 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Research Agenda on Agents and Software Engineering: Outcomes from the Rio A2SE Seminar
May 12, 2026The rise of agentic AI is reshaping software engineering in two intertwined directions: agents are increasingly applied to support software engineering tasks, and Agentic AI systems themselves are complex systems that require re-thinking currently established software engineering practices. To chart a coherent research agenda covering the two directions, we organized the A2SE seminar in Rio de Janeiro, bringing together 18 experts from academia and industry. Through structured presentations, collaborative topic clustering, and focused group discussions, participants identified six thematic areas: Governance, Software Engineering for Agents, Agents for Software Architecture, Quality and Evaluation, Sustainability, and Code, and they prioritized short-term and long-term research directions for each. This paper presents the resulting community-driven, opinionated research agenda, offering the SE community a structured foundation for coordinating efforts at this critical juncture.
Taking a Pulse on How Generative AI is Reshaping the Software Engineering Research Landscape
Apr 13, 2026Context: Software engineering (SE) researchers increasingly study Generative AI (GenAI) while also incorporating it into their own research practices. Despite rapid adoption, there is limited empirical evidence on how GenAI is used in SE research and its implications for research practices and governance. Aims: We conduct a large-scale survey of 457 SE researchers publishing in top venues between 2023 and 2025. Method: Using quantitative and qualitative analyses, we examine who uses GenAI and why, where it is used across research activities, and how researchers perceive its benefits, opportunities, challenges, risks, and governance. Results: GenAI use is widespread, with many researchers reporting pressure to adopt and align their work with it. Usage is concentrated in writing and early-stage activities, while methodological and analytical tasks remain largely human-driven. Although productivity gains are widely perceived, concerns about trust, correctness, and regulatory uncertainty persist. Researchers highlight risks such as inaccuracies and bias, emphasize mitigation through human oversight and verification, and call for clearer governance, including guidance on responsible use and peer review. Conclusion: We provide a fine-grained, SE-specific characterization of GenAI use across research activities, along with taxonomies of GenAI use cases for research and peer review, opportunities, risks, mitigation strategies, and governance needs. These findings establish an empirical baseline for the responsible integration of GenAI into academic practice.
On the Use of a Large Language Model to Support the Conduction of a Systematic Mapping Study: A Brief Report from a Practitioner's View
Feb 09, 2026The use of Large Language Models (LLMs) has drawn growing interest within the scientific community. LLMs can handle large volumes of textual data and support methods for evidence synthesis. Although recent studies highlight the potential of LLMs to accelerate screening and data extraction steps in systematic reviews, detailed reports of their practical application throughout the entire process remain scarce. This paper presents an experience report on the conduction of a systematic mapping study with the support of LLMs, describing the steps followed, the necessary adjustments, and the main challenges faced. Positive aspects are discussed, such as (i) the significant reduction of time in repetitive tasks and (ii) greater standardization in data extraction, as well as negative aspects, including (i) considerable effort to build reliable well-structured prompts, especially for less experienced users, since achieving effective prompts may require several iterations and testing, which can partially offset the expected time savings, (ii) the occurrence of hallucinations, and (iii) the need for constant manual verification. As a contribution, this work offers lessons learned and practical recommendations for researchers interested in adopting LLMs in systematic mappings and reviews, highlighting both efficiency gains and methodological risks and limitations to be considered.
Define-ML: An Approach to Ideate Machine Learning-Enabled Systems
Jun 25, 2025[Context] The increasing adoption of machine learning (ML) in software systems demands specialized ideation approaches that address ML-specific challenges, including data dependencies, technical feasibility, and alignment between business objectives and probabilistic system behavior. Traditional ideation methods like Lean Inception lack structured support for these ML considerations, which can result in misaligned product visions and unrealistic expectations. [Goal] This paper presents Define-ML, a framework that extends Lean Inception with tailored activities - Data Source Mapping, Feature-to-Data Source Mapping, and ML Mapping - to systematically integrate data and technical constraints into early-stage ML product ideation. [Method] We developed and validated Define-ML following the Technology Transfer Model, conducting both static validation (with a toy problem) and dynamic validation (in a real-world industrial case study). The analysis combined quantitative surveys with qualitative feedback, assessing utility, ease of use, and intent of adoption. [Results] Participants found Define-ML effective for clarifying data concerns, aligning ML capabilities with business goals, and fostering cross-functional collaboration. The approach's structured activities reduced ideation ambiguity, though some noted a learning curve for ML-specific components, which can be mitigated by expert facilitation. All participants expressed the intention to adopt Define-ML. [Conclusion] Define-ML provides an openly available, validated approach for ML product ideation, building on Lean Inception's agility while aligning features with available data and increasing awareness of technical feasibility.
