 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models (LLMs) for Electronic Design Automation (EDA)
Aug 27, 2025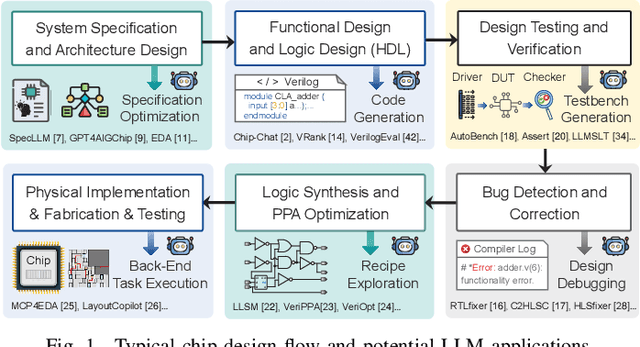
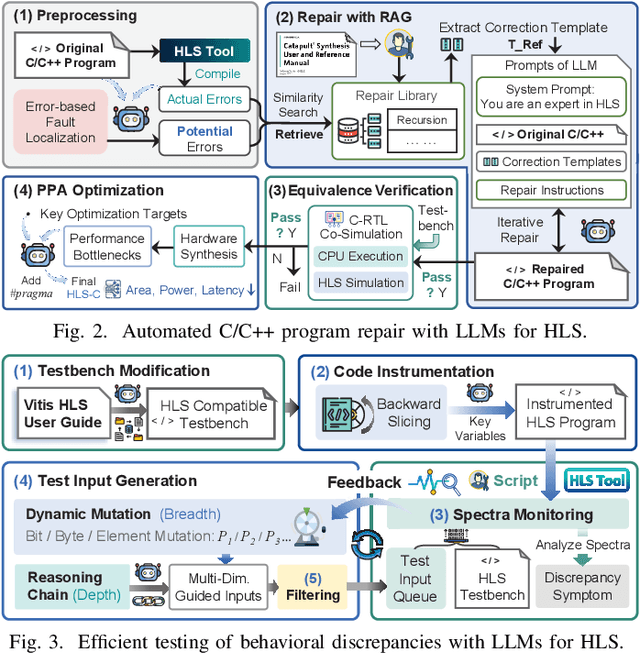
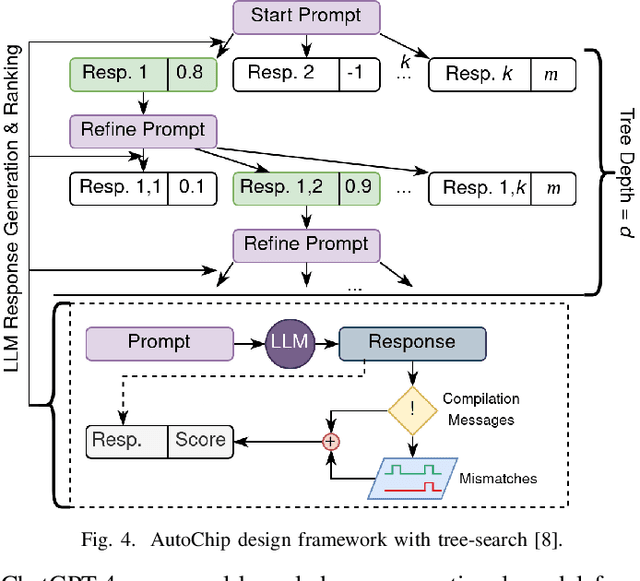
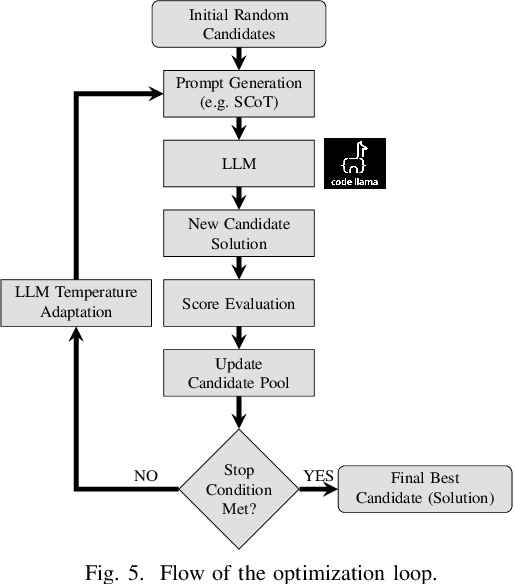
With the growing complexity of modern integrated circuits, hardware engineers are required to devote more effort to the full design-to-manufacturing workflow. This workflow involves numerous iterations, making it both labor-intensive and error-prone. Therefore, there is an urgent demand for more efficient Electronic Design Automation (EDA) solutions to accelerate hardware development. Recently, large language models (LLMs) have shown remarkable advancements in contextual comprehension, logical reasoning, and generative capabilities. Since hardware designs and intermediate scripts can be represented as text, integrating LLM for EDA offers a promising opportunity to simplify and even automate the entire workflow. Accordingly, this paper provides a comprehensive overview of incorporating LLMs into EDA, with emphasis on their capabilities, limitations, and future opportunities. Three case studies, along with their outlook, are introduced to demonstrate the capabilities of LLMs in hardware design, testing, and optimization. Finally, future directions and challenges are highlighted to further explore the potential of LLMs in shaping the next-generation EDA, providing valuable insights for researchers interested in leveraging advanced AI technologies for EDA.
