 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Generation from Requirements with LLMs: an Exploratory Study
Apr 09, 2024Complementing natural language (NL) requirements with graphical models can improve stakeholders' communication and provide directions for system design. However, creating models from requirements involves manual effort. The advent of generative large language models (LLMs), ChatGPT being a notable example, offers promising avenues for automated assistance in model generation. This paper investigates the capability of ChatGPT to generate a specific type of model, i.e., UML sequence diagrams, from NL requirements. We conduct a qualitative study in which we examine the sequence diagrams generated by ChatGPT for 28 requirements documents of various types and from different domains. Observations from the analysis of the generated diagrams have systematically been captured through evaluation logs, and categorized through thematic analysis. Our results indicate that, although the models generally conform to the standard and exhibit a reasonable level of understandability, their completeness and correctness with respect to the specified requirements often present challenges. This issue is particularly pronounced in the presence of requirements smells, such as ambiguity and inconsistency. The insights derived from this study can influence the practical utilization of LLMs in the RE process, and open the door to novel RE-specific prompting strategies targeting effective model generation.
A Multi-solution Study on GDPR AI-enabled Completeness Checking of DPAs
Nov 23, 2023



Specifying legal requirements for software systems to ensure their compliance with the applicable regulations is a major concern to requirements engineering (RE). Personal data which is collected by an organization is often shared with other organizations to perform certain processing activities. In such cases, the General Data Protection Regulation (GDPR) requires issuing a data processing agreement (DPA) which regulates the processing and further ensures that personal data remains protected. Violating GDPR can lead to huge fines reaching to billions of Euros. Software systems involving personal data processing must adhere to the legal obligations stipulated in GDPR and outlined in DPAs. Requirements engineers can elicit from DPAs legal requirements for regulating the data processing activities in software systems. Checking the completeness of a DPA according to the GDPR provisions is therefore an essential prerequisite to ensure that the elicited requirements are complete. Analyzing DPAs entirely manually is time consuming and requires adequate legal expertise. In this paper, we propose an automation strategy to address the completeness checking of DPAs against GDPR. Specifically, we pursue ten alternative solutions which are enabled by different technologies, namely traditional machine learning, deep learning, language modeling, and few-shot learning. The goal of our work is to empirically examine how these different technologies fare in the legal domain. We computed F2 score on a set of 30 real DPAs. Our evaluation shows that best-performing solutions yield F2 score of 86.7% and 89.7% are based on pre-trained BERT and RoBERTa language models. Our analysis further shows that other alternative solutions based on deep learning (e.g., BiLSTM) and few-shot learning (e.g., SetFit) can achieve comparable accuracy, yet are more efficient to develop.
Legal Requirements Analysis
Nov 23, 2023Modern software has been an integral part of everyday activities in many disciplines and application contexts. Introducing intelligent automation by leveraging artificial intelligence (AI) led to break-throughs in many fields. The effectiveness of AI can be attributed to several factors, among which is the increasing availability of data. Regulations such as the general data protection regulation (GDPR) in the European Union (EU) are introduced to ensure the protection of personal data. Software systems that collect, process, or share personal data are subject to compliance with such regulations. Developing compliant software depends heavily on addressing legal requirements stipulated in applicable regulations, a central activity in the requirements engineering (RE) phase of the software development process. RE is concerned with specifying and maintaining requirements of a system-to-be, including legal requirements. Legal agreements which describe the policies organizations implement for processing personal data can provide an additional source to regulations for eliciting legal requirements. In this chapter, we explore a variety of methods for analyzing legal requirements and exemplify them on GDPR. Specifically, we describe possible alternatives for creating machine-analyzable representations from regulations, survey the existing automated means for enabling compliance verification against regulations, and further reflect on the current challenges of legal requirements analysis.
