 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperts in the Loop: Conditional Variable Selection for Accelerating Post-Silicon Analysis Based on Deep Learning
Sep 30, 2022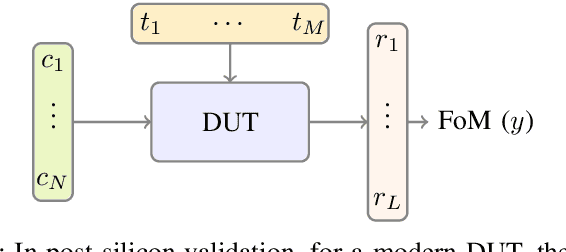
Post-silicon validation is one of the most critical processes in modern semiconductor manufacturing. Specifically, correct and deep understanding in test cases of manufactured devices is key to enable post-silicon tuning and debugging. This analysis is typically performed by experienced human experts. However, with the fast development in semiconductor industry, test cases can contain hundreds of variables. The resulting high-dimensionality poses enormous challenges to experts. Thereby, some recent prior works have introduced data-driven variable selection algorithms to tackle these problems and achieved notable success. Nevertheless, for these methods, experts are not involved in training and inference phases, which may lead to bias and inaccuracy due to the lack of prior knowledge. Hence, this work for the first time aims to design a novel conditional variable selection approach while keeping experts in the loop. In this way, we expect that our algorithm can be more efficiently and effectively trained to identify the most critical variables under certain expert knowledge. Extensive experiments on both synthetic and real-world datasets from industry have been conducted and shown the effectiveness of our method.
Deep Feature Selection Using a Novel Complementary Feature Mask
Sep 25, 2022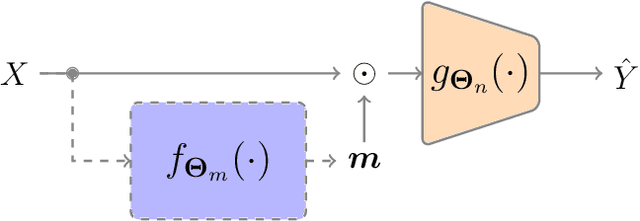
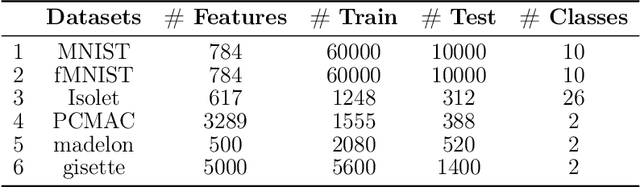
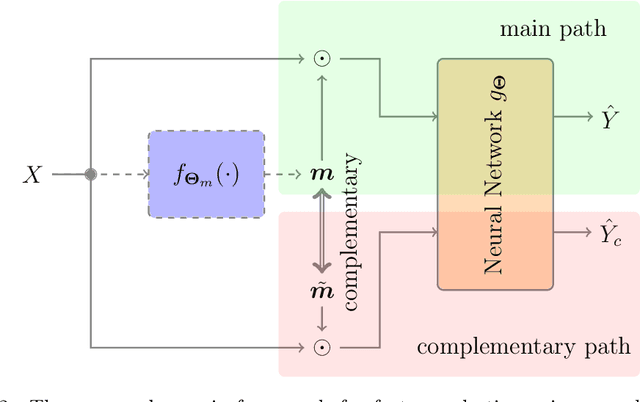
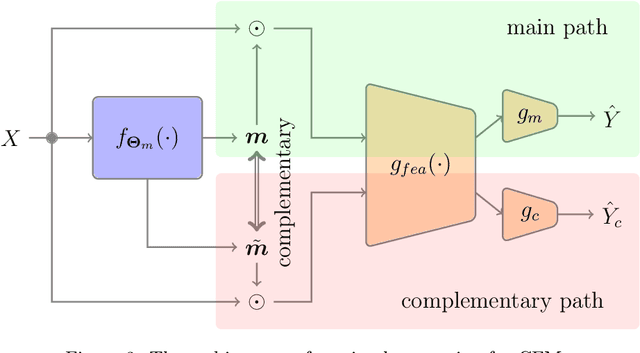
Feature selection has drawn much attention over the last decades in machine learning because it can reduce data dimensionality while maintaining the original physical meaning of features, which enables better interpretability than feature extraction. However, most existing feature selection approaches, especially deep-learning-based, often focus on the features with great importance scores only but neglect those with less importance scores during training as well as the order of important candidate features. This can be risky since some important and relevant features might be unfortunately ignored during training, leading to suboptimal solutions or misleading selections. In our work, we deal with feature selection by exploiting the features with less importance scores and propose a feature selection framework based on a novel complementary feature mask. Our method is generic and can be easily integrated into existing deep-learning-based feature selection approaches to improve their performance as well. Experiments have been conducted on benchmarking datasets and shown that the proposed method can select more representative and informative features than the state of the art.
