 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding who uses Reddit: Profiling individuals with a self-reported bipolar disorder diagnosis
Apr 23, 2021
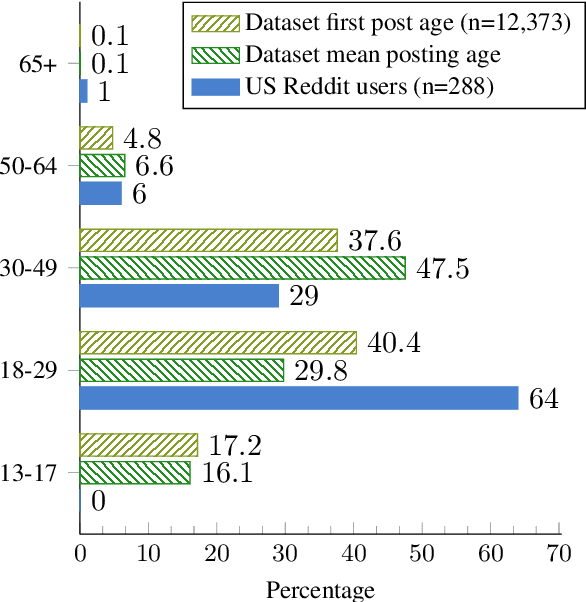
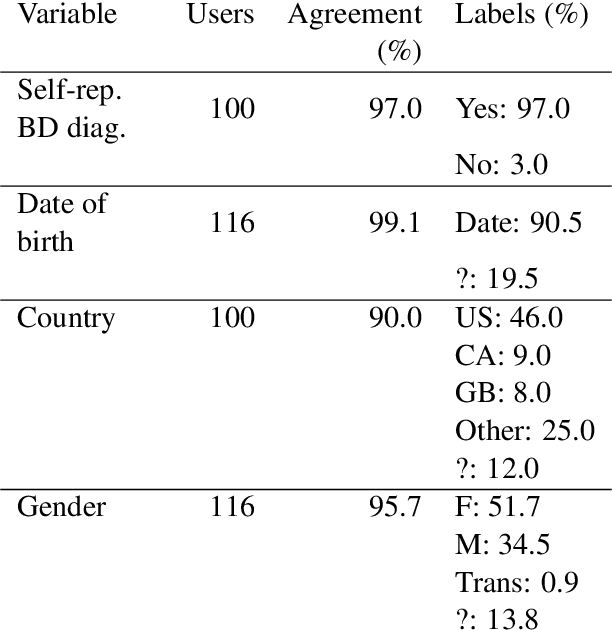
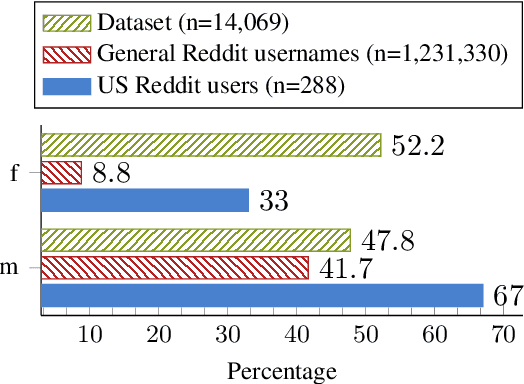
Recently, research on mental health conditions using public online data, including Reddit, has surged in NLP and health research but has not reported user characteristics, which are important to judge generalisability of findings. This paper shows how existing NLP methods can yield information on clinical, demographic, and identity characteristics of almost 20K Reddit users who self-report a bipolar disorder diagnosis. This population consists of slightly more feminine- than masculine-gendered mainly young or middle-aged US-based adults who often report additional mental health diagnoses, which is compared with general Reddit statistics and epidemiological studies. Additionally, this paper carefully evaluates all methods and discusses ethical issues.
A computational linguistic study of personal recovery in bipolar disorder
Jun 03, 2019Mental health research can benefit increasingly fruitfully from computational linguistics methods, given the abundant availability of language data in the internet and advances of computational tools. This interdisciplinary project will collect and analyse social media data of individuals diagnosed with bipolar disorder with regard to their recovery experiences. Personal recovery - living a satisfying and contributing life along symptoms of severe mental health issues - so far has only been investigated qualitatively with structured interviews and quantitatively with standardised questionnaires with mainly English-speaking participants in Western countries. Complementary to this evidence, computational linguistic methods allow us to analyse first-person accounts shared online in large quantities, representing unstructured settings and a more heterogeneous, multilingual population, to draw a more complete picture of the aspects and mechanisms of personal recovery in bipolar disorder.
