 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Embeddings and Domain Knowledge for Job Posting Duplicate Detection
Jun 10, 2024

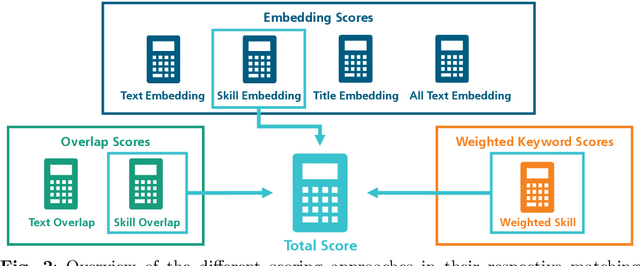
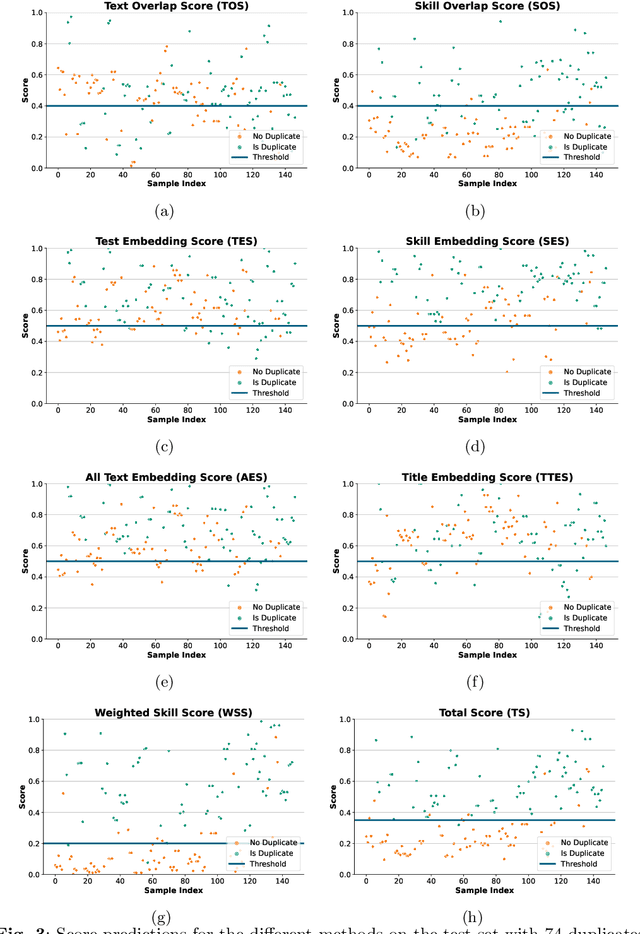
Job descriptions are posted on many online channels, including company websites, job boards or social media platforms. These descriptions are usually published with varying text for the same job, due to the requirements of each platform or to target different audiences. However, for the purpose of automated recruitment and assistance of people working with these texts, it is helpful to aggregate job postings across platforms and thus detect duplicate descriptions that refer to the same job. In this work, we propose an approach for detecting duplicates in job descriptions. We show that combining overlap-based character similarity with text embedding and keyword matching methods lead to convincing results. In particular, we show that although no approach individually achieves satisfying performance, a combination of string comparison, deep textual embeddings, and the use of curated weighted lookup lists for specific skills leads to a significant boost in overall performance. A tool based on our approach is being used in production and feedback from real-life use confirms our evaluation.
Fine-tuning and aligning question answering models for complex information extraction tasks
Sep 26, 2023The emergence of Large Language Models (LLMs) has boosted performance and possibilities in various NLP tasks. While the usage of generative AI models like ChatGPT opens up new opportunities for several business use cases, their current tendency to hallucinate fake content strongly limits their applicability to document analysis, such as information retrieval from documents. In contrast, extractive language models like question answering (QA) or passage retrieval models guarantee query results to be found within the boundaries of an according context document, which makes them candidates for more reliable information extraction in productive environments of companies. In this work we propose an approach that uses and integrates extractive QA models for improved feature extraction of German business documents such as insurance reports or medical leaflets into a document analysis solution. We further show that fine-tuning existing German QA models boosts performance for tailored extraction tasks of complex linguistic features like damage cause explanations or descriptions of medication appearance, even with using only a small set of annotated data. Finally, we discuss the relevance of scoring metrics for evaluating information extraction tasks and deduce a combined metric from Levenshtein distance, F1-Score, Exact Match and ROUGE-L to mimic the assessment criteria from human experts.
Combining Deep Learning and Reasoning for Address Detection in Unstructured Text Documents
Feb 07, 2022
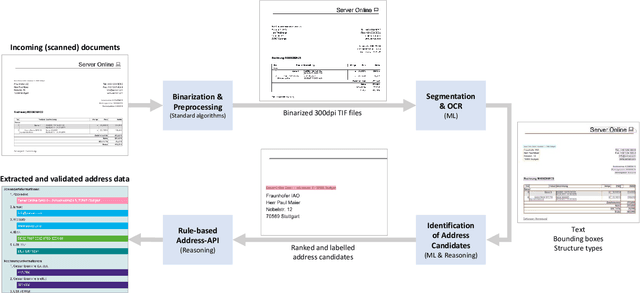