A Deep-Learning-Aided Pipeline for Efficient Post-Silicon Tuning
Jul 01, 2022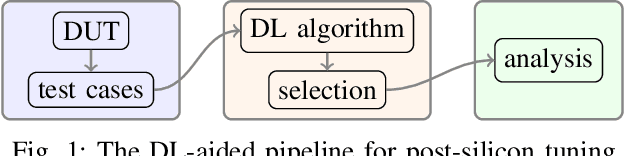
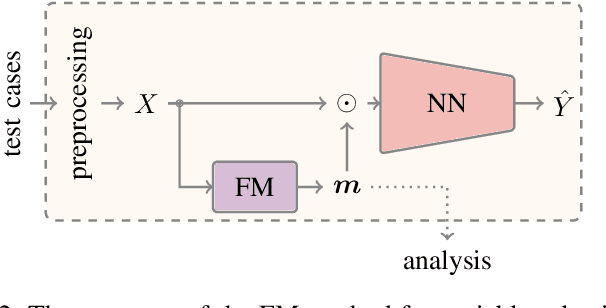
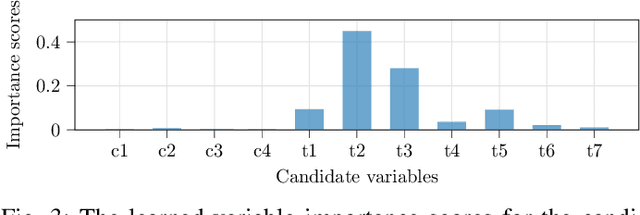
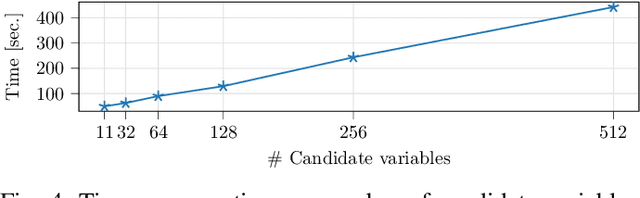
In post-silicon validation, tuning is to find the values for the tuning knobs, potentially as a function of process parameters and/or known operating conditions. In this sense, an more efficient tuning requires identifying the most critical tuning knobs and process parameters in terms of a given figure-of-merit for a Device Under Test (DUT). This is often manually conducted by experienced experts. However, with increasingly complex chips, manual inspection on a large amount of raw variables has become more challenging. In this work, we leverage neural networks to efficiently select the most relevant variables and present a corresponding deep-learning-aided pipeline for efficient tuning.
