 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Tuning for Parameter-efficient Medical Image Segmentation
Nov 16, 2022Neural networks pre-trained on a self-supervision scheme have become the standard when operating in data rich environments with scarce annotations. As such, fine-tuning a model to a downstream task in a parameter-efficient but effective way, e.g. for a new set of classes in the case of semantic segmentation, is of increasing importance. In this work, we propose and investigate several contributions to achieve a parameter-efficient but effective adaptation for semantic segmentation on two medical imaging datasets. Relying on the recently popularized prompt tuning approach, we provide a prompt-able UNet (PUNet) architecture, that is frozen after pre-training, but adaptable throughout the network by class-dependent learnable prompt tokens. We pre-train this architecture with a dedicated dense self-supervision scheme based on assignments to online generated prototypes (contrastive prototype assignment, CPA) of a student teacher combination alongside a concurrent segmentation loss on a subset of classes. We demonstrate that the resulting neural network model is able to attenuate the gap between fully fine-tuned and parameter-efficiently adapted models on CT imaging datasets. As such, the difference between fully fine-tuned and prompt-tuned variants amounts to only 3.83 pp for the TCIA/BTCV dataset and 2.67 pp for the CT-ORG dataset in the mean Dice Similarity Coefficient (DSC, in %) while only prompt tokens, corresponding to 0.85% of the pre-trained backbone model with 6.8M frozen parameters, are adjusted. The code for this work is available on https://github.com/marcdcfischer/PUNet .
TTAPS: Test-Time Adaption by Aligning Prototypes using Self-Supervision
May 18, 2022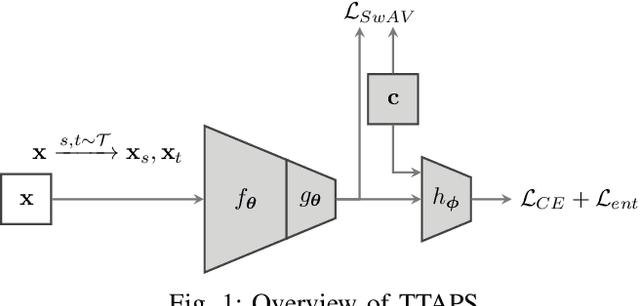
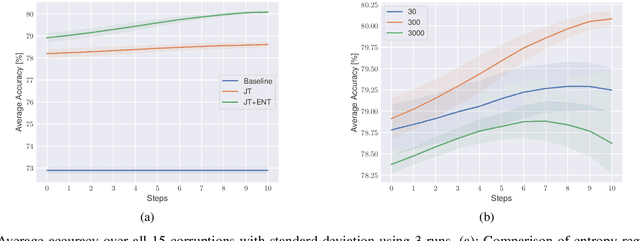
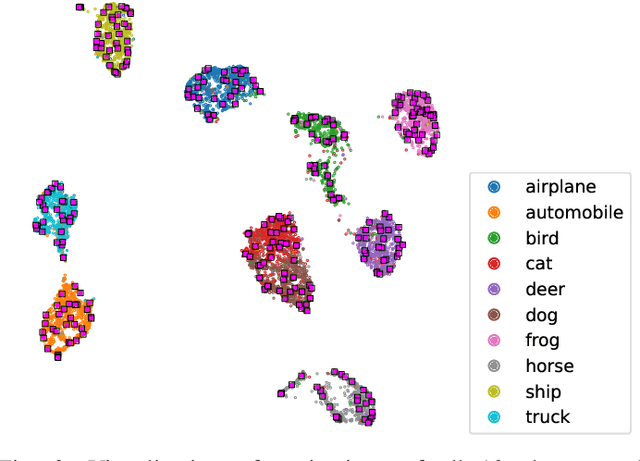

Nowadays, deep neural networks outperform humans in many tasks. However, if the input distribution drifts away from the one used in training, their performance drops significantly. Recently published research has shown that adapting the model parameters to the test sample can mitigate this performance degradation. In this paper, we therefore propose a novel modification of the self-supervised training algorithm SwAV that adds the ability to adapt to single test samples. Using the provided prototypes of SwAV and our derived test-time loss, we align the representation of unseen test samples with the self-supervised learned prototypes. We show the success of our method on the common benchmark dataset CIFAR10-C.