Sequence-to-Sequence Models for Data-to-Text Natural Language Generation: Word- vs. Character-based Processing and Output Diversity
Oct 11, 2018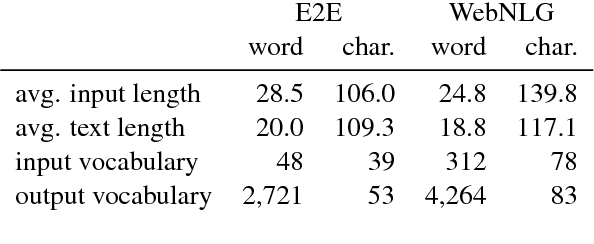
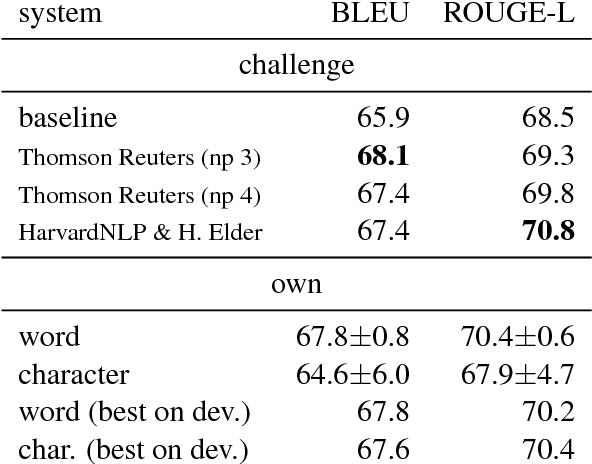
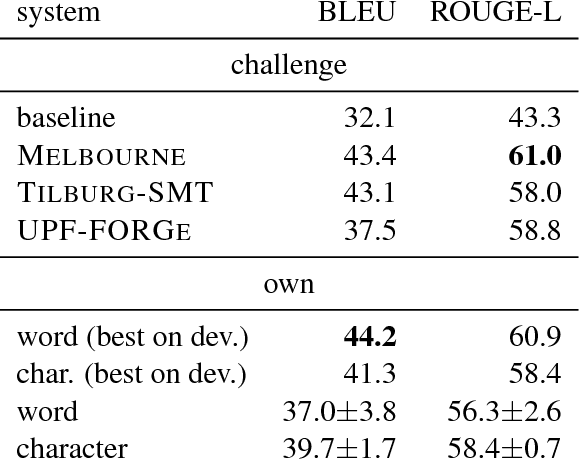
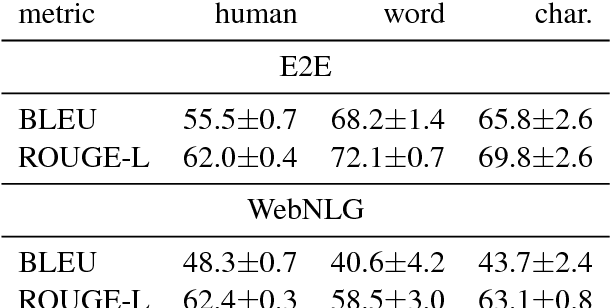
We present a comparison of word-based and character-based sequence-to-sequence models for data-to-text natural language generation, which generate natural language descriptions for structured inputs. On the datasets of two recent generation challenges, our models achieve comparable or better automatic evaluation results than the best challenge submissions. Subsequent detailed statistical and human analyses shed light on the differences between the two input representations and the diversity of the generated texts. In a controlled experiment with synthetic training data generated from templates, we demonstrate the ability of neural models to learn novel combinations of the templates and thereby generalize beyond the linguistic structures they were trained on.
Comparing Attention-based Convolutional and Recurrent Neural Networks: Success and Limitations in Machine Reading Comprehension
Aug 27, 2018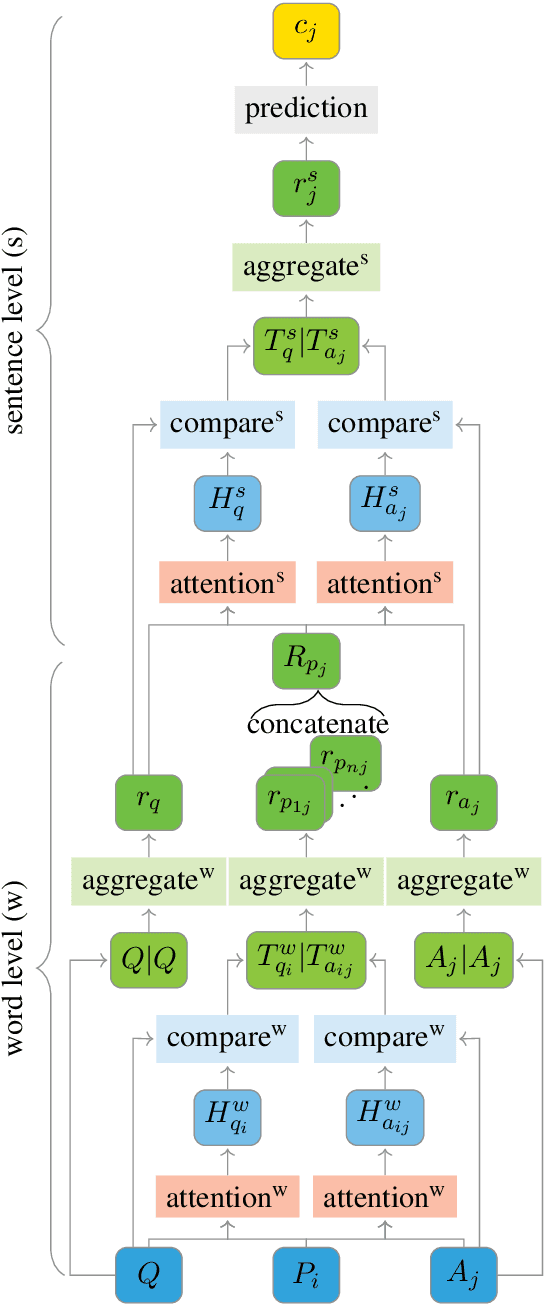
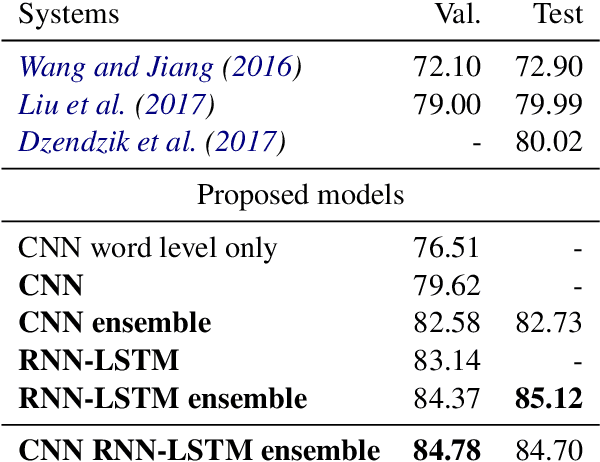

