 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Model Size Matter? A Comparison of Small and Large Language Models for Requirements Classification
Oct 24, 2025[Context and motivation] Large language models (LLMs) show notable results in natural language processing (NLP) tasks for requirements engineering (RE). However, their use is compromised by high computational cost, data sharing risks, and dependence on external services. In contrast, small language models (SLMs) offer a lightweight, locally deployable alternative. [Question/problem] It remains unclear how well SLMs perform compared to LLMs in RE tasks in terms of accuracy. [Results] Our preliminary study compares eight models, including three LLMs and five SLMs, on requirements classification tasks using the PROMISE, PROMISE Reclass, and SecReq datasets. Our results show that although LLMs achieve an average F1 score of 2% higher than SLMs, this difference is not statistically significant. SLMs almost reach LLMs performance across all datasets and even outperform them in recall on the PROMISE Reclass dataset, despite being up to 300 times smaller. We also found that dataset characteristics play a more significant role in performance than model size. [Contribution] Our study contributes with evidence that SLMs are a valid alternative to LLMs for requirements classification, offering advantages in privacy, cost, and local deployability.
How Effective are Generative Large Language Models in Performing Requirements Classification?
Apr 23, 2025In recent years, transformer-based large language models (LLMs) have revolutionised natural language processing (NLP), with generative models opening new possibilities for tasks that require context-aware text generation. Requirements engineering (RE) has also seen a surge in the experimentation of LLMs for different tasks, including trace-link detection, regulatory compliance, and others. Requirements classification is a common task in RE. While non-generative LLMs like BERT have been successfully applied to this task, there has been limited exploration of generative LLMs. This gap raises an important question: how well can generative LLMs, which produce context-aware outputs, perform in requirements classification? In this study, we explore the effectiveness of three generative LLMs-Bloom, Gemma, and Llama-in performing both binary and multi-class requirements classification. We design an extensive experimental study involving over 400 experiments across three widely used datasets (PROMISE NFR, Functional-Quality, and SecReq). Our study concludes that while factors like prompt design and LLM architecture are universally important, others-such as dataset variations-have a more situational impact, depending on the complexity of the classification task. This insight can guide future model development and deployment strategies, focusing on optimising prompt structures and aligning model architectures with task-specific needs for improved performance.
Model Generation from Requirements with LLMs: an Exploratory Study
Apr 09, 2024Complementing natural language (NL) requirements with graphical models can improve stakeholders' communication and provide directions for system design. However, creating models from requirements involves manual effort. The advent of generative large language models (LLMs), ChatGPT being a notable example, offers promising avenues for automated assistance in model generation. This paper investigates the capability of ChatGPT to generate a specific type of model, i.e., UML sequence diagrams, from NL requirements. We conduct a qualitative study in which we examine the sequence diagrams generated by ChatGPT for 28 requirements documents of various types and from different domains. Observations from the analysis of the generated diagrams have systematically been captured through evaluation logs, and categorized through thematic analysis. Our results indicate that, although the models generally conform to the standard and exhibit a reasonable level of understandability, their completeness and correctness with respect to the specified requirements often present challenges. This issue is particularly pronounced in the presence of requirements smells, such as ambiguity and inconsistency. The insights derived from this study can influence the practical utilization of LLMs in the RE process, and open the door to novel RE-specific prompting strategies targeting effective model generation.