Estimation of Bivariate Structural Causal Models by Variational Gaussian Process Regression Under Likelihoods Parametrised by Normalising Flows
Sep 06, 2021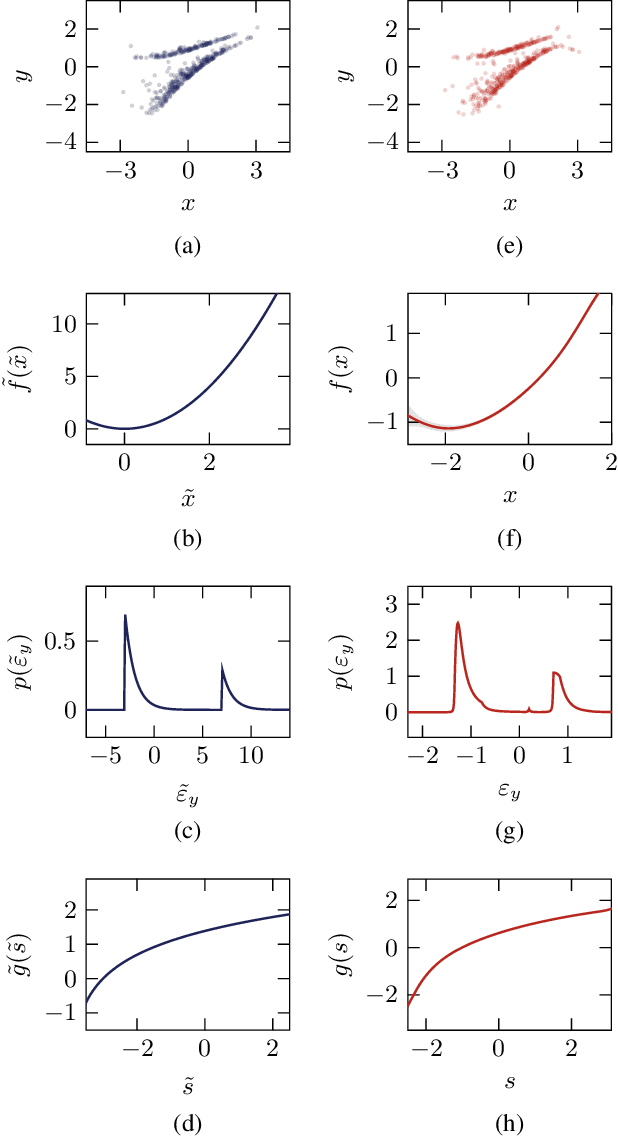
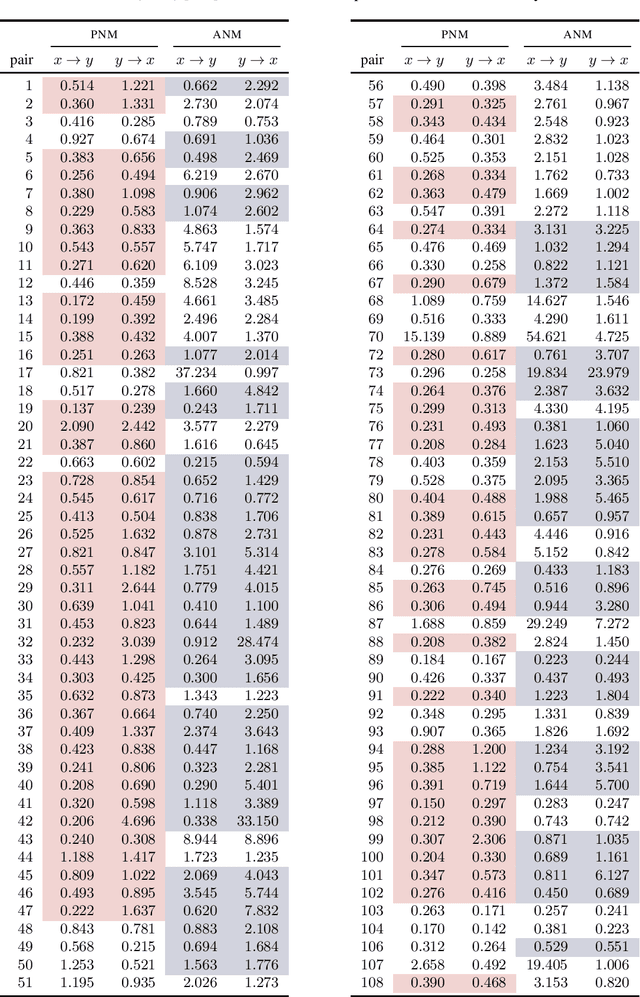
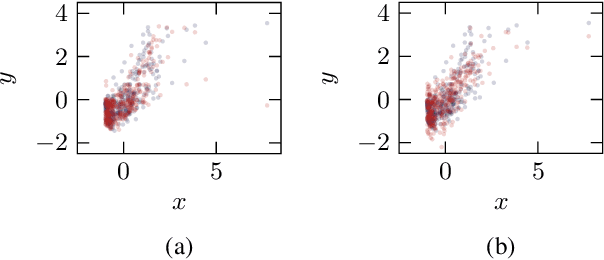
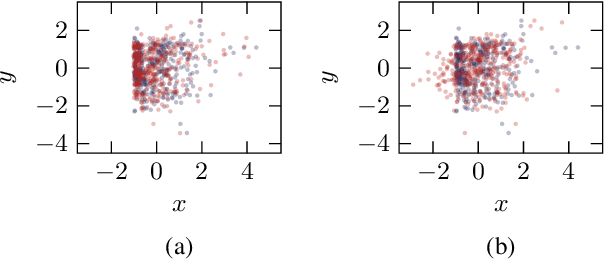
One major drawback of state-of-the-art artificial intelligence is its lack of explainability. One approach to solve the problem is taking causality into account. Causal mechanisms can be described by structural causal models. In this work, we propose a method for estimating bivariate structural causal models using a combination of normalising flows applied to density estimation and variational Gaussian process regression for post-nonlinear models. It facilitates causal discovery, i.e. distinguishing cause and effect, by either the independence of cause and residual or a likelihood ratio test. Our method which estimates post-nonlinear models can better explain a variety of real-world cause-effect pairs than a simple additive noise model. Though it remains difficult to exploit this benefit regarding all pairs from the T\"ubingen benchmark database, we demonstrate that combining the additive noise model approach with our method significantly enhances causal discovery.
