 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Domain-Driven Design: Experience with a Prompting Framework
Mar 27, 2026Domain-driven design (DDD) is a powerful design technique for architecting complex software systems. This paper introduces a prompting framework that automates core DDD activities through structured large language model (LLM) interactions. We decompose DDD into five sequential steps: (1) establishing an ubiquitous language, (2) simulating event storming, (3) identifying bounded contexts, (4) designing aggregates, and (5) mapping to technical architecture. In a case study, we validated the prompting framework against real-world requirements from FTAPI's enterprise platform. While the first steps consistently generate valuable and usable artifacts, later steps show how minor errors or inaccuracies can propagate and accumulate. Overall, the framework excels as a collaborative sparring partner for building actionable documentation, such as glossaries and context maps, but not for full automation. This allows the experts to concentrate their discussion on the critical trade-offs. In our evaluation, Steps 1 to 3 worked well, but the accumulated errors rendered the artifacts generated from Steps 4 and 5 impractical. Our findings show that LLMs can enhance, but not replace, architectural expertise, offering a practical tool to reduce the effort and overhead of DDD while preserving human-centric decision-making.
Adoption of Generative Artificial Intelligence in the German Software Engineering Industry: An Empirical Study
Jan 23, 2026Generative artificial intelligence (GenAI) tools have seen rapid adoption among software developers. While adoption rates in the industry are rising, the underlying factors influencing the effective use of these tools, including the depth of interaction, organizational constraints, and experience-related considerations, have not been thoroughly investigated. This issue is particularly relevant in environments with stringent regulatory requirements, such as Germany, where practitioners must address the GDPR and the EU AI Act while balancing productivity gains with intellectual property considerations. Despite the significant impact of GenAI on software engineering, to the best of our knowledge, no empirical study has systematically examined the adoption dynamics of GenAI tools within the German context. To address this gap, we present a comprehensive mixed-methods study on GenAI adoption among German software engineers. Specifically, we conducted 18 exploratory interviews with practitioners, followed by a developer survey with 109 participants. We analyze patterns of tool adoption, prompting strategies, and organizational factors that influence effectiveness. Our results indicate that experience level moderates the perceived benefits of GenAI tools, and productivity gains are not evenly distributed among developers. Further, organizational size affects both tool selection and the intensity of tool use. Limited awareness of the project context is identified as the most significant barrier. We summarize a set of actionable implications for developers, organizations, and tool vendors seeking to advance artificial intelligence (AI) assisted software development.
Leveraging Large Language Models for Use Case Model Generation from Software Requirements
Nov 13, 2025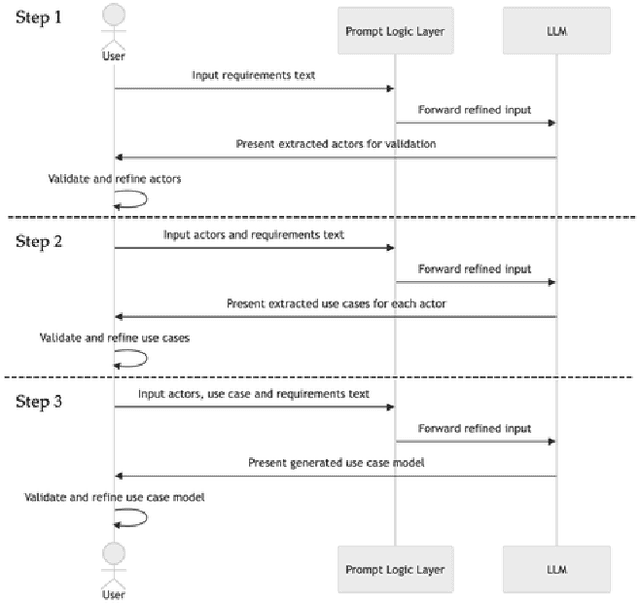


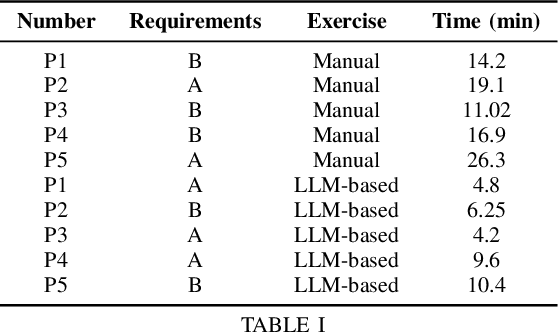
Use case modeling employs user-centered scenarios to outline system requirements. These help to achieve consensus among relevant stakeholders. Because the manual creation of use case models is demanding and time-consuming, it is often skipped in practice. This study explores the potential of Large Language Models (LLMs) to assist in this tedious process. The proposed method integrates an open-weight LLM to systematically extract actors and use cases from software requirements with advanced prompt engineering techniques. The method is evaluated using an exploratory study conducted with five professional software engineers, which compares traditional manual modeling to the proposed LLM-based approach. The results show a substantial acceleration, reducing the modeling time by 60\%. At the same time, the model quality remains on par. Besides improving the modeling efficiency, the participants indicated that the method provided valuable guidance in the process.
