 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Representation Models for Text Classification with AutoML Tools
Jul 07, 2021



Automated Machine Learning (AutoML) has gained increasing success on tabular data in recent years. However, processing unstructured data like text is a challenge and not widely supported by open-source AutoML tools. This work compares three manually created text representations and text embeddings automatically created by AutoML tools. Our benchmark includes four popular open-source AutoML tools and eight datasets for text classification purposes. The results show that straightforward text representations perform better than AutoML tools with automatically created text embeddings.
VitrAI -- Applying Explainable AI in the Real World
Feb 12, 2021


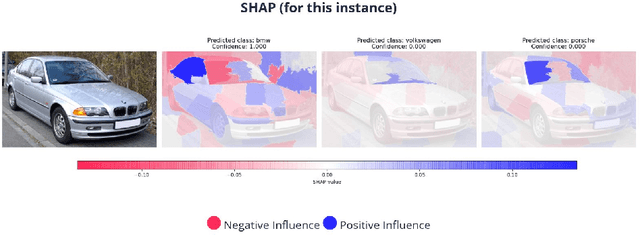
With recent progress in the field of Explainable Artificial Intelligence (XAI) and increasing use in practice, the need for an evaluation of different XAI methods and their explanation quality in practical usage scenarios arises. For this purpose, we present VitrAI, which is a web-based service with the goal of uniformly demonstrating four different XAI algorithms in the context of three real life scenarios and evaluating their performance and comprehensibility for humans. This work reveals practical obstacles when adopting XAI methods and gives qualitative estimates on how well different approaches perform in said scenarios.
Leveraging Automated Machine Learning for Text Classification: Evaluation of AutoML Tools and Comparison with Human Performance
Dec 07, 2020
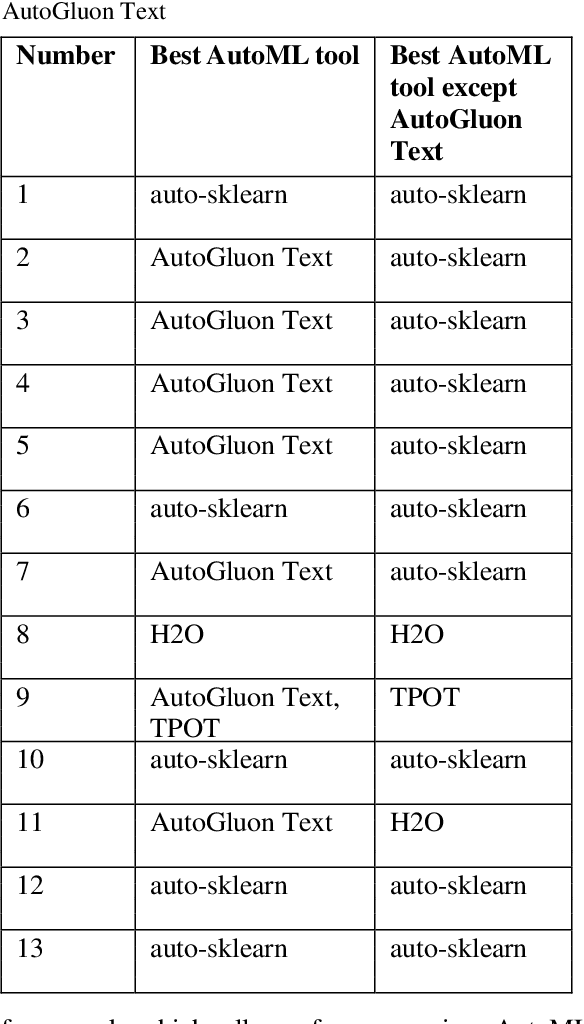

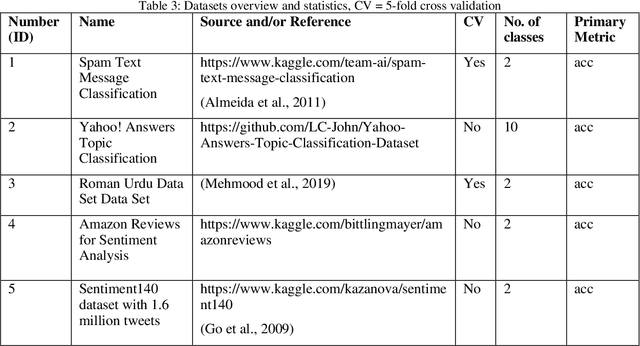
Recently, Automated Machine Learning (AutoML) has registered increasing success with respect to tabular data. However, the question arises whether AutoML can also be applied effectively to text classification tasks. This work compares four AutoML tools on 13 different popular datasets, including Kaggle competitions, and opposes human performance. The results show that the AutoML tools perform better than the machine learning community in 4 out of 13 tasks and that two stand out.
Can AutoML outperform humans? An evaluation on popular OpenML datasets using AutoML Benchmark
Sep 03, 2020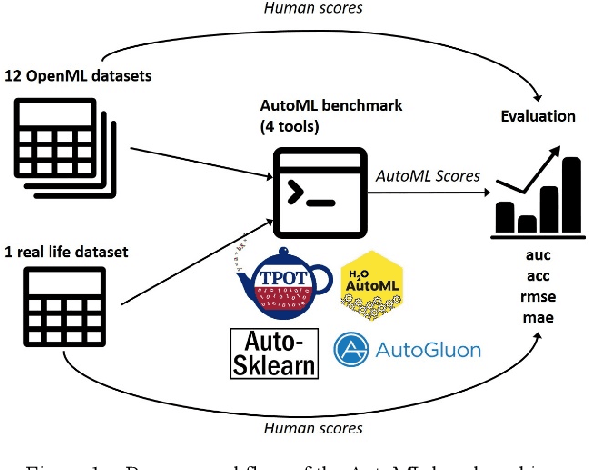
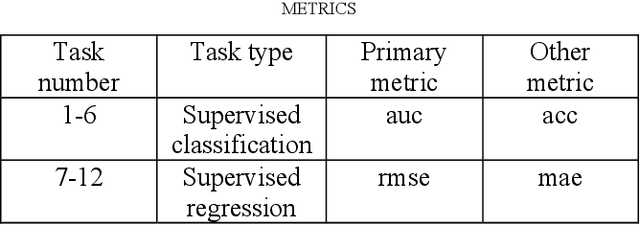
In the last few years, Automated Machine Learning (AutoML) has gained much attention. With that said, the question arises whether AutoML can outperform results achieved by human data scientists. This paper compares four AutoML frameworks on 12 different popular datasets from OpenML; six of them supervised classification tasks and the other six supervised regression ones. Additionally, we consider a real-life dataset from one of our recent projects. The results show that the automated frameworks perform better or equal than the machine learning community in 7 out of 12 OpenML tasks.