 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Use of AutoML for Data-Driven Software Engineering
Jul 20, 2023

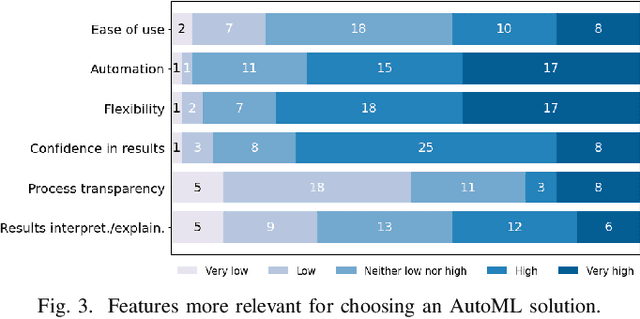

Background. Due to the widespread adoption of Artificial Intelligence (AI) and Machine Learning (ML) for building software applications, companies are struggling to recruit employees with a deep understanding of such technologies. In this scenario, AutoML is soaring as a promising solution to fill the AI/ML skills gap since it promises to automate the building of end-to-end AI/ML pipelines that would normally be engineered by specialized team members. Aims. Despite the growing interest and high expectations, there is a dearth of information about the extent to which AutoML is currently adopted by teams developing AI/ML-enabled systems and how it is perceived by practitioners and researchers. Method. To fill these gaps, in this paper, we present a mixed-method study comprising a benchmark of 12 end-to-end AutoML tools on two SE datasets and a user survey with follow-up interviews to further our understanding of AutoML adoption and perception. Results. We found that AutoML solutions can generate models that outperform those trained and optimized by researchers to perform classification tasks in the SE domain. Also, our findings show that the currently available AutoML solutions do not live up to their names as they do not equally support automation across the stages of the ML development workflow and for all the team members. Conclusions. We derive insights to inform the SE research community on how AutoML can facilitate their activities and tool builders on how to design the next generation of AutoML technologies.
Teaching MLOps in Higher Education through Project-Based Learning
Feb 02, 2023Building and maintaining production-grade ML-enabled components is a complex endeavor that goes beyond the current approach of academic education, focused on the optimization of ML model performance in the lab. In this paper, we present a project-based learning approach to teaching MLOps, focused on the demonstration and experience with emerging practices and tools to automatize the construction of ML-enabled components. We examine the design of a course based on this approach, including laboratory sessions that cover the end-to-end ML component life cycle, from model building to production deployment. Moreover, we report on preliminary results from the first edition of the course. During the present year, an updated version of the same course is being delivered in two independent universities; the related learning outcomes will be evaluated to analyze the effectiveness of project-based learning for this specific subject.
A Preliminary Investigation of MLOps Practices in GitHub
Sep 23, 2022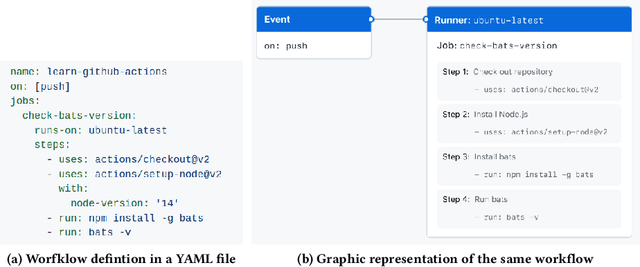

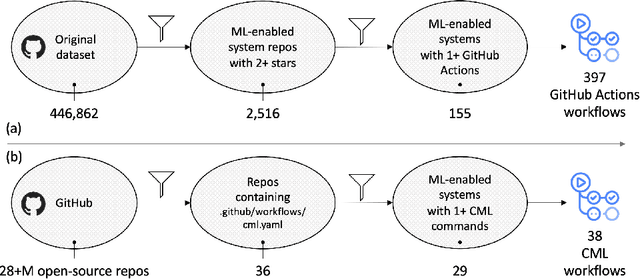

Background. The rapid and growing popularity of machine learning (ML) applications has led to an increasing interest in MLOps, that is, the practice of continuous integration and deployment (CI/CD) of ML-enabled systems. Aims. Since changes may affect not only the code but also the ML model parameters and the data themselves, the automation of traditional CI/CD needs to be extended to manage model retraining in production. Method. In this paper, we present an initial investigation of the MLOps practices implemented in a set of ML-enabled systems retrieved from GitHub, focusing on GitHub Actions and CML, two solutions to automate the development workflow. Results. Our preliminary results suggest that the adoption of MLOps workflows in open-source GitHub projects is currently rather limited. Conclusions. Issues are also identified, which can guide future research work.