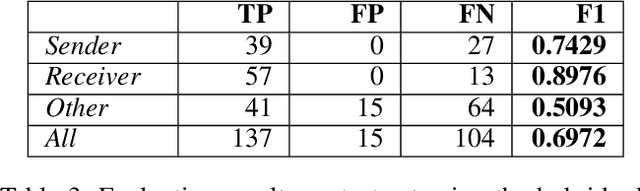
Extracting information from unstructured text documents is a demanding task, since these documents can have a broad variety of different layouts and a non-trivial reading order, like it is the case for multi-column documents or nested tables. Additionally, many business documents are received in paper form, meaning that the textual contents need to be digitized before further analysis. Nonetheless, automatic detection and capturing of crucial document information like the sender address would boost many companies' processing efficiency. In this work we propose a hybrid approach that combines deep learning with reasoning for finding and extracting addresses from unstructured text documents. We use a visual deep learning model to detect the boundaries of possible address regions on the scanned document images and validate these results by analyzing the containing text using domain knowledge represented as a rule based system.
Evaluation of Representation Models for Text Classification with AutoML Tools
Jul 07, 2021



Automated Machine Learning (AutoML) has gained increasing success on tabular data in recent years. However, processing unstructured data like text is a challenge and not widely supported by open-source AutoML tools. This work compares three manually created text representations and text embeddings automatically created by AutoML tools. Our benchmark includes four popular open-source AutoML tools and eight datasets for text classification purposes. The results show that straightforward text representations perform better than AutoML tools with automatically created text embeddings.
VitrAI -- Applying Explainable AI in the Real World
Feb 12, 2021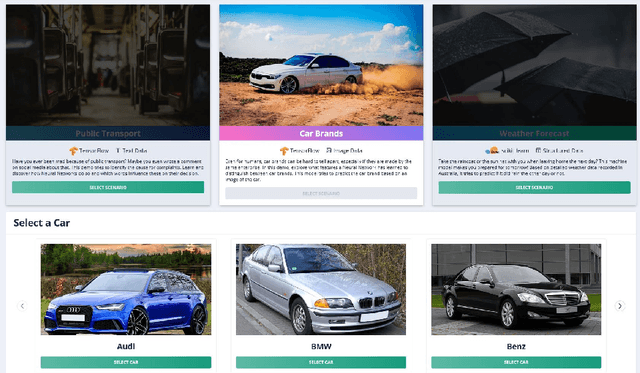


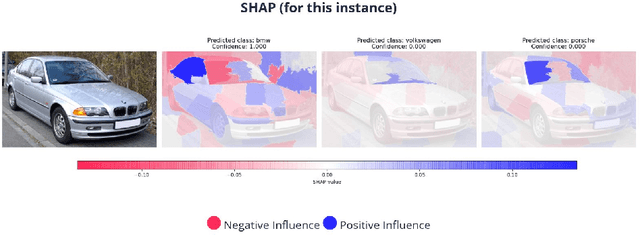
With recent progress in the field of Explainable Artificial Intelligence (XAI) and increasing use in practice, the need for an evaluation of different XAI methods and their explanation quality in practical usage scenarios arises. For this purpose, we present VitrAI, which is a web-based service with the goal of uniformly demonstrating four different XAI algorithms in the context of three real life scenarios and evaluating their performance and comprehensibility for humans. This work reveals practical obstacles when adopting XAI methods and gives qualitative estimates on how well different approaches perform in said scenarios.
Leveraging Automated Machine Learning for Text Classification: Evaluation of AutoML Tools and Comparison with Human Performance
Dec 07, 2020
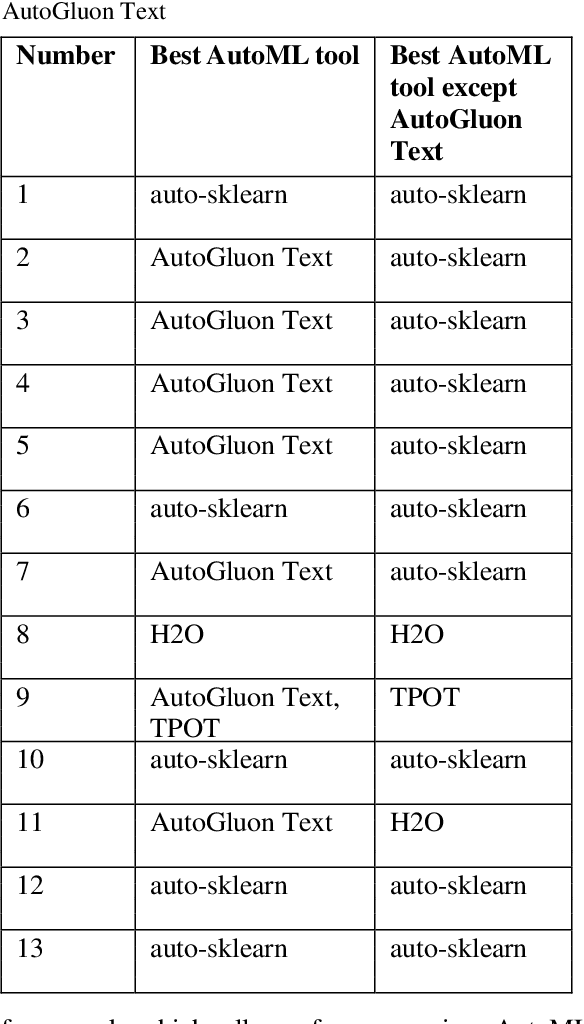

