 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Feature Selection Using a Novel Complementary Feature Mask
Sep 25, 2022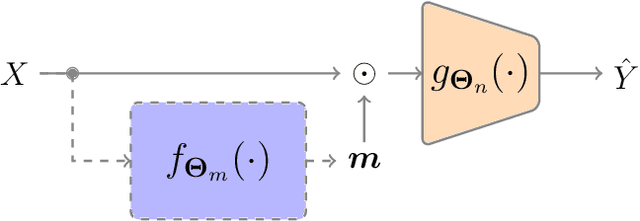
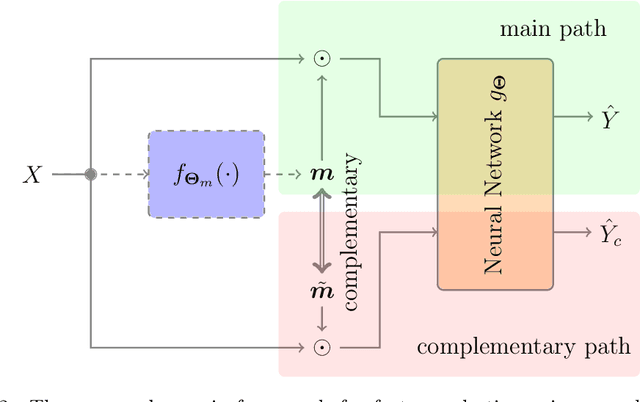
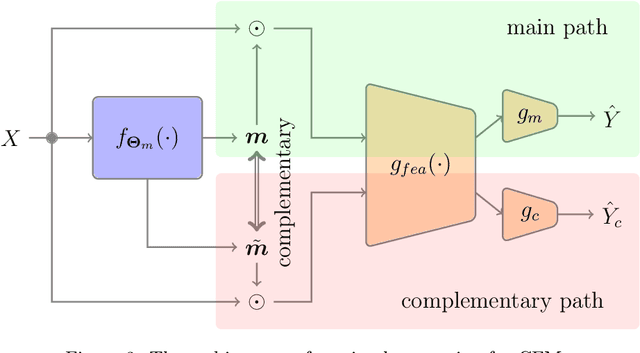
Feature selection has drawn much attention over the last decades in machine learning because it can reduce data dimensionality while maintaining the original physical meaning of features, which enables better interpretability than feature extraction. However, most existing feature selection approaches, especially deep-learning-based, often focus on the features with great importance scores only but neglect those with less importance scores during training as well as the order of important candidate features. This can be risky since some important and relevant features might be unfortunately ignored during training, leading to suboptimal solutions or misleading selections. In our work, we deal with feature selection by exploiting the features with less importance scores and propose a feature selection framework based on a novel complementary feature mask. Our method is generic and can be easily integrated into existing deep-learning-based feature selection approaches to improve their performance as well. Experiments have been conducted on benchmarking datasets and shown that the proposed method can select more representative and informative features than the state of the art.