TAPHSIR: Towards AnaPHoric Ambiguity Detection and ReSolution In Requirements
Jun 21, 2022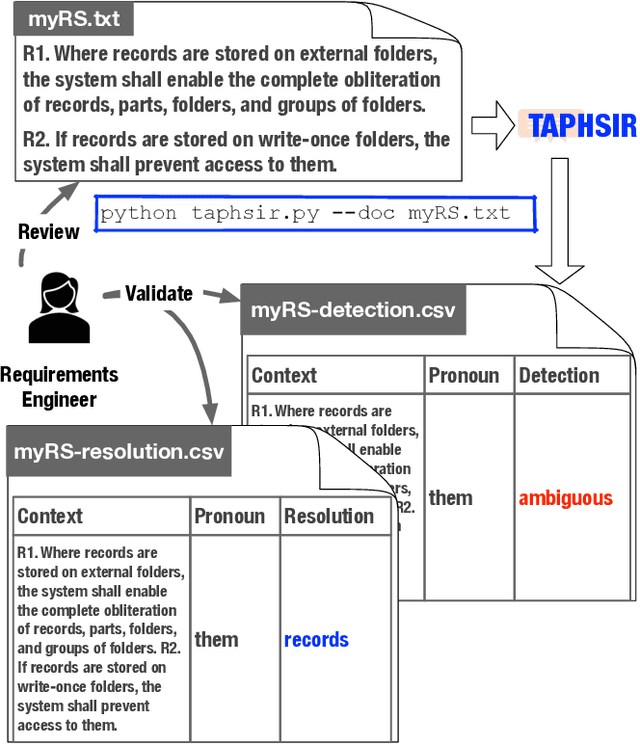
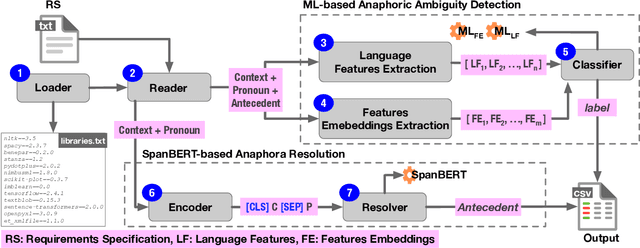
We introduce TAPHSIR, a tool for anaphoric ambiguity detection and anaphora resolution in requirements. TAPHSIR facilities reviewing the use of pronouns in a requirements specification and revising those pronouns that can lead to misunderstandings during the development process. To this end, TAPHSIR detects the requirements which have potential anaphoric ambiguity and further attempts interpreting anaphora occurrences automatically. TAPHSIR employs a hybrid solution composed of an ambiguity detection solution based on machine learning and an anaphora resolution solution based on a variant of the BERT language model. Given a requirements specification, TAPHSIR decides for each pronoun occurrence in the specification whether the pronoun is ambiguous or unambiguous, and further provides an automatic interpretation for the pronoun. The output generated by TAPHSIR can be easily reviewed and validated by requirements engineers. TAPHSIR is publicly available on Zenodo (DOI: 10.5281/zenodo.5902117).
AI-enabled Automation for Completeness Checking of Privacy Policies
Jun 10, 2021
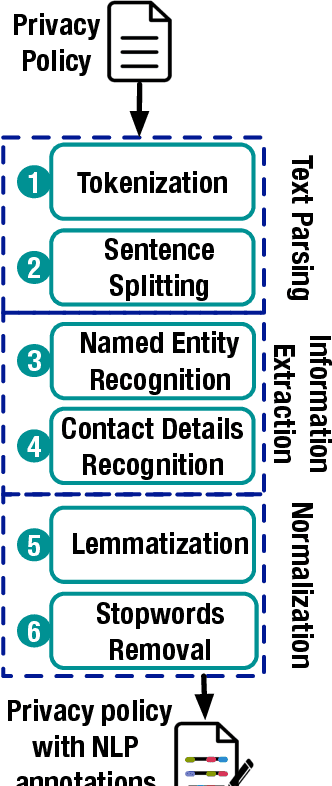
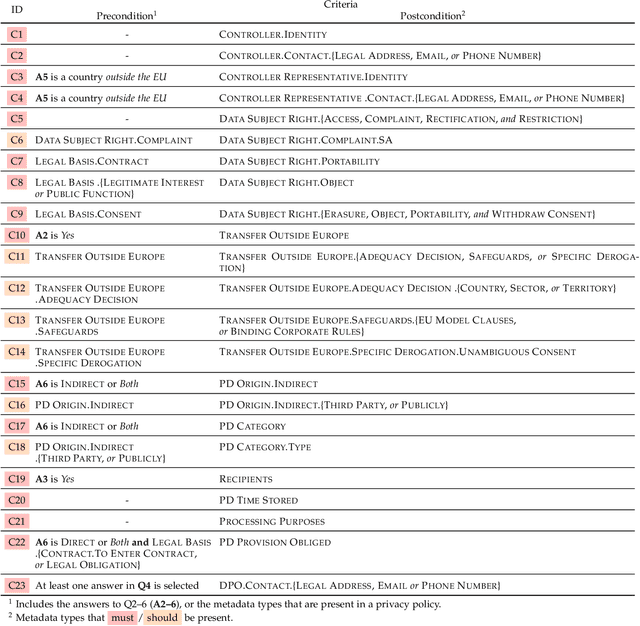

Technological advances in information sharing have raised concerns about data protection. Privacy policies contain privacy-related requirements about how the personal data of individuals will be handled by an organization or a software system (e.g., a web service or an app). In Europe, privacy policies are subject to compliance with the General Data Protection Regulation (GDPR). A prerequisite for GDPR compliance checking is to verify whether the content of a privacy policy is complete according to the provisions of GDPR. Incomplete privacy policies might result in large fines on violating organization as well as incomplete privacy-related software specifications. Manual completeness checking is both time-consuming and error-prone. In this paper, we propose AI-based