Zero-Shot Learning for Requirements Classification: An Exploratory Study
Feb 09, 2023



Context and motivation: Requirements Engineering (RE) researchers have been experimenting Machine Learning (ML) and Deep Learning (DL) approaches for a range of RE tasks, such as requirements classification, requirements tracing, ambiguity detection, and modelling. Question-problem: Most of today's ML-DL approaches are based on supervised learning techniques, meaning that they need to be trained using annotated datasets to learn how to assign a class label to sample items from an application domain. This constraint poses an enormous challenge to RE researchers, as the lack of annotated datasets makes it difficult for them to fully exploit the benefit of advanced ML-DL technologies. Principal ideas-results: To address this challenge, this paper proposes an approach that employs the embedding-based unsupervised Zero-Shot Learning (ZSL) technique to perform requirements classification. We focus on the classification task because many RE tasks can be framed as classification problems. In this study, we demonstrate our approach for three tasks. (1) FR-NFR: classification functional requirements vs non-functional requirements; (2) NFR: identification of NFR classes; (3) Security: classification of security vs non-security requirements. The study shows that the ZSL approach achieves an F1 score of 0.66 for the FR-NFR task. For the NFR task, the approach yields F1 ~ 0.72-0.80, considering the most frequent classes. For the Security task, F1 ~ 0.66. All of the aforementioned F1 scores are achieved with zero-training efforts. Contribution: This study demonstrates the potential of ZSL for requirements classification. An important implication is that it is possible to have very little or no training data to perform multiple tasks. The proposed approach thus contributes to the solution of the longstanding problem of data shortage in RE.
Classification of Natural Language Processing Techniques for Requirements Engineering
Apr 08, 2022

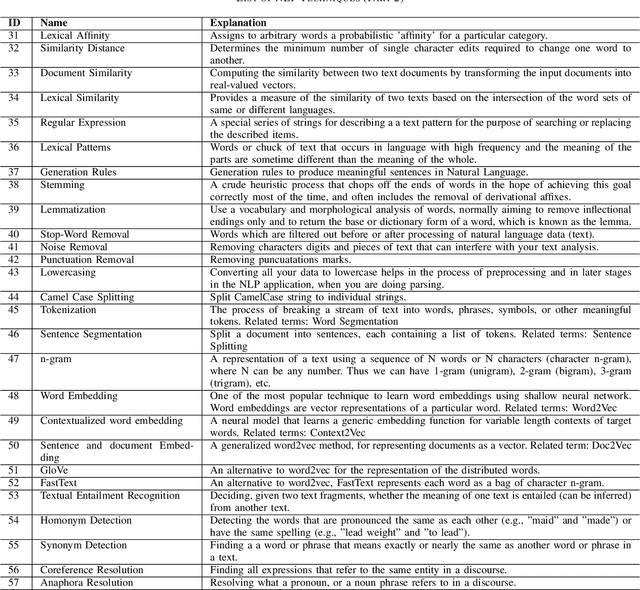
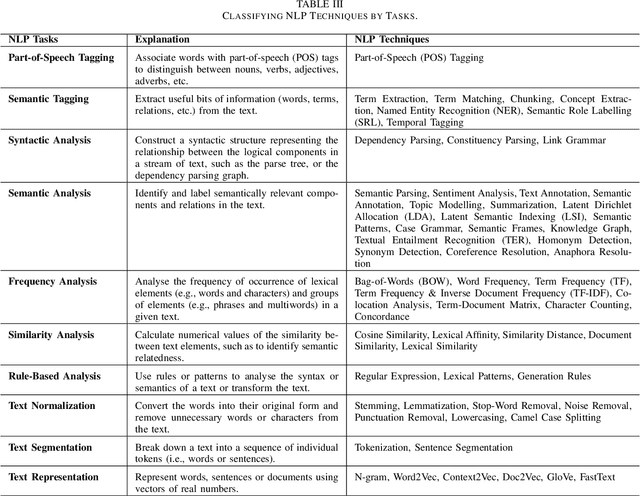
Research in applying natural language processing (NLP) techniques to requirements engineering (RE) tasks spans more than 40 years, from initial efforts carried out in the 1980s to more recent attempts with machine learning (ML) and deep learning (DL) techniques. However, in spite of the progress, our recent survey shows that there is still a lack of systematic understanding and organization of commonly used NLP techniques in RE. We believe one hurdle facing the industry is lack of shared knowledge of NLP techniques and their usage in RE tasks. In this paper, we present our effort to synthesize and organize 57 most frequently used NLP techniques in RE. We classify these NLP techniques in two ways: first, by their NLP tasks in typical pipelines and second, by their linguist analysis levels. We believe these two ways of classification are complementary, contributing to a better understanding of the NLP techniques in RE and such understanding is crucial to the development of better NLP tools for RE.