A Deep-Learning-Aided Pipeline for Efficient Post-Silicon Tuning
Jul 01, 2022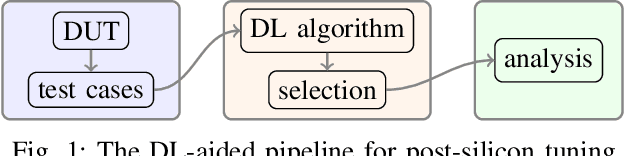
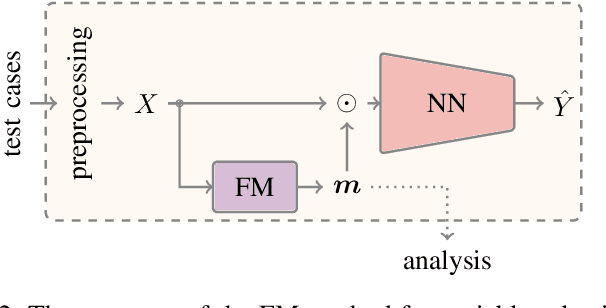
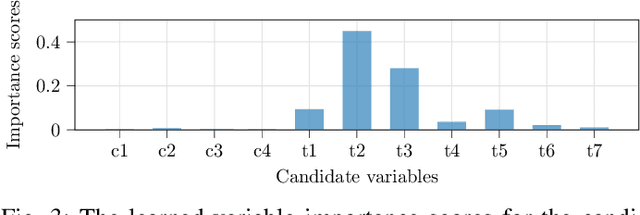
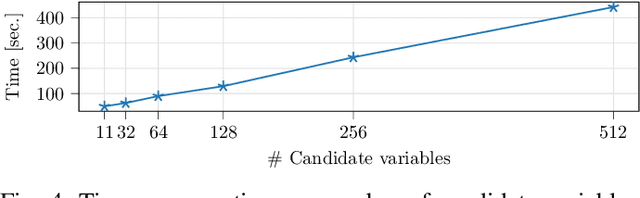
In post-silicon validation, tuning is to find the values for the tuning knobs, potentially as a function of process parameters and/or known operating conditions. In this sense, an more efficient tuning requires identifying the most critical tuning knobs and process parameters in terms of a given figure-of-merit for a Device Under Test (DUT). This is often manually conducted by experienced experts. However, with increasingly complex chips, manual inspection on a large amount of raw variables has become more challenging. In this work, we leverage neural networks to efficiently select the most relevant variables and present a corresponding deep-learning-aided pipeline for efficient tuning.
Self-Learning Tuning for Post-Silicon Validation
Nov 18, 2021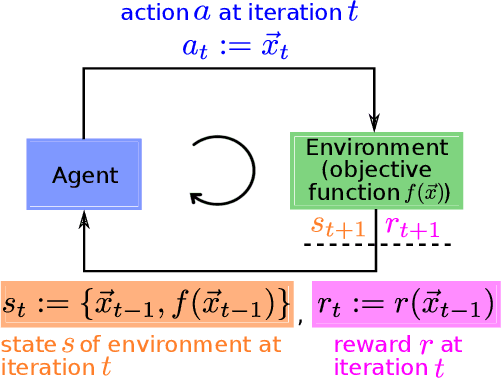
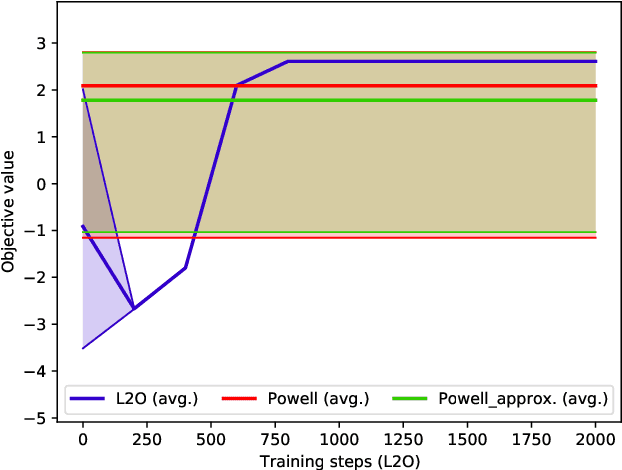
Increasing complexity of modern chips makes design validation more difficult. Existing approaches are not able anymore to cope with the complexity of tasks such as robust performance tuning in post-silicon validation. Therefore, we propose a novel approach based on learn-to-optimize and reinforcement learning in order to solve complex and mixed-type tuning tasks in a efficient and robust way.