* Presented at ESEM '22, the 16th ACM / IEEE International Symposium on Empirical Software Engineering and Measurement
Assessing the Quality of Computational Notebooks for a Frictionless Transition from Exploration to Production
May 24, 2022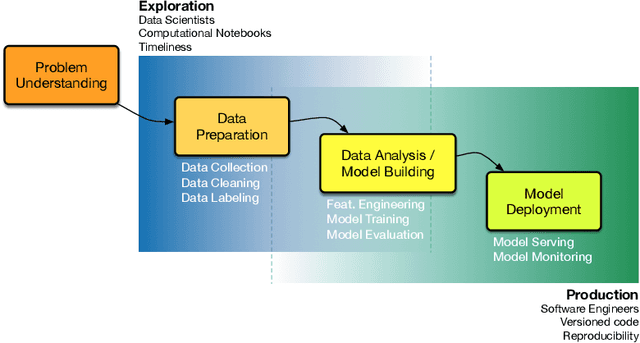
The massive trend of integrating data-driven AI capabilities into traditional software systems is rising new intriguing challenges. One of such challenges is achieving a smooth transition from the explorative phase of Machine Learning projects - in which data scientists build prototypical models in the lab - to their production phase - in which software engineers translate prototypes into production-ready AI components. To narrow down the gap between these two phases, tools and practices adopted by data scientists might be improved by incorporating consolidated software engineering solutions. In particular, computational notebooks have a prominent role in determining the quality of data science prototypes. In my research project, I address this challenge by studying the best practices for collaboration with computational notebooks and proposing proof-of-concept tools to foster guidelines compliance.
* 5 pages
Pynblint: a Static Analyzer for Python Jupyter Notebooks
May 24, 2022Jupyter Notebook is the tool of choice of many data scientists in the early stages of ML workflows. The notebook format, however, has been criticized for inducing bad programming practices; indeed, researchers have already shown that open-source repositories are inundated by poor-quality notebooks. Low-quality output from the prototypical stages of ML workflows constitutes a clear bottleneck towards the productization of ML models. To foster the creation of better notebooks, we developed Pynblint, a static analyzer for Jupyter notebooks written in Python. The tool checks the compliance of notebooks (and surrounding repositories) with a set of empirically validated best practices and provides targeted recommendations when violations are detected.