Agile Management for Machine Learning: A Systematic Mapping Study
Jun 25, 2025[Context] Machine learning (ML)-enabled systems are present in our society, driving significant digital transformations. The dynamic nature of ML development, characterized by experimental cycles and rapid changes in data, poses challenges to traditional project management. Agile methods, with their flexibility and incremental delivery, seem well-suited to address this dynamism. However, it is unclear how to effectively apply these methods in the context of ML-enabled systems, where challenges require tailored approaches. [Goal] Our goal is to outline the state of the art in agile management for ML-enabled systems. [Method] We conducted a systematic mapping study using a hybrid search strategy that combines database searches with backward and forward snowballing iterations. [Results] Our study identified 27 papers published between 2008 and 2024. From these, we identified eight frameworks and categorized recommendations and practices into eight key themes, such as Iteration Flexibility, Innovative ML-specific Artifacts, and the Minimal Viable Model. The main challenge identified across studies was accurate effort estimation for ML-related tasks. [Conclusion] This study contributes by mapping the state of the art and identifying open gaps in the field. While relevant work exists, more robust empirical evaluation is still needed to validate these contributions.
Get on the Train or be Left on the Station: Using LLMs for Software Engineering Research
Jun 15, 2025The adoption of Large Language Models (LLMs) is not only transforming software engineering (SE) practice but is also poised to fundamentally disrupt how research is conducted in the field. While perspectives on this transformation range from viewing LLMs as mere productivity tools to considering them revolutionary forces, we argue that the SE research community must proactively engage with and shape the integration of LLMs into research practices, emphasizing human agency in this transformation. As LLMs rapidly become integral to SE research - both as tools that support investigations and as subjects of study - a human-centric perspective is essential. Ensuring human oversight and interpretability is necessary for upholding scientific rigor, fostering ethical responsibility, and driving advancements in the field. Drawing from discussions at the 2nd Copenhagen Symposium on Human-Centered AI in SE, this position paper employs McLuhan's Tetrad of Media Laws to analyze the impact of LLMs on SE research. Through this theoretical lens, we examine how LLMs enhance research capabilities through accelerated ideation and automated processes, make some traditional research practices obsolete, retrieve valuable aspects of historical research approaches, and risk reversal effects when taken to extremes. Our analysis reveals opportunities for innovation and potential pitfalls that require careful consideration. We conclude with a call to action for the SE research community to proactively harness the benefits of LLMs while developing frameworks and guidelines to mitigate their risks, to ensure continued rigor and impact of research in an AI-augmented future.
Large Language Model for Qualitative Research -- A Systematic Mapping Study
Nov 18, 2024The exponential growth of text-based data in domains such as healthcare, education, and social sciences has outpaced the capacity of traditional qualitative analysis methods, which are time-intensive and prone to subjectivity. Large Language Models (LLMs), powered by advanced generative AI, have emerged as transformative tools capable of automating and enhancing qualitative analysis. This study systematically maps the literature on the use of LLMs for qualitative research, exploring their application contexts, configurations, methodologies, and evaluation metrics. Findings reveal that LLMs are utilized across diverse fields, demonstrating the potential to automate processes traditionally requiring extensive human input. However, challenges such as reliance on prompt engineering, occasional inaccuracies, and contextual limitations remain significant barriers. This research highlights opportunities for integrating LLMs with human expertise, improving model robustness, and refining evaluation methodologies. By synthesizing trends and identifying research gaps, this study aims to guide future innovations in the application of LLMs for qualitative analysis.