Conditional Variable Selection for Intelligent Test
Jul 01, 2022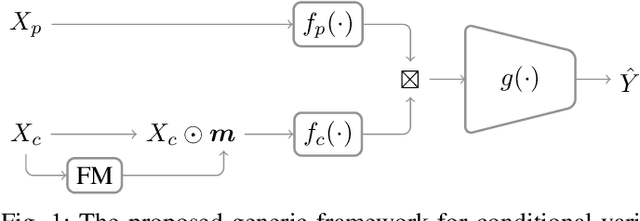
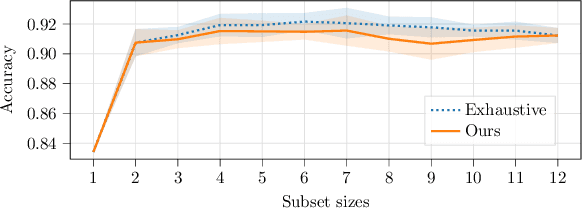
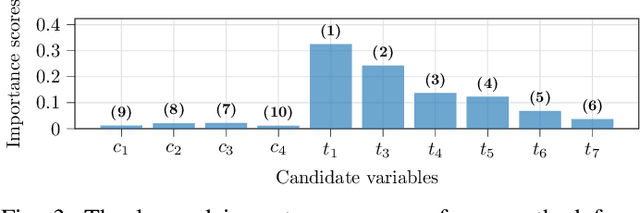
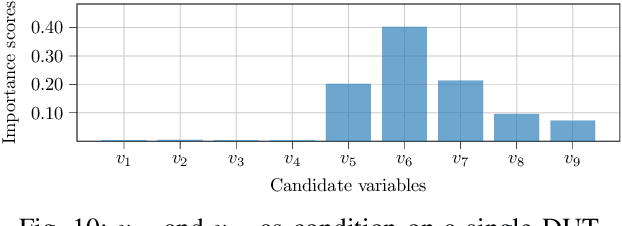
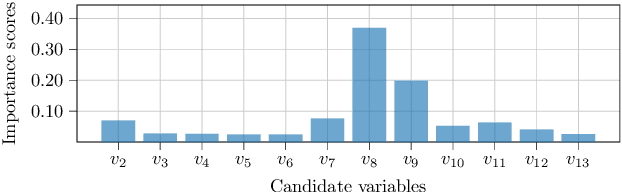
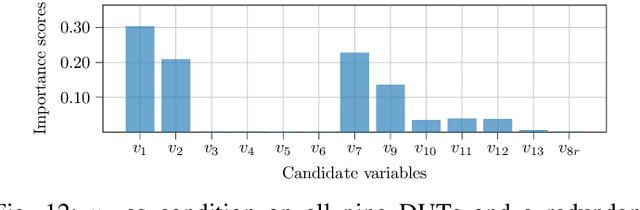
Intelligent test requires efficient and effective analysis of high-dimensional data in a large scale. Traditionally, the analysis is often conducted by human experts, but it is not scalable in the era of big data. To tackle this challenge, variable selection has been recently introduced to intelligent test. However, in practice, we encounter scenarios where certain variables (e.g. some specific processing conditions for a device under test) must be maintained after variable selection. We call this conditional variable selection, which has not been well investigated for embedded or deep-learning-based variable selection methods. In this paper, we discuss a novel conditional variable selection framework that can select the most important candidate variables given a set of preselected variables.
Anomaly Detection Based on Selection and Weighting in Latent Space
Mar 08, 2021
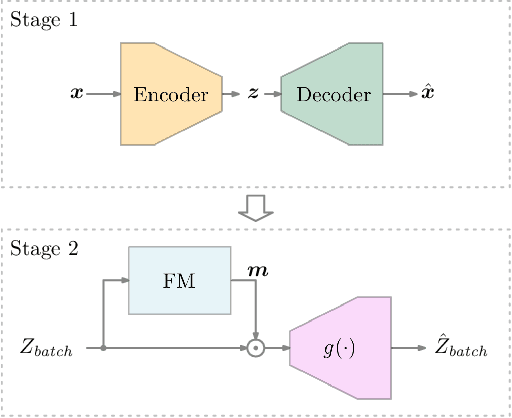


With the high requirements of automation in the era of Industry 4.0, anomaly detection plays an increasingly important role in higher safety and reliability in the production and manufacturing industry. Recently, autoencoders have been widely used as a backend algorithm for anomaly detection. Different techniques have been developed to improve the anomaly detection performance of autoencoders. Nonetheless, little attention has been paid to the latent representations learned by autoencoders. In this paper, we propose a novel selection-and-weighting-based anomaly detection framework called SWAD. In particular, the learned latent representations are individually selected and weighted. Experiments on both benchmark and real-world datasets have shown the effectiveness and superiority of SWAD. On the benchmark datasets, the SWAD framework has reached comparable or even better performance than the state-of-the-art approaches.