automation for the completeness checking of privacy policies. Through systematic qualitative methods, we first build two artifacts to characterize the privacy-related provisions of GDPR, namely a conceptual model and a set of completeness criteria. Then, we develop an automated solution on top of these artifacts by leveraging a combination of natural language processing and supervised machine learning. Specifically, we identify the GDPR-relevant information content in privacy policies and subsequently check them against the completeness criteria. To evaluate our approach, we collected 234 real privacy policies from the fund industry. Over a set of 48 unseen privacy policies, our approach detected 300 of the total of 334 violations of some completeness criteria correctly, while producing 23 false positives. The approach thus has a precision of 92.9% and recall of 89.8%. Compared to a baseline that applies keyword search only, our approach results in an improvement of 24.5% in precision and 38% in recall.
D-Bees: A Novel Method Inspired by Bee Colony Optimization for Solving Word Sense Disambiguation
May 06, 2014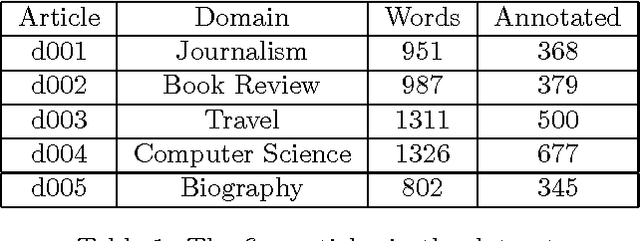
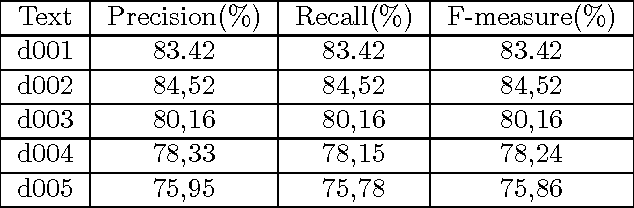
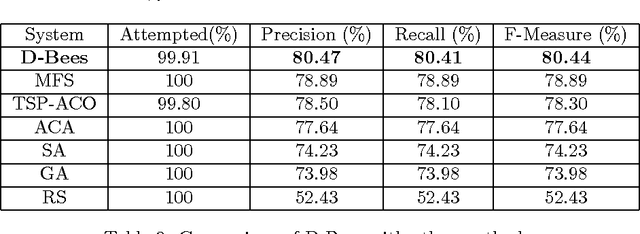
Word sense disambiguation (WSD) is a problem in the field of computational linguistics given as finding the intended sense of a word (or a set of words) when it is activated within a certain context. WSD was recently addressed as a combinatorial optimization problem in which the goal is to find a sequence of senses that maximize the semantic relatedness among the target words. In this article, a novel algorithm for solving the WSD problem called D-Bees is proposed which is inspired by bee colony optimization (BCO)where artificial bee agents collaborate to solve the problem. The D-Bees algorithm is evaluated on a standard dataset (SemEval 2007 coarse-grained English all-words task corpus)and is compared to simulated annealing, genetic algorithms, and two ant colony optimization techniques (ACO). It will be observed that the BCO and ACO approaches are on par.