 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReqBrain: Task-Specific Instruction Tuning of LLMs for AI-Assisted Requirements Generation
May 23, 2025Requirements elicitation and specification remains a labor-intensive, manual process prone to inconsistencies and gaps, presenting a significant challenge in modern software engineering. Emerging studies underscore the potential of employing large language models (LLMs) for automated requirements generation to support requirements elicitation and specification; however, it remains unclear how to implement this effectively. In this work, we introduce ReqBrain, an Al-assisted tool that employs a fine-tuned LLM to generate authentic and adequate software requirements. Software engineers can engage with ReqBrain through chat-based sessions to automatically generate software requirements and categorize them by type. We curated a high-quality dataset of ISO 29148-compliant requirements and fine-tuned five 7B-parameter LLMs to determine the most effective base model for ReqBrain. The top-performing model, Zephyr-7b-beta, achieved 89.30\% Fl using the BERT score and a FRUGAL score of 91.20 in generating authentic and adequate requirements. Human evaluations further confirmed ReqBrain's effectiveness in generating requirements. Our findings suggest that generative Al, when fine-tuned, has the potential to improve requirements elicitation and specification, paving the way for future extensions into areas such as defect identification, test case generation, and agile user story creation.
Detecting Requirements Smells With Deep Learning: Experiences, Challenges and Future Work
Aug 06, 2021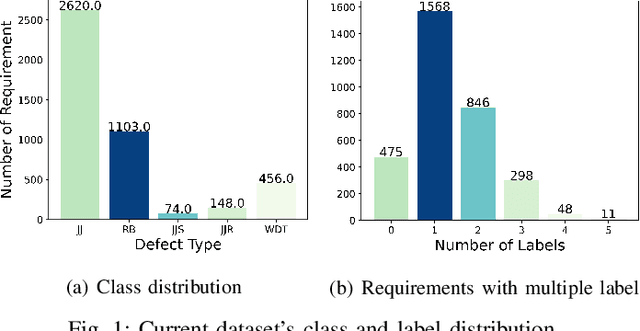
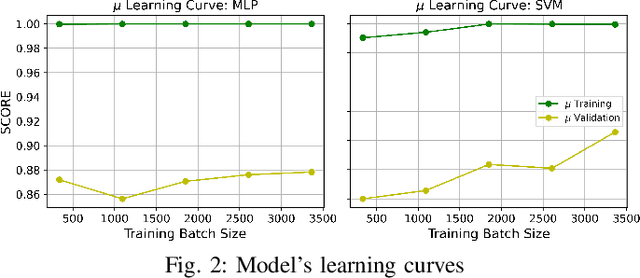
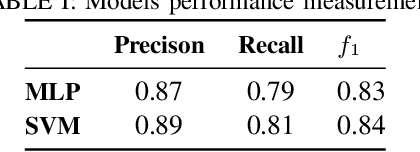
Requirements Engineering (RE) is the initial step towards building a software system. The success or failure of a software project is firmly tied to this phase, based on communication among stakeholders using natural language. The problem with natural language is that it can easily lead to different understandings if it is not expressed precisely by the stakeholders involved, which results in building a product different from the expected one. Previous work proposed to enhance the quality of the software requirements detecting language errors based on ISO 29148 requirements language criteria. The existing solutions apply classical Natural Language Processing (NLP) to detect them. NLP has some limitations, such as domain dependability which results in poor generalization capability. Therefore, this work aims to improve the previous work by creating a manually labeled dataset and using ensemble learning, Deep Learning (DL), and techniques such as word embeddings and transfer learning to overcome the generalization problem that is tied with classical NLP and improve precision and recall metrics using a manually labeled dataset. The current findings show that the dataset is unbalanced and which class examples should be added more. It is tempting to train algorithms even if the dataset is not considerably representative. Whence, the results show that models are overfitting; in Machine Learning this issue is solved by adding more instances to the dataset, improving label quality, removing noise, and reducing the learning algorithms complexity, which is planned for this research.
Conversational Agents for Insurance Companies: From Theory to Practice
Dec 18, 2019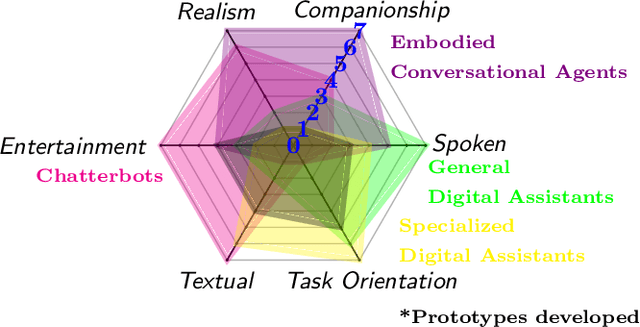