Feature Selection Using Batch-Wise Attenuation and Feature Mask Normalization
Oct 26, 2020
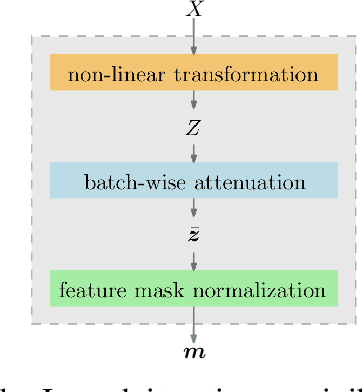

Feature selection is generally used as one of the most important pre-processing techniques in machine learning, as it helps to reduce the dimensionality of data and assists researchers and practitioners in understanding data. Thereby, better performance and reduced computational consumption, memory complexity and even data amount can be expected by utilizing feature selection. However, only few studies leverage the power of deep neural networks to solve the problem of feature selection. In this paper, we propose a feature mask module (FM-module) for feature selection based on a novel batch-wise attenuation and feature mask normalization. The proposed method is almost free from hyperparameters and can be easily integrated into common neural networks as an embedded feature selection method. Experiments on popular image, text and speech datasets have been shown that our approach is easy to use and has superior performance in comparison with other state-of-the-art deep learning based feature selection methods.
Deep One-Class Classification Using Intra-Class Splitting
Mar 12, 2019
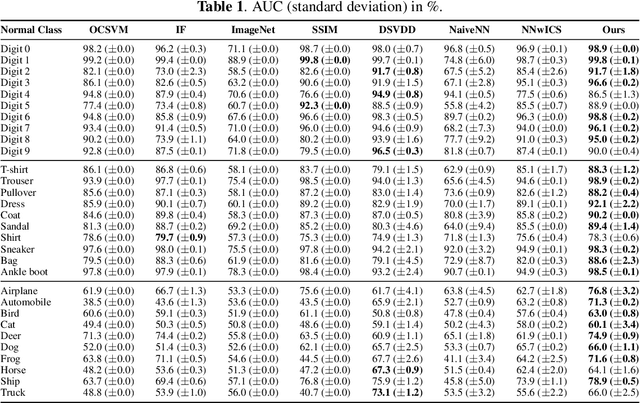
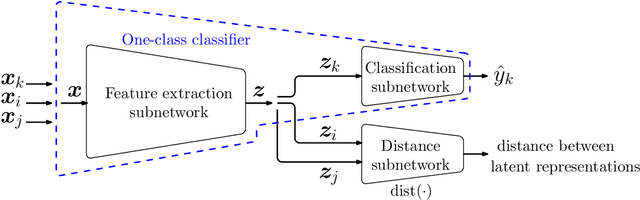
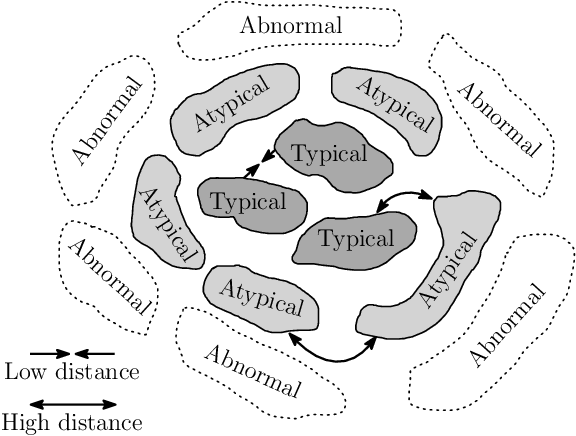
This paper introduces a generic method which enables to use conventional deep neural networks as end-to-end one-class classifiers. The method is based on splitting given data from one class into two subsets. In one-class classification, only samples of one normal class are available for training. During inference, a closed and tight decision boundary around the training samples is sought which conventional binary or multi-class neural networks are not able to provide. By splitting data into typical and atypical normal subsets, the proposed method can use a binary loss and defines an auxiliary subnetwork for distance constraints in the latent space. Various experiments on three well-known image datasets showed the effectiveness of the proposed method which outperformed seven baselines and had a better or comparable performance to the state-of-the-art.
