 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-enabled Automation for Completeness Checking of Privacy Policies
Jun 10, 2021
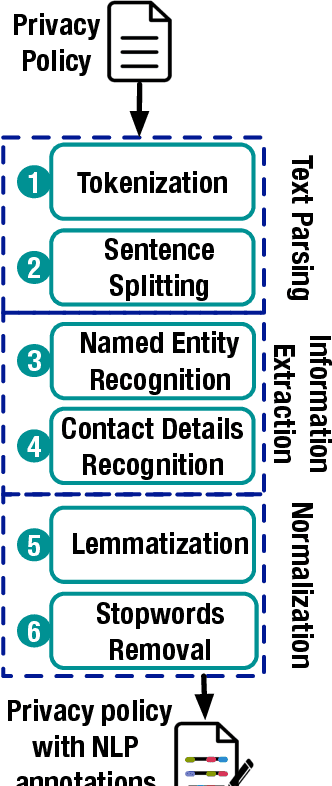
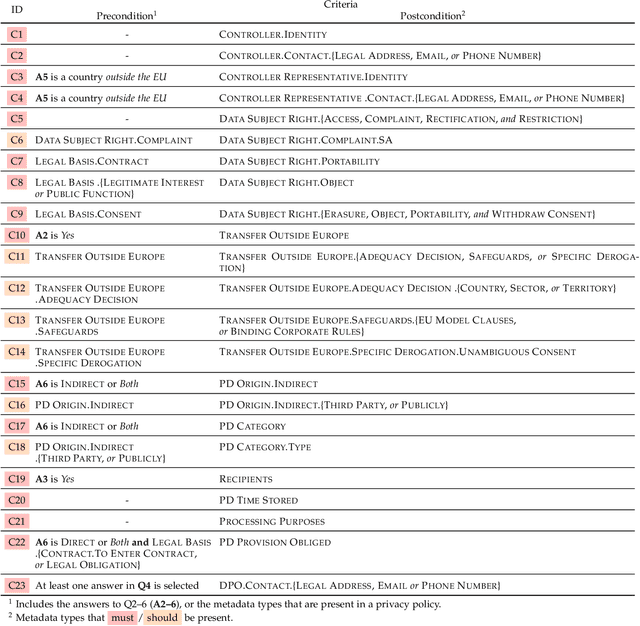

Technological advances in information sharing have raised concerns about data protection. Privacy policies contain privacy-related requirements about how the personal data of individuals will be handled by an organization or a software system (e.g., a web service or an app). In Europe, privacy policies are subject to compliance with the General Data Protection Regulation (GDPR). A prerequisite for GDPR compliance checking is to verify whether the content of a privacy policy is complete according to the provisions of GDPR. Incomplete privacy policies might result in large fines on violating organization as well as incomplete privacy-related software specifications. Manual completeness checking is both time-consuming and error-prone. In this paper, we propose AI-based automation for the completeness checking of privacy policies. Through systematic qualitative methods, we first build two artifacts to characterize the privacy-related provisions of GDPR, namely a conceptual model and a set of completeness criteria. Then, we develop an automated solution on top of these artifacts by leveraging a combination of natural language processing and supervised machine learning. Specifically, we identify the GDPR-relevant information content in privacy policies and subsequently check them against the completeness criteria. To evaluate our approach, we collected 234 real privacy policies from the fund industry. Over a set of 48 unseen privacy policies, our approach detected 300 of the total of 334 violations of some completeness criteria correctly, while producing 23 false positives. The approach thus has a precision of 92.9% and recall of 89.8%. Compared to a baseline that applies keyword search only, our approach results in an improvement of 24.5% in precision and 38% in recall.