Assessing the Use of AutoML for Data-Driven Software Engineering
Jul 20, 2023

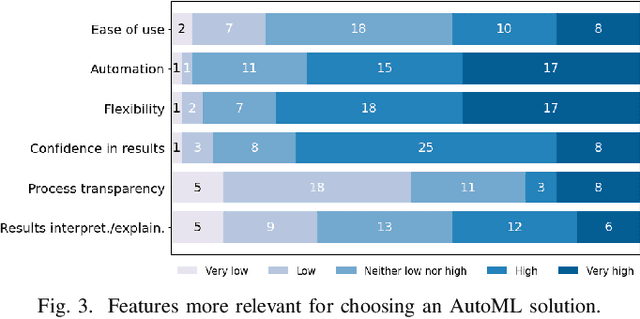

Background. Due to the widespread adoption of Artificial Intelligence (AI) and Machine Learning (ML) for building software applications, companies are struggling to recruit employees with a deep understanding of such technologies. In this scenario, AutoML is soaring as a promising solution to fill the AI/ML skills gap since it promises to automate the building of end-to-end AI/ML pipelines that would normally be engineered by specialized team members. Aims. Despite the growing interest and high expectations, there is a dearth of information about the extent to which AutoML is currently adopted by teams developing AI/ML-enabled systems and how it is perceived by practitioners and researchers. Method. To fill these gaps, in this paper, we present a mixed-method study comprising a benchmark of 12 end-to-end AutoML tools on two SE datasets and a user survey with follow-up interviews to further our understanding of AutoML adoption and perception. Results. We found that AutoML solutions can generate models that outperform those trained and optimized by researchers to perform classification tasks in the SE domain. Also, our findings show that the currently available AutoML solutions do not live up to their names as they do not equally support automation across the stages of the ML development workflow and for all the team members. Conclusions. We derive insights to inform the SE research community on how AutoML can facilitate their activities and tool builders on how to design the next generation of AutoML technologies.
Predicting IMDb Rating of TV Series with Deep Learning: The Case of Arrow
Aug 28, 2022

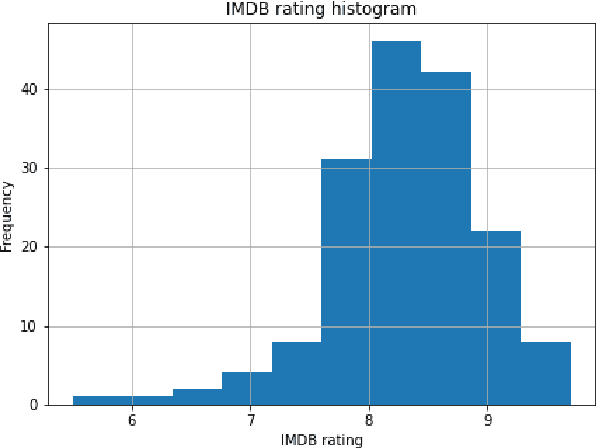

Context: The number of TV series offered nowadays is very high. Due to its large amount, many series are canceled due to a lack of originality that generates a low audience. Problem: Having a decision support system that can show why some shows are a huge success or not would facilitate the choices of renewing or starting a show. Solution: We studied the case of the series Arrow broadcasted by CW Network and used descriptive and predictive modeling techniques to predict the IMDb rating. We assumed that the theme of the episode would affect its evaluation by users, so the dataset is composed only by the director of the episode, the number of reviews that episode got, the percentual of each theme extracted by the Latent Dirichlet Allocation (LDA) model of an episode, the number of viewers from Wikipedia and the rating from IMDb. The LDA model is a generative probabilistic model of a collection of documents made up of words. Method: In this prescriptive research, the case study method was used, and its results were analyzed using a quantitative approach. Summary of Results: With the features of each episode, the model that performed the best to predict the rating was Catboost due to a similar mean squared error of the KNN model but a better standard deviation during the test phase. It was possible to predict IMDb ratings with an acceptable root mean squared error of 0.55.