Open-Set Recognition Using Intra-Class Splitting
Mar 12, 2019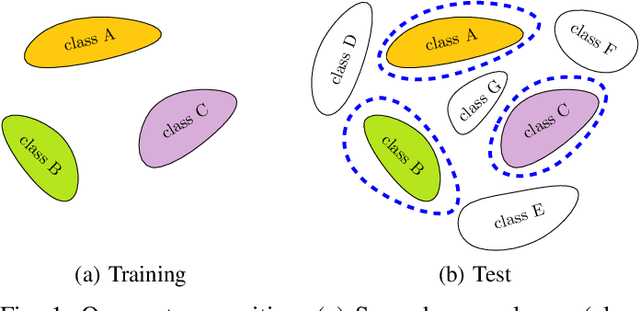
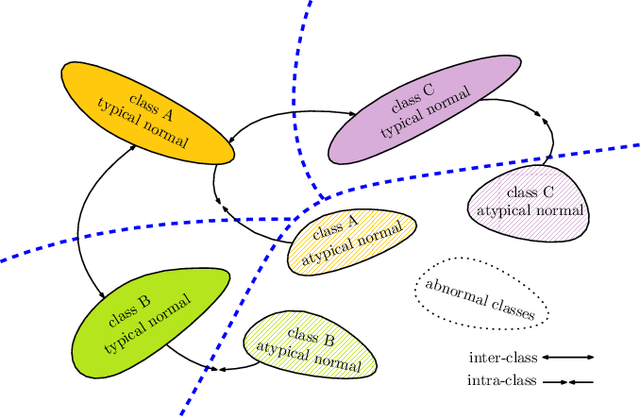
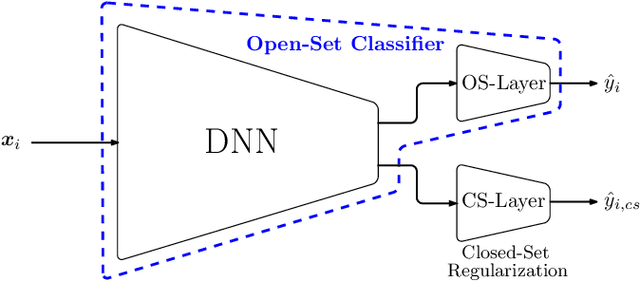

This paper proposes a method to use deep neural networks as end-to-end open-set classifiers. It is based on intra-class data splitting. In open-set recognition, only samples from a limited number of known classes are available for training. During inference, an open-set classifier must reject samples from unknown classes while correctly classifying samples from known classes. The proposed method splits given data into typical and atypical normal subsets by using a closed-set classifier. This enables to model the abnormal classes by atypical normal samples. Accordingly, the open-set recognition problem is reformulated into a traditional classification problem. In addition, a closed-set regularization is proposed to guarantee a high closed-set classification performance. Intensive experiments on five well-known image datasets showed the effectiveness of the proposed method which outperformed the baselines and achieved a distinct improvement over the state-of-the-art methods.
One-Class Feature Learning Using Intra-Class Splitting
Dec 20, 2018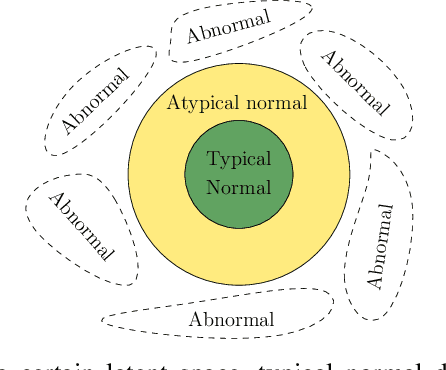

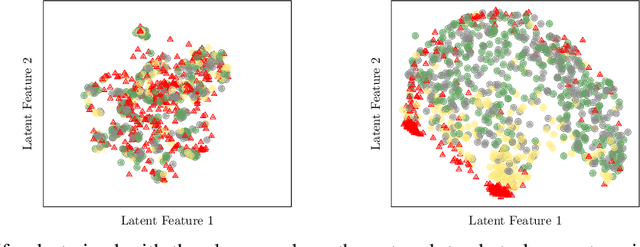
This paper proposes a novel generic one-class feature learning method which is based on intra-class splitting. In one-class classification, feature learning is challenging, because only samples of one class are available during training. Hence, state-of-the-art methods require reference multi-class datasets to pretrain feature extractors. In contrast, the proposed method realizes feature learning by splitting the given normal class into typical and atypical normal samples. By introducing closeness loss and dispersion loss, an intra-class joint training procedure between the two subsets after splitting enables the extraction of valuable features for one-class classification. Various experiments on three well-known image classification datasets demonstrate the effectiveness of our method which outperformed other baseline models in 25 of 30 experiments.