 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Representation Models for Text Classification with AutoML Tools
Jul 07, 2021



Automated Machine Learning (AutoML) has gained increasing success on tabular data in recent years. However, processing unstructured data like text is a challenge and not widely supported by open-source AutoML tools. This work compares three manually created text representations and text embeddings automatically created by AutoML tools. Our benchmark includes four popular open-source AutoML tools and eight datasets for text classification purposes. The results show that straightforward text representations perform better than AutoML tools with automatically created text embeddings.
Leveraging Automated Machine Learning for Text Classification: Evaluation of AutoML Tools and Comparison with Human Performance
Dec 07, 2020
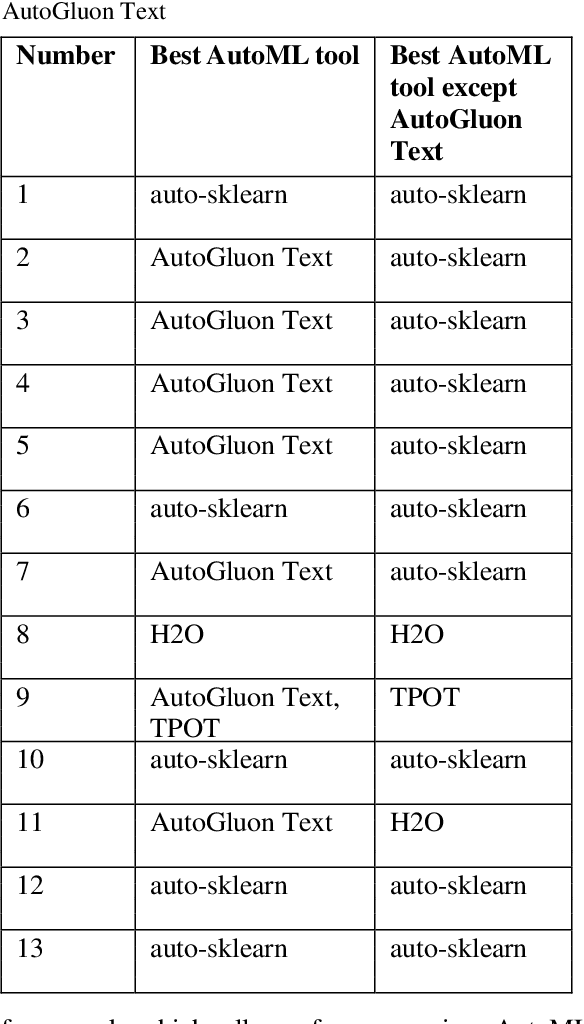