Large Language Models to Generate System-Level Test Programs Targeting Non-functional Properties
Mar 19, 2024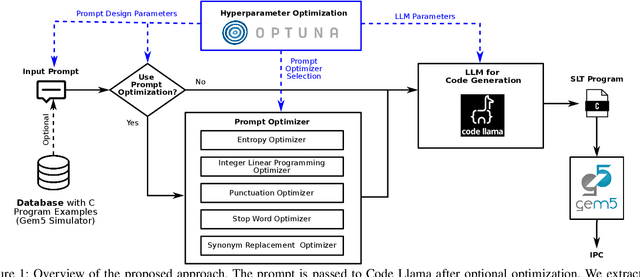
System-Level Test (SLT) has been a part of the test flow for integrated circuits for over a decade and still gains importance. However, no systematic approaches exist for test program generation, especially targeting non-functional properties of the Device under Test (DUT). Currently, test engineers manually compose test suites from off-the-shelf software, approximating the end-user environment of the DUT. This is a challenging and tedious task that does not guarantee sufficient control over non-functional properties. This paper proposes Large Language Models (LLMs) to generate test programs. We take a first glance at how pre-trained LLMs perform in test program generation to optimize non-functional properties of the DUT. Therefore, we write a prompt to generate C code snippets that maximize the instructions per cycle of a super-scalar, out-of-order architecture in simulation. Additionally, we apply prompt and hyperparameter optimization to achieve the best possible results without further training.
Self-Learning Tuning for Post-Silicon Validation
Nov 18, 2021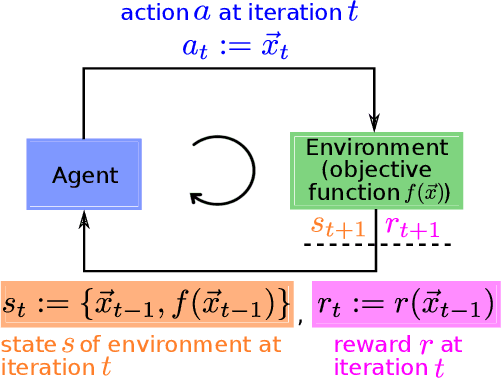
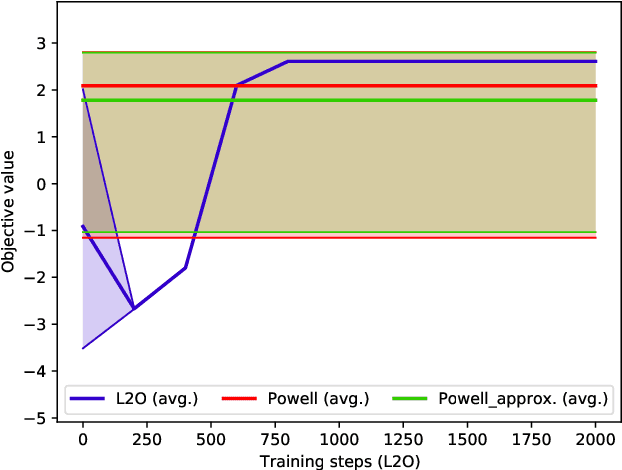
Increasing complexity of modern chips makes design validation more difficult. Existing approaches are not able anymore to cope with the complexity of tasks such as robust performance tuning in post-silicon validation. Therefore, we propose a novel approach based on learn-to-optimize and reinforcement learning in order to solve complex and mixed-type tuning tasks in a efficient and robust way.