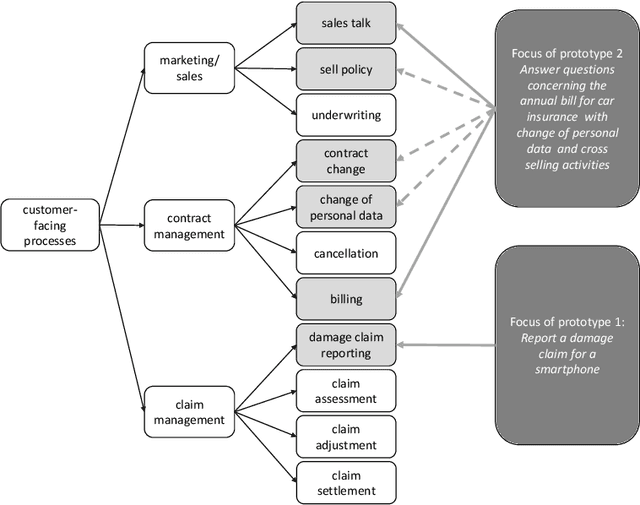

Advances in artificial intelligence have renewed interest in conversational agents. Additionally to software developers, today all kinds of employees show interest in new technologies and their possible applications for customers. German insurance companies generally are interested in improving their customer service and digitizing their business processes. In this work we investigate the potential use of conversational agents in insurance companies theoretically by determining which classes of agents exist which are of interest to insurance companies, finding relevant use cases and requirements. We add two practical parts: First we develop a showcase prototype for an exemplary insurance scenario in claim management. Additionally in a second step, we create a prototype focusing on customer service in a chatbot hackathon, fostering innovation in interdisciplinary teams. In this work, we describe the results of both prototypes in detail. We evaluate both chatbots defining criteria for both settings in detail and compare the results and draw conclusions for the maturity of chatbot technology for practical use, describing the opportunities and challenges companies, especially small and medium enterprises, face.
* 26 pages, 7 figures. ICAART 2019 extension. Extension of arXiv:1812.07339
The Evolution of Sentiment Analysis - A Review of Research Topics, Venues, and Top Cited Papers
Nov 21, 2017
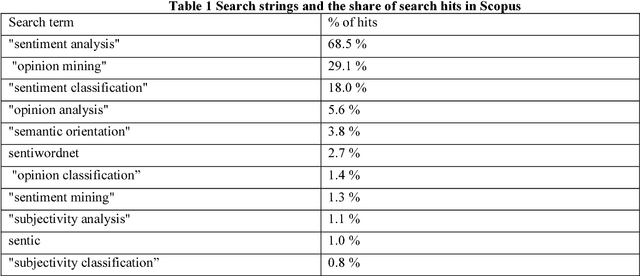


Sentiment analysis is one of the fastest growing research areas in computer science, making it challenging to keep track of all the activities in the area. We present a computer-assisted literature review, where we utilize both text mining and qualitative coding, and analyze 6,996 papers from Scopus. We find that the roots of sentiment analysis are in the studies on public opinion analysis at the beginning of 20th century and in the text subjectivity analysis performed by the computational linguistics community in 1990's. However, the outbreak of computer-based sentiment analysis only occurred with the availability of subjective texts on the Web. Consequently, 99% of the papers have been published after 2004. Sentiment analysis papers are scattered to multiple publication venues, and the combined number of papers in the top-15 venues only represent ca. 30% of the papers in total. We present the top-20 cited papers from Google Scholar and Scopus and a taxonomy of research topics. In recent years, sentiment analysis has shifted from analyzing online product reviews to social media texts from Twitter and Facebook. Many topics beyond product reviews like stock markets, elections, disasters, medicine, software engineering and cyberbullying extend the utilization of sentiment analysis
* 29 pages, 14 figures