Recently, Automated Machine Learning (AutoML) has registered increasing success with respect to tabular data. However, the question arises whether AutoML can also be applied effectively to text classification tasks. This work compares four AutoML tools on 13 different popular datasets, including Kaggle competitions, and opposes human performance. The results show that the AutoML tools perform better than the machine learning community in 4 out of 13 tasks and that two stand out.
Can AutoML outperform humans? An evaluation on popular OpenML datasets using AutoML Benchmark
Sep 03, 2020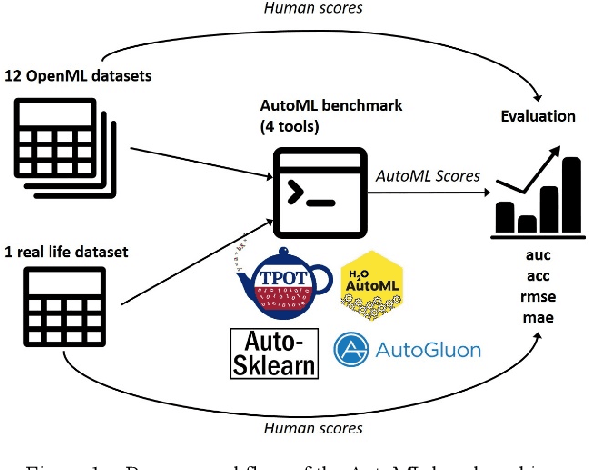
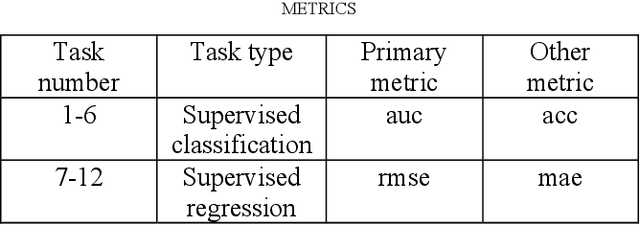
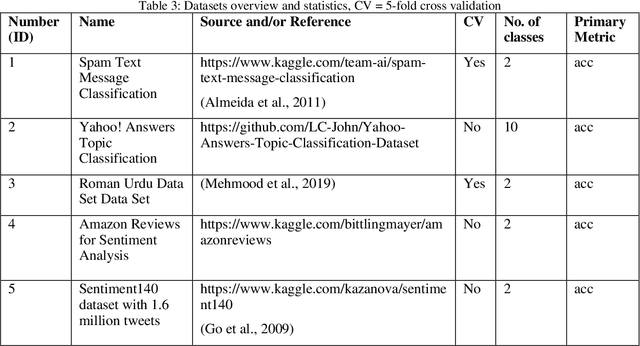
In the last few years, Automated Machine Learning (AutoML) has gained much attention. With that said, the question arises whether AutoML can outperform results achieved by human data scientists. This paper compares four AutoML frameworks on 12 different popular datasets from OpenML; six of them supervised classification tasks and the other six supervised regression ones. Additionally, we consider a real-life dataset from one of our recent projects. The results show that the automated frameworks perform better or equal than the machine learning community in 7 out of 12 OpenML tasks.
Conversational Agents for Insurance Companies: From Theory to Practice
Dec 18, 2019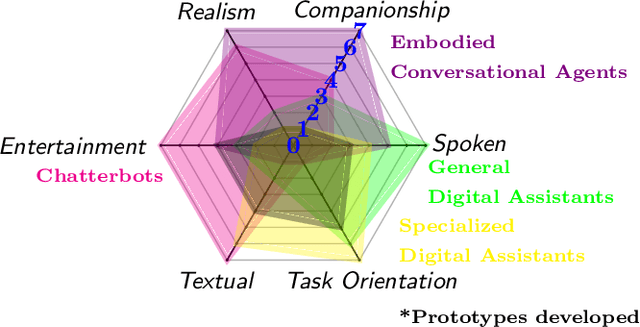