iTrace: Click-Based Gaze Visualization on the Apple Vision Pro
Aug 17, 2025



The Apple Vision Pro is equipped with accurate eye-tracking capabilities, yet the privacy restrictions on the device prevent direct access to continuous user gaze data. This study introduces iTrace, a novel application that overcomes these limitations through click-based gaze extraction techniques, including manual methods like a pinch gesture, and automatic approaches utilizing dwell control or a gaming controller. We developed a system with a client-server architecture that captures the gaze coordinates and transforms them into dynamic heatmaps for video and spatial eye tracking. The system can generate individual and averaged heatmaps, enabling analysis of personal and collective attention patterns. To demonstrate its effectiveness and evaluate the usability and performance, a study was conducted with two groups of 10 participants, each testing different clicking methods. The 8BitDo controller achieved higher average data collection rates at 14.22 clicks/s compared to 0.45 clicks/s with dwell control, enabling significantly denser heatmap visualizations. The resulting heatmaps reveal distinct attention patterns, including concentrated focus in lecture videos and broader scanning during problem-solving tasks. By allowing dynamic attention visualization while maintaining a high gaze precision of 91 %, iTrace demonstrates strong potential for a wide range of applications in educational content engagement, environmental design evaluation, marketing analysis, and clinical cognitive assessment. Despite the current gaze data restrictions on the Apple Vision Pro, we encourage developers to use iTrace only in research settings.
How LLMs are Shaping the Future of Virtual Reality
Aug 01, 2025The integration of Large Language Models (LLMs) into Virtual Reality (VR) games marks a paradigm shift in the design of immersive, adaptive, and intelligent digital experiences. This paper presents a comprehensive review of recent research at the intersection of LLMs and VR, examining how these models are transforming narrative generation, non-player character (NPC) interactions, accessibility, personalization, and game mastering. Drawing from an analysis of 62 peer reviewed studies published between 2018 and 2025, we identify key application domains ranging from emotionally intelligent NPCs and procedurally generated storytelling to AI-driven adaptive systems and inclusive gameplay interfaces. We also address the major challenges facing this convergence, including real-time performance constraints, memory limitations, ethical risks, and scalability barriers. Our findings highlight that while LLMs significantly enhance realism, creativity, and user engagement in VR environments, their effective deployment requires robust design strategies that integrate multimodal interaction, hybrid AI architectures, and ethical safeguards. The paper concludes by outlining future research directions in multimodal AI, affective computing, reinforcement learning, and open-source development, aiming to guide the responsible advancement of intelligent and inclusive VR systems.
From Coders to Critics: Empowering Students through Peer Assessment in the Age of AI Copilots
May 28, 2025The rapid adoption of AI powered coding assistants like ChatGPT and other coding copilots is transforming programming education, raising questions about assessment practices, academic integrity, and skill development. As educators seek alternatives to traditional grading methods susceptible to AI enabled plagiarism, structured peer assessment could be a promising strategy. This paper presents an empirical study of a rubric based, anonymized peer review process implemented in a large introductory programming course. Students evaluated each other's final projects (2D game), and their assessments were compared to instructor grades using correlation, mean absolute error, and root mean square error (RMSE). Additionally, reflective surveys from 47 teams captured student perceptions of fairness, grading behavior, and preferences regarding grade aggregation. Results show that peer review can approximate instructor evaluation with moderate accuracy and foster student engagement, evaluative thinking, and interest in providing good feedback to their peers. We discuss these findings for designing scalable, trustworthy peer assessment systems to face the age of AI assisted coding.