ORSA: Outlier Robust Stacked Aggregation for Best- and Worst-Case Approximations of Ensemble Systems\
Nov 17, 2021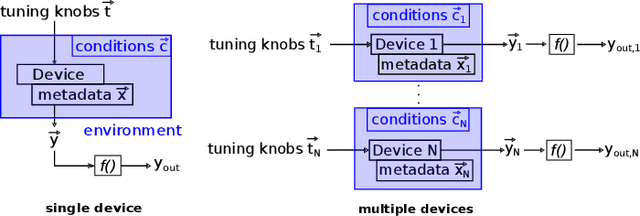
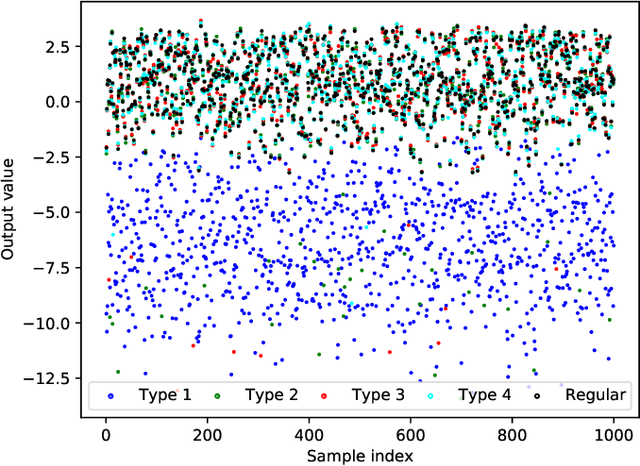
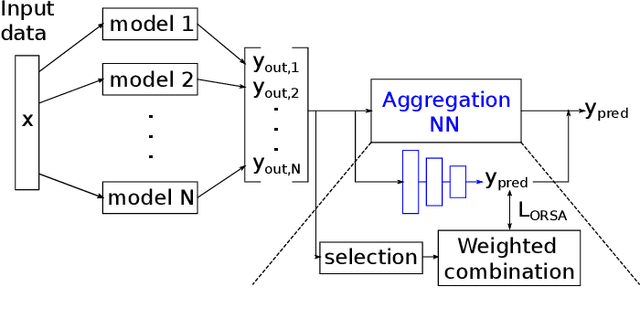
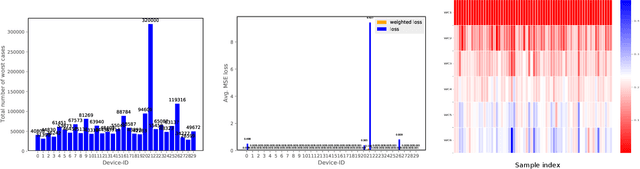
In recent years, the usage of ensemble learning in applications has grown significantly due to increasing computational power allowing the training of large ensembles in reasonable time frames. Many applications, e.g., malware detection, face recognition, or financial decision-making, use a finite set of learning algorithms and do aggregate them in a way that a better predictive performance is obtained than any other of the individual learning algorithms. In the field of Post-Silicon Validation for semiconductor devices (PSV), data sets are typically provided that consist of various devices like, e.g., chips of different manufacturing lines. In PSV, the task is to approximate the underlying function of the data with multiple learning algorithms, each trained on a device-specific subset, instead of improving the performance of arbitrary classifiers on the entire data set. Furthermore, the expectation is that an unknown number of subsets describe functions showing very different characteristics. Corresponding ensemble members, which are called outliers, can heavily influence the approximation. Our method aims to find a suitable approximation that is robust to outliers and represents the best or worst case in a way that will apply to as many types as possible. A 'soft-max' or 'soft-min' function is used in place of a maximum or minimum operator. A Neural Network (NN) is trained to learn this 'soft-function' in a two-stage process. First, we select a subset of ensemble members that is representative of the best or worst case. Second, we combine these members and define a weighting that uses the properties of the Local Outlier Factor (LOF) to increase the influence of non-outliers and to decrease outliers. The weighting ensures robustness to outliers and makes sure that approximations are suitable for most types.