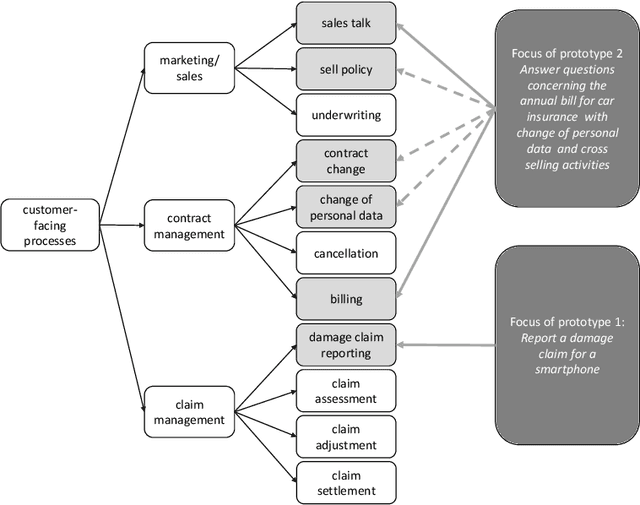

Advances in artificial intelligence have renewed interest in conversational agents. Additionally to software developers, today all kinds of employees show interest in new technologies and their possible applications for customers. German insurance companies generally are interested in improving their customer service and digitizing their business processes. In this work we investigate the potential use of conversational agents in insurance companies theoretically by determining which classes of agents exist which are of interest to insurance companies, finding relevant use cases and requirements. We add two practical parts: First we develop a showcase prototype for an exemplary insurance scenario in claim management. Additionally in a second step, we create a prototype focusing on customer service in a chatbot hackathon, fostering innovation in interdisciplinary teams. In this work, we describe the results of both prototypes in detail. We evaluate both chatbots defining criteria for both settings in detail and compare the results and draw conclusions for the maturity of chatbot technology for practical use, describing the opportunities and challenges companies, especially small and medium enterprises, face.
* 26 pages, 7 figures. ICAART 2019 extension. Extension of arXiv:1812.07339
Comparing Attention-based Convolutional and Recurrent Neural Networks: Success and Limitations in Machine Reading Comprehension
Aug 27, 2018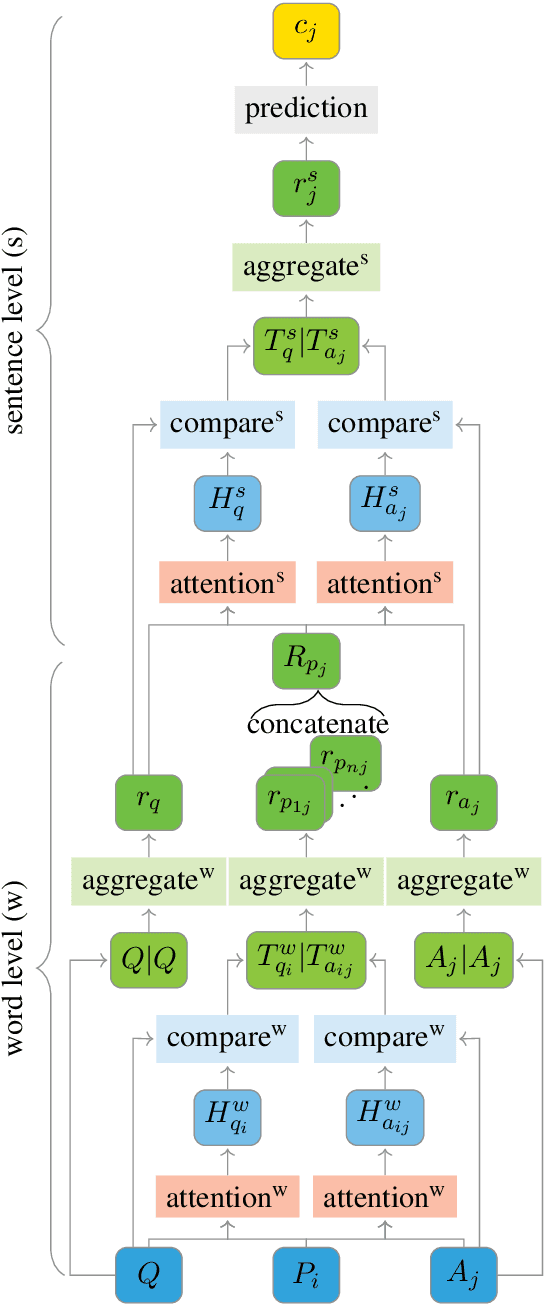
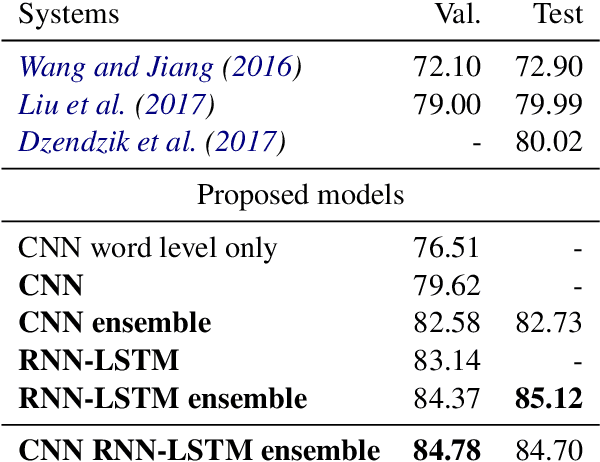

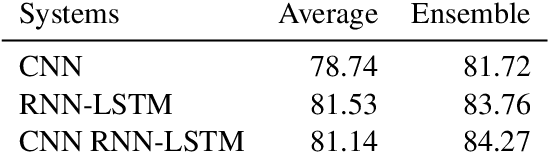
We propose a machine reading comprehension model based on the compare-aggregate framework with two-staged attention that achieves state-of-the-art results on the MovieQA question answering dataset. To investigate the limitations of our model as well as the behavioral difference between convolutional and recurrent neural networks, we generate adversarial examples to confuse the model and compare to human performance. Furthermore, we assess the generalizability of our model by analyzing its differences to human inference,