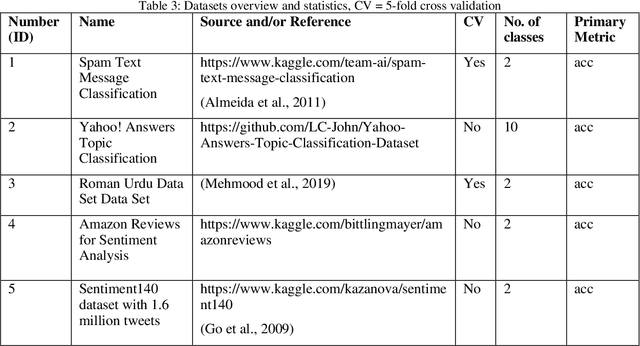
Recently, Automated Machine Learning (AutoML) has registered increasing success with respect to tabular data. However, the question arises whether AutoML can also be applied effectively to text classification tasks. This work compares four AutoML tools on 13 different popular datasets, including Kaggle competitions, and opposes human performance. The results show that the AutoML tools perform better than the machine learning community in 4 out of 13 tasks and that two stand out.
Can AutoML outperform humans? An evaluation on popular OpenML datasets using AutoML Benchmark
Sep 03, 2020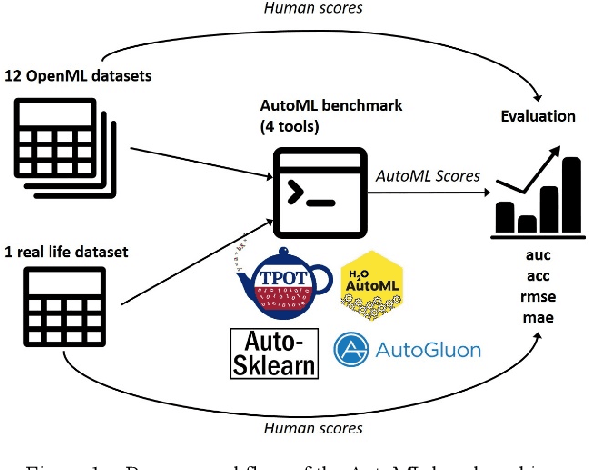
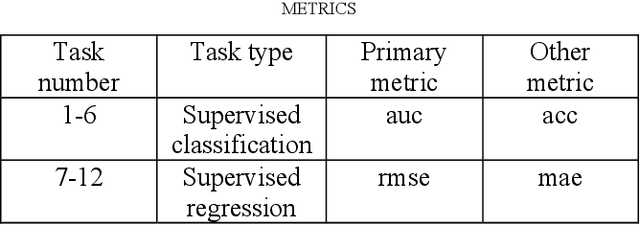
In the last few years, Automated Machine Learning (AutoML) has gained much attention. With that said, the question arises whether AutoML can outperform results achieved by human data scientists. This paper compares four AutoML frameworks on 12 different popular datasets from OpenML; six of them supervised classification tasks and the other six supervised regression ones. Additionally, we consider a real-life dataset from one of our recent projects. The results show that the automated frameworks perform better or equal than the machine learning community in 7 out of 12 OpenML tasks.