Supporting Preschool Emotional Development with AI-Powered Robots
May 24, 2025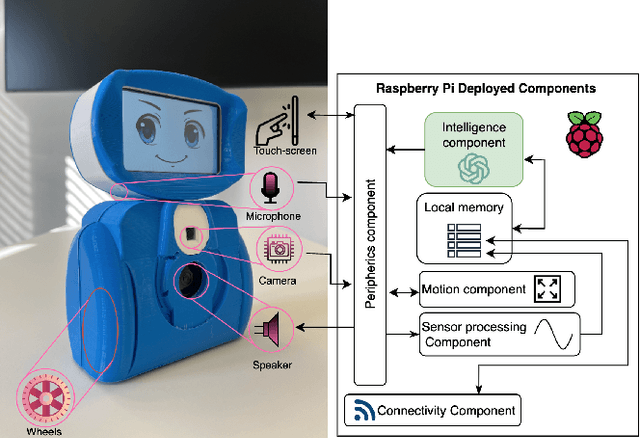

This study evaluates the integration of AI-powered robots in early childhood education, focusing on their impact on emotional self-regulation, engagement, and collaborative skills. A ten-week experimental design involving two groups of children assessed the robot's effectiveness through progress assessments, parental surveys, and teacher feedback. Results demonstrated that early exposure to the robot significantly enhanced emotional recognition, while sustained interaction further improved collaborative and social engagement. Parental and teacher feedback highlighted high acceptance levels, emphasizing the robot's ease of integration and positive influence on classroom dynamics. This research underscores the transformative potential of AI and robotics in education. The findings advocate for the broader adoption of AI-powered interventions, carefully examining equitable access, ethical considerations, and sustainable implementation. This work sets a foundation for exploring long-term impacts and expanding applications of AI in inclusive and impactful educational settings.
ReqBrain: Task-Specific Instruction Tuning of LLMs for AI-Assisted Requirements Generation
May 23, 2025
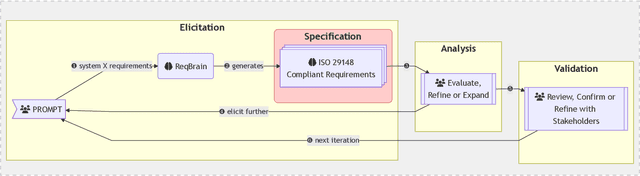


Requirements elicitation and specification remains a labor-intensive, manual process prone to inconsistencies and gaps, presenting a significant challenge in modern software engineering. Emerging studies underscore the potential of employing large language models (LLMs) for automated requirements generation to support requirements elicitation and specification; however, it remains unclear how to implement this effectively. In this work, we introduce ReqBrain, an Al-assisted tool that employs a fine-tuned LLM to generate authentic and adequate software requirements. Software engineers can engage with ReqBrain through chat-based sessions to automatically generate software requirements and categorize them by type. We curated a high-quality dataset of ISO 29148-compliant requirements and fine-tuned five 7B-parameter LLMs to determine the most effective base model for ReqBrain. The top-performing model, Zephyr-7b-beta, achieved 89.30\% Fl using the BERT score and a FRUGAL score of 91.20 in generating authentic and adequate requirements. Human evaluations further confirmed ReqBrain's effectiveness in generating requirements. Our findings suggest that generative Al, when fine-tuned, has the potential to improve requirements elicitation and specification, paving the way for future extensions into areas such as defect identification, test case generation, and agile user story creation.