Towards Perspective-Based Specification of Machine Learning-Enabled Systems
Jun 20, 2022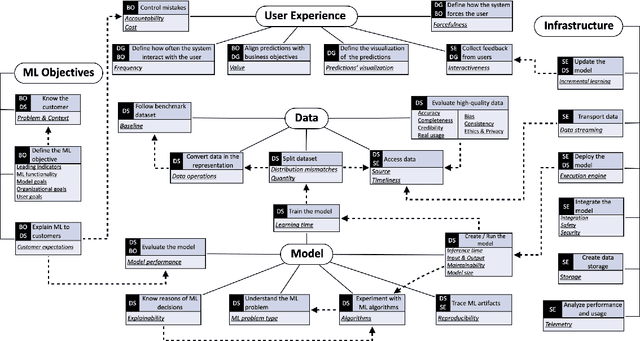
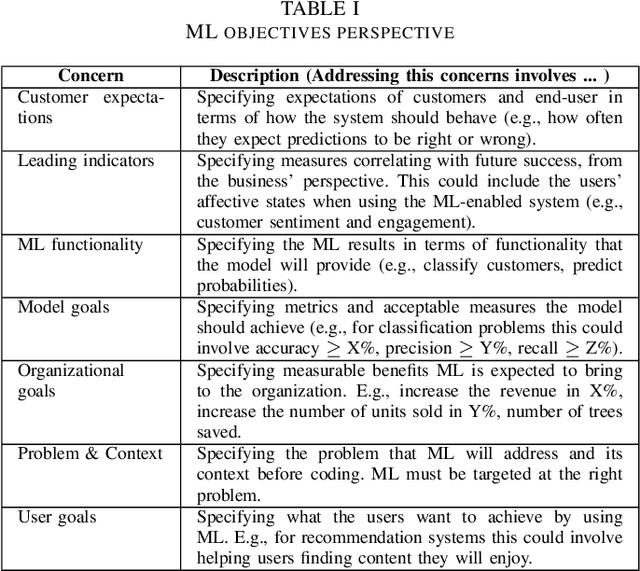
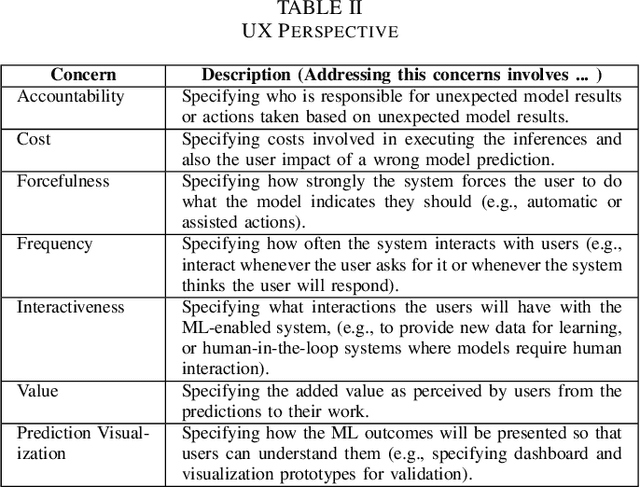
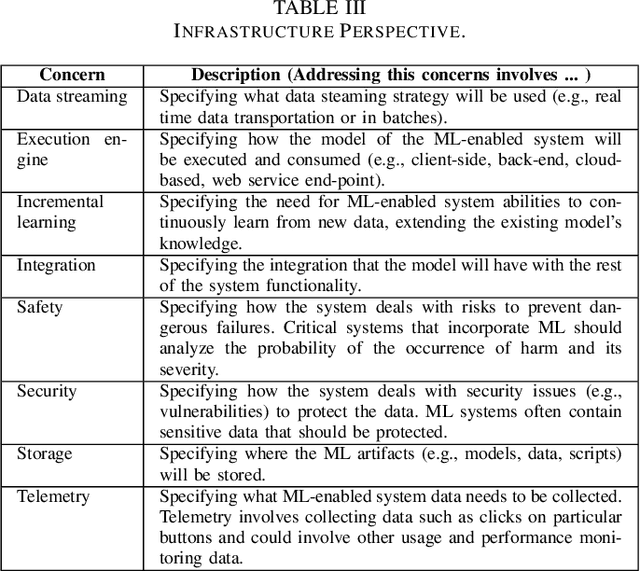
Machine learning (ML) teams often work on a project just to realize the performance of the model is not good enough. Indeed, the success of ML-enabled systems involves aligning data with business problems, translating them into ML tasks, experimenting with algorithms, evaluating models, capturing data from users, among others. Literature has shown that ML-enabled systems are rarely built based on precise specifications for such concerns, leading ML teams to become misaligned due to incorrect assumptions, which may affect the quality of such systems and overall project success. In order to help addressing this issue, this paper describes our work towards a perspective-based approach for specifying ML-enabled systems. The approach involves analyzing a set of 45 ML concerns grouped into five perspectives: objectives, user experience, infrastructure, model, and data. The main contribution of this paper is to provide two new artifacts that can be used to help specifying ML-enabled systems: (i) the perspective-based ML task and concern diagram and (ii) the perspective-based ML specification template.