Using Voice and Biofeedback to Predict User Engagement during Requirements Interviews
Apr 06, 2021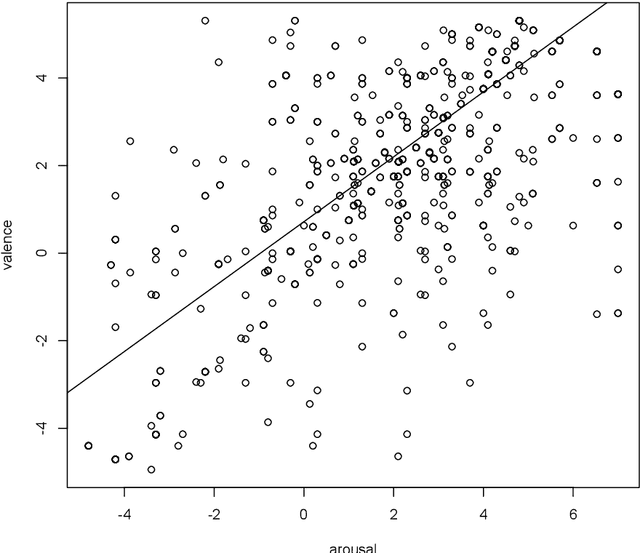

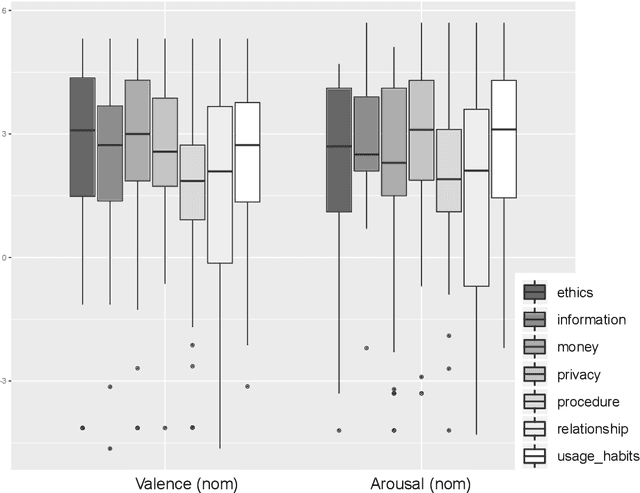

Capturing users engagement is crucial for gathering feedback about the features of a software product. In a market-driven context, current approaches to collect and analyze users feedback are based on techniques leveraging information extracted from product reviews and social media. These approaches are hardly applicable in bespoke software development, or in contexts in which one needs to gather information from specific users. In such cases, companies need to resort to face-to-face interviews to get feedback on their products. In this paper, we propose to utilize biometric data, in terms of physiological and voice features, to complement interviews with information about the engagement of the user on the discussed product-relevant topics. We evaluate our approach by interviewing users while gathering their physiological data (i.e., biofeedback) using an Empatica E4 wristband, and capturing their voice through the default audio-recorder of a common laptop. Our results show that we can predict users' engagement by training supervised machine learning algorithms on biometric data, and that voice features alone can be sufficiently effective. The performance of the prediction algorithms is maximised when pre-processing the training data with the synthetic minority oversampling technique (SMOTE). The results of our work suggest that biofeedback and voice analysis can be used to facilitate prioritization of requirements oriented to product improvement, and to steer the interview based on users' engagement. Furthermore, the usage of voice features can be particularly helpful for emotion-aware requirements elicitation in remote communication, either performed by human analysts or voice-based chatbots.