How Mature is Requirements Engineering for AI-based Systems? A Systematic Mapping Study on Practices, Challenges, and Future Research Directions
Sep 11, 2024
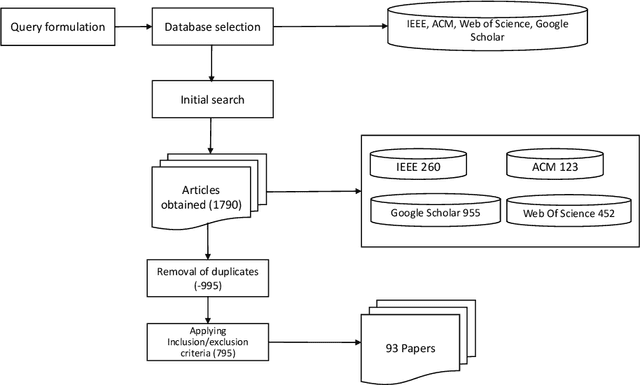


Artificial intelligence (AI) permeates all fields of life, which resulted in new challenges in requirements engineering for artificial intelligence (RE4AI), e.g., the difficulty in specifying and validating requirements for AI or considering new quality requirements due to emerging ethical implications. It is currently unclear if existing RE methods are sufficient or if new ones are needed to address these challenges. Therefore, our goal is to provide a comprehensive overview of RE4AI to researchers and practitioners. What has been achieved so far, i.e., what practices are available, and what research gaps and challenges still need to be addressed? To achieve this, we conducted a systematic mapping study combining query string search and extensive snowballing. The extracted data was aggregated, and results were synthesized using thematic analysis. Our selection process led to the inclusion of 126 primary studies. Existing RE4AI research focuses mainly on requirements analysis and elicitation, with most practices applied in these areas. Furthermore, we identified requirements specification, explainability, and the gap between machine learning engineers and end-users as the most prevalent challenges, along with a few others. Additionally, we proposed seven potential research directions to address these challenges. Practitioners can use our results to identify and select suitable RE methods for working on their AI-based systems, while researchers can build on the identified gaps and research directions to push the field forward.
Interactive Learning in Computer Science Education Supported by a Discord Chatbot
Jul 27, 2024
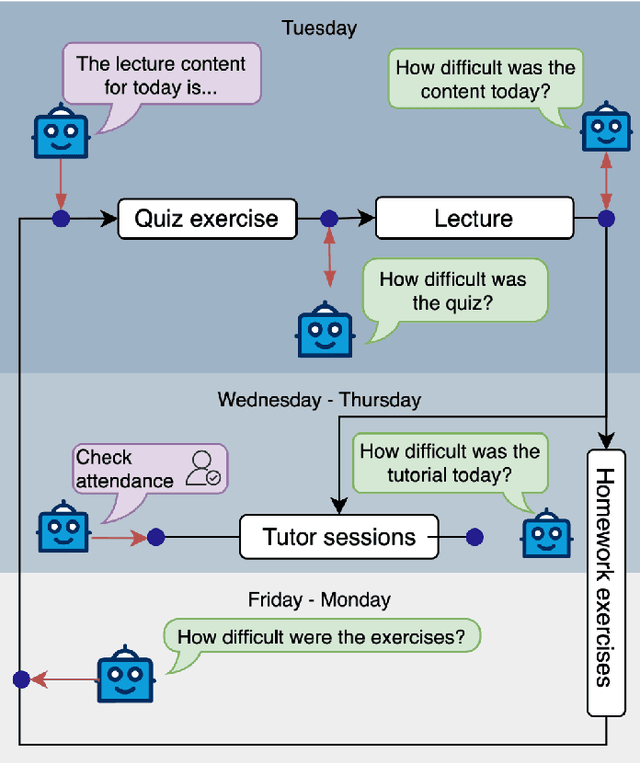


Enhancing interaction and feedback collection in a first-semester computer science course poses a significant challenge due to students' diverse needs and engagement levels. To address this issue, we created and integrated a command-based chatbot on the course communication server on Discord. The DiscordBot enables students to provide feedback on course activities through short surveys, such as exercises, quizzes, and lectures, facilitating stress-free communication with instructors. It also supports attendance tracking and introduces lectures before they start. The research demonstrates the effectiveness of the DiscordBot as a communication tool. The ongoing feedback allowed course instructors to dynamically adjust and improve the difficulty level of upcoming activities and promote discussion in subsequent tutor sessions. The data collected reveal that students can accurately perceive the activities' difficulty and expected results, providing insights not possible through traditional end-of-semester surveys. Students reported that interaction with the DiscordBot was easy and expressed a desire to continue using it in future semesters. This responsive approach ensures the course meets the evolving needs of students, thereby enhancing their overall learning experience.