 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Deep Learning and Reasoning for Address Detection in Unstructured Text Documents
Paper and Code
Feb 07, 2022
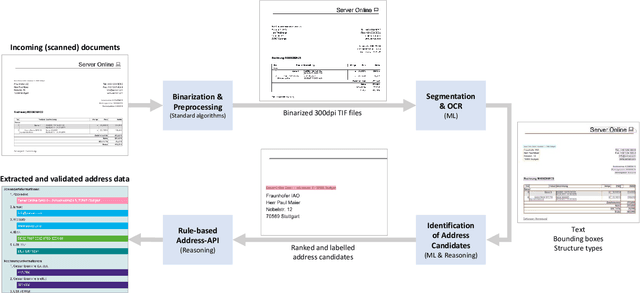

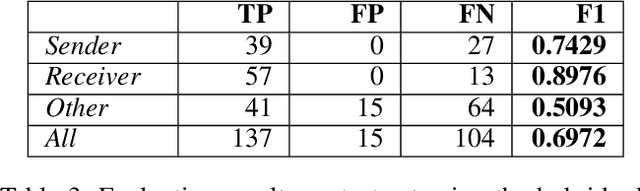
Extracting information from unstructured text documents is a demanding task, since these documents can have a broad variety of different layouts and a non-trivial reading order, like it is the case for multi-column documents or nested tables. Additionally, many business documents are received in paper form, meaning that the textual contents need to be digitized before further analysis. Nonetheless, automatic detection and capturing of crucial document information like the sender address would boost many companies' processing efficiency. In this work we propose a hybrid approach that combines deep learning with reasoning for finding and extracting addresses from unstructured text documents. We use a visual deep learning model to detect the boundaries of possible address regions on the scanned document images and validate these results by analyzing the containing text using domain knowledge represented as a rule based system.