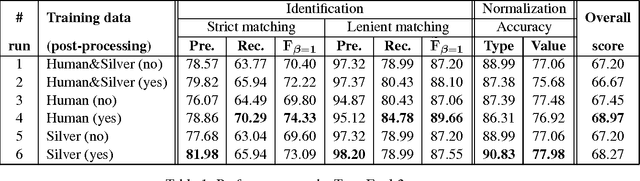
This paper describes a temporal expression identification and normalization system, ManTIME, developed for the TempEval-3 challenge. The identification phase combines the use of conditional random fields along with a post-processing identification pipeline, whereas the normalization phase is carried out using NorMA, an open-source rule-based temporal normalizer. We investigate the performance variation with respect to different feature types. Specifically, we show that the use of WordNet-based features in the identification task negatively affects the overall performance, and that there is no statistically significant difference in using gazetteers, shallow parsing and propositional noun phrases labels on top of the morphological features. On the test data, the best run achieved 0.95 (P), 0.85 (R) and 0.90 (F1) in the identification phase. Normalization accuracies are 0.84 (type attribute) and 0.77 (value attribute). Surprisingly, the use of the silver data (alone or in addition to the gold annotated ones) does not improve the performance.
Temporal expression normalisation in natural language texts
Jun 10, 2012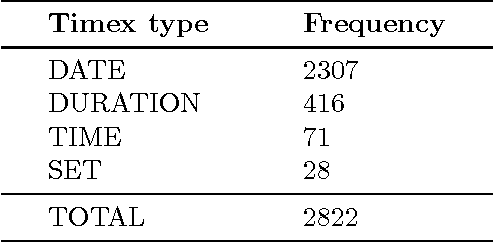
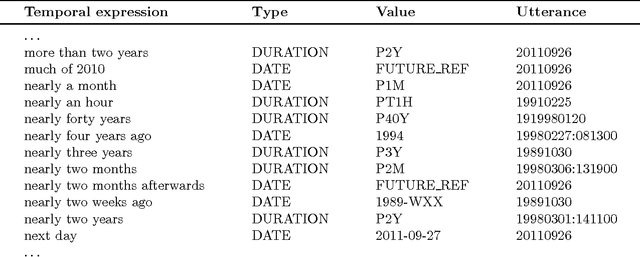


Automatic annotation of temporal expressions is a research challenge of great interest in the field of information extraction. In this report, I describe a novel rule-based architecture, built on top of a pre-existing system, which is able to normalise temporal expressions detected in English texts. Gold standard temporally-annotated resources are limited in size and this makes research difficult. The proposed system outperforms the state-of-the-art systems with respect to TempEval-2 Shared Task (value attribute) and achieves substantially better results with respect to the pre-existing system on top of which it has been developed. I will also introduce a new free corpus consisting of 2822 unique annotated temporal expressions. Both the corpus and the system are freely available on-line.