ORSA: Outlier Robust Stacked Aggregation for Best- and Worst-Case Approximations of Ensemble Systems\
Nov 17, 2021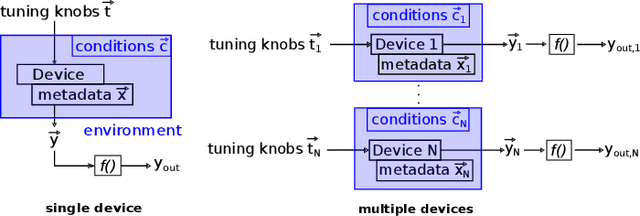
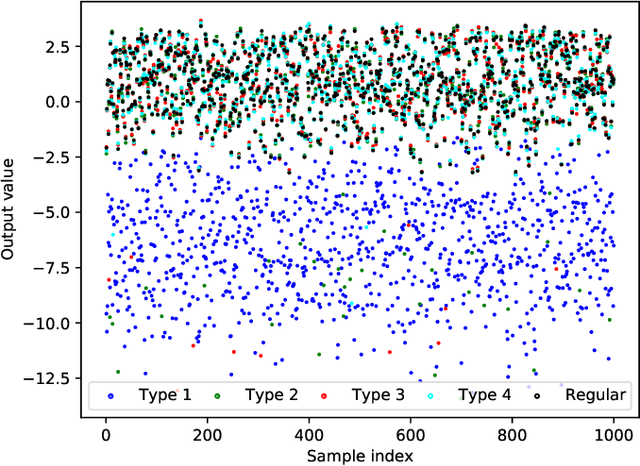
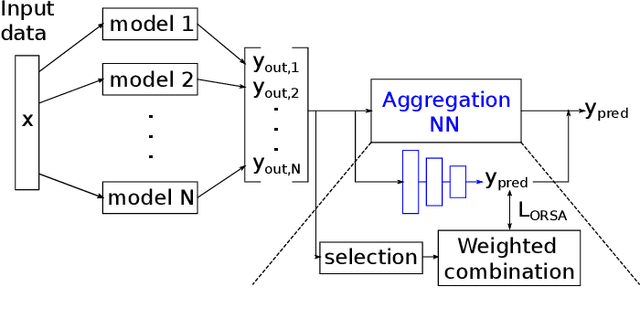
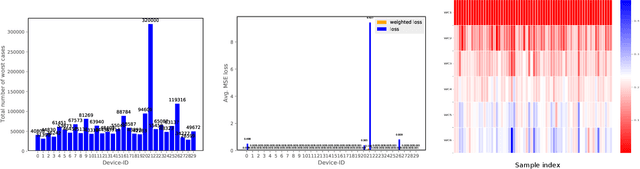
In recent years, the usage of ensemble learning in applications has grown significantly due to increasing computational power allowing the training of large ensembles in reasonable time frames. Many applications, e.g., malware detection, face recognition, or financial decision-making, use a finite set of learning algorithms and do aggregate them in a way that a better predictive performance is obtained than any other of the individual learning algorithms. In the field of Post-Silicon Validation for semiconductor devices (PSV), data sets are typically provided that consist of various devices like, e.g., chips of different manufacturing lines. In PSV, the task is to approximate the underlying function of the data with multiple learning algorithms, each trained on a device-specific subset, instead of improving the performance of arbitrary classifiers on the entire data set. Furthermore, the expectation is that an unknown number of subsets describe functions showing very different characteristics. Corresponding ensemble members, which are called outliers, can heavily influence the approximation. Our method aims to find a suitable approximation that is robust to outliers and represents the best or worst case in a way that will apply to as many types as possible. A 'soft-max' or 'soft-min' function is used in place of a maximum or minimum operator. A Neural Network (NN) is trained to learn this 'soft-function' in a two-stage process. First, we select a subset of ensemble members that is representative of the best or worst case. Second, we combine these members and define a weighting that uses the properties of the Local Outlier Factor (LOF) to increase the influence of non-outliers and to decrease outliers. The weighting ensures robustness to outliers and makes sure that approximations are suitable for most types.