* 2 pages
Eliciting Best Practices for Collaboration with Computational Notebooks
Feb 15, 2022
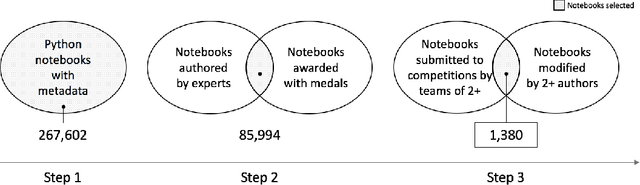
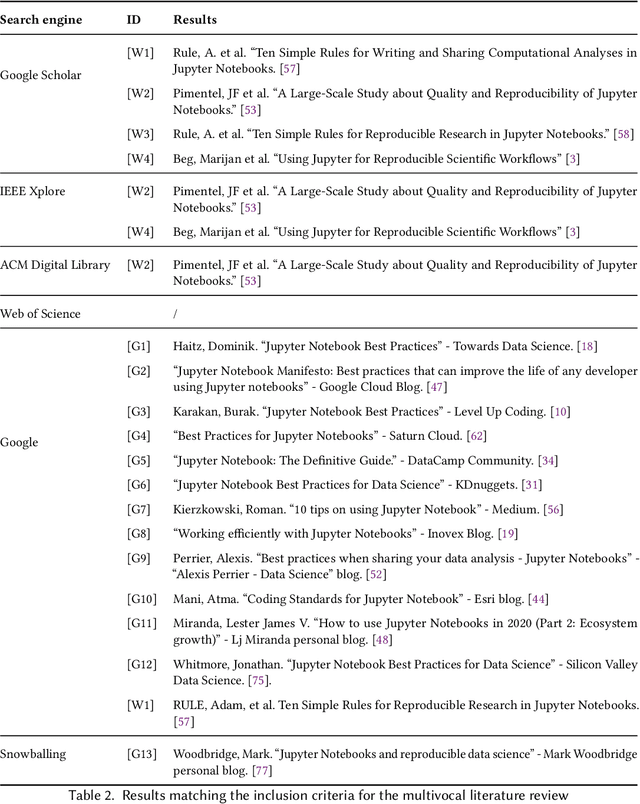
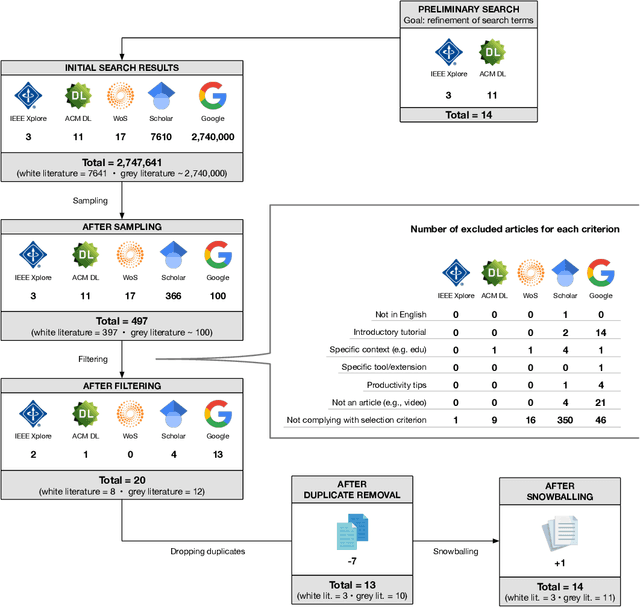
Despite the widespread adoption of computational notebooks, little is known about best practices for their usage in collaborative contexts. In this paper, we fill this gap by eliciting a catalog of best practices for collaborative data science with computational notebooks. With this aim, we first look for best practices through a multivocal literature review. Then, we conduct interviews with professional data scientists to assess their awareness of these best practices. Finally, we assess the adoption of best practices through the analysis of 1,380 Jupyter notebooks retrieved from the Kaggle platform. Findings reveal that experts are mostly aware of the best practices and tend to adopt them in their daily work. Nonetheless, they do not consistently follow all the recommendations as, depending on specific contexts, some are deemed unfeasible or counterproductive due to the lack of proper tool support. As such, we envision the design of notebook solutions that allow data scientists not to have to prioritize exploration and rapid prototyping over writing code of quality.
Towards Productizing AI/ML Models: An Industry Perspective from Data Scientists
Mar 18, 2021The transition from AI/ML models to production-ready AI-based systems is a challenge for both data scientists and software engineers. In this paper, we report the results of a workshop conducted in a consulting company to understand how this transition is perceived by practitioners. Starting from the need for making AI experiments reproducible, the main themes that emerged are related to the use of the Jupyter Notebook as the primary prototyping tool, and the lack of support for software engineering best practices as well as data science specific functionalities.