Contrastive Learning and Self-Training for Unsupervised Domain Adaptation in Semantic Segmentation
May 05, 2021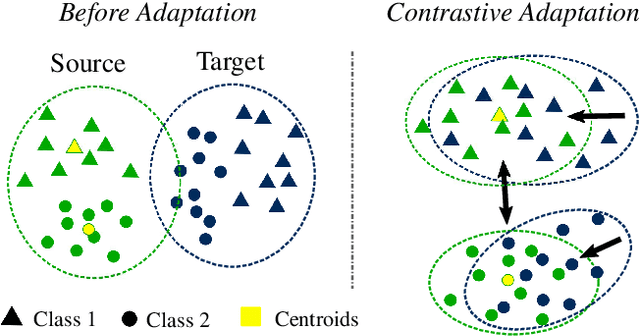
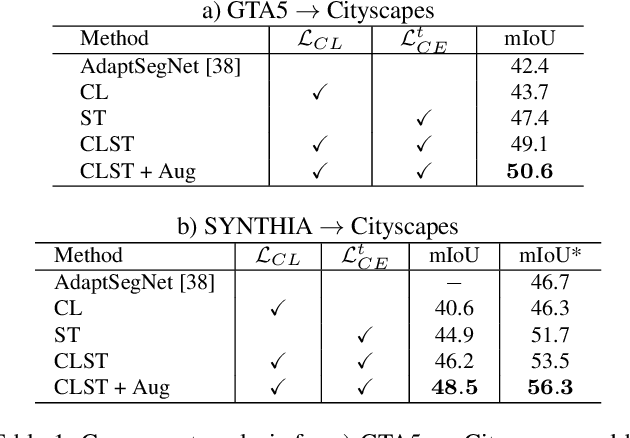
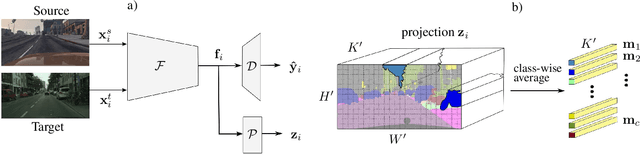
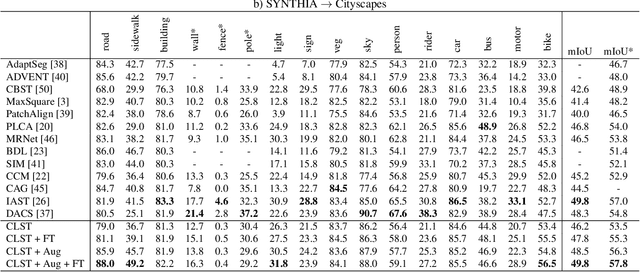
Deep convolutional neural networks have considerably improved state-of-the-art results for semantic segmentation. Nevertheless, even modern architectures lack the ability to generalize well to a test dataset that originates from a different domain. To avoid the costly annotation of training data for unseen domains, unsupervised domain adaptation (UDA) attempts to provide efficient knowledge transfer from a labeled source domain to an unlabeled target domain. Previous work has mainly focused on minimizing the discrepancy between the two domains by using adversarial training or self-training. While adversarial training may fail to align the correct semantic categories as it minimizes the discrepancy between the global distributions, self-training raises the question of how to provide reliable pseudo-labels. To align the correct semantic categories across domains, we propose a contrastive learning approach that adapts category-wise centroids across domains. Furthermore, we