On Systematically Building a Controlled Natural Language for Functional Requirements
May 04, 2020
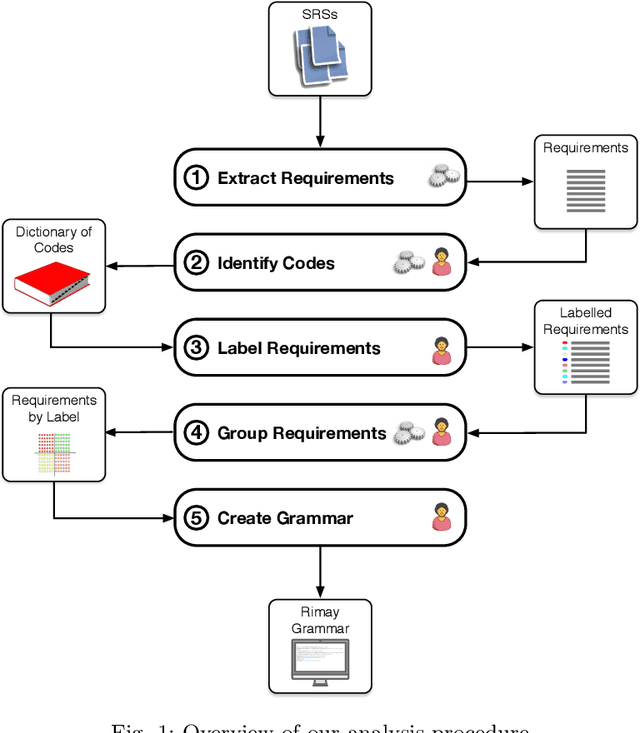
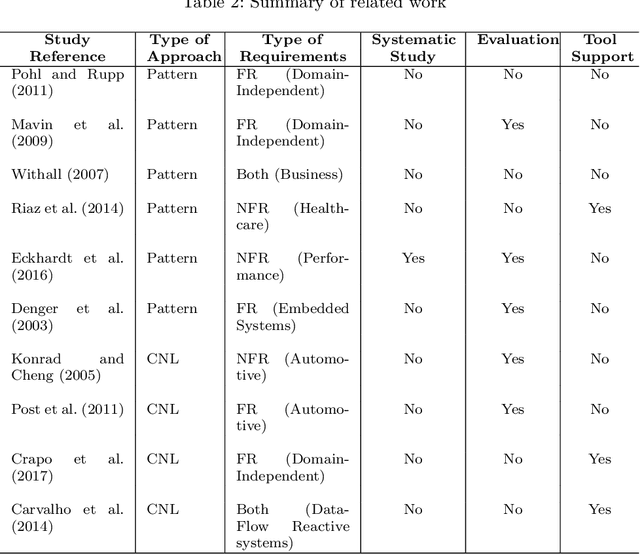

[Context] Natural language (NL) is pervasive in software requirements specifications (SRSs). However, despite its popularity and widespread use, NL is highly prone to quality issues such as vagueness, ambiguity, and incompleteness. Controlled natural languages (CNLs) have been proposed as a way to prevent quality problems in requirements documents, while maintaining the flexibility to write and communicate requirements in an intuitive and universally understood manner. [Objective] In collaboration with an industrial partner from the financial domain, we systematically develop and evaluate a CNL, named Rimay, intended at helping analysts write functional requirements. [Method] We rely on Grounded Theory for building Rimay and follow well-known guidelines for conducting and reporting industrial case study research. [Results] Our main contributions are: (1) a qualitative methodology to systematically define a CNL for functional requirements; this methodology is general and applicable to information systems beyond the financial domain, (2) a CNL grammar to represent functional requirements; this grammar is derived from our experience in the financial domain, but should be applicable, possibly with adaptations, to other information-system domains, and (3) an empirical evaluation of our CNL (Rimay) through an industrial case study. Our contributions draw on 15 representative SRSs, collectively containing 3215 NL requirements statements from the financial domain. [Conclusion] Our evaluation shows that Rimay is expressive enough to capture, on average, 88% (405 out of 460) of the NL requirements statements in four previously unseen SRSs from the financial domain.