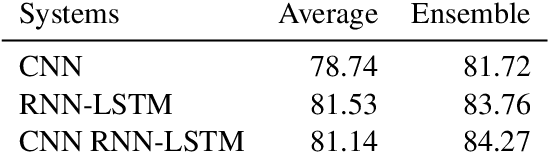
We propose a machine reading comprehension model based on the compare-aggregate framework with two-staged attention that achieves state-of-the-art results on the MovieQA question answering dataset. To investigate the limitations of our model as well as the behavioral difference between convolutional and recurrent neural networks, we generate adversarial examples to confuse the model and compare to human performance. Furthermore, we assess the generalizability of our model by analyzing its differences to human inference,
Encoding Word Confusion Networks with Recurrent Neural Networks for Dialog State Tracking
Aug 09, 2017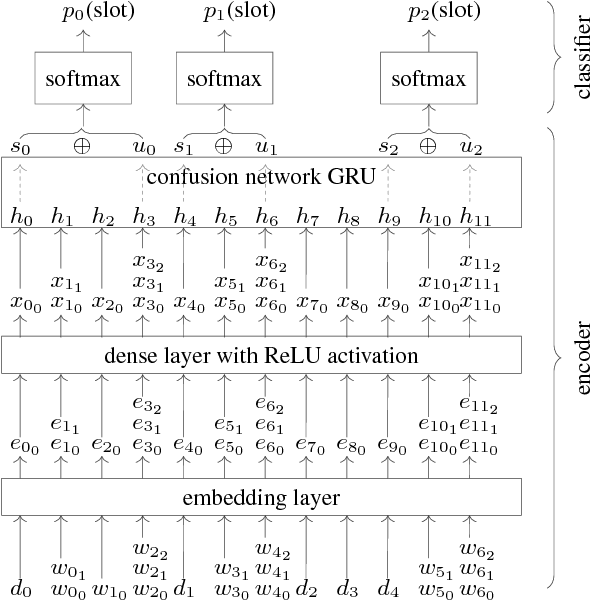

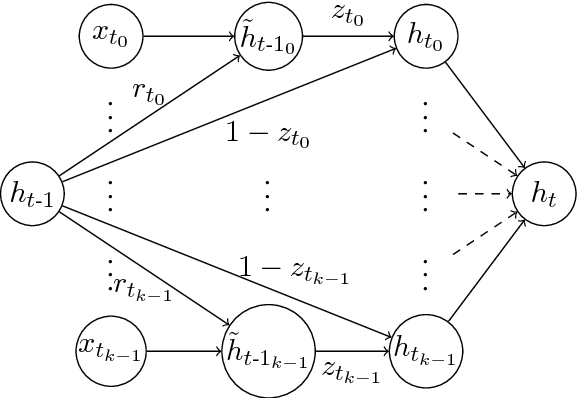

This paper presents our novel method to encode word confusion networks, which can represent a rich hypothesis space of automatic speech recognition systems, via recurrent neural networks. We demonstrate the utility of our approach for the task of dialog state tracking in spoken dialog systems that relies on automatic speech recognition output. Encoding confusion networks outperforms encoding the best hypothesis of the automatic speech recognition in a neural system for dialog state tracking on the well-known second Dialog State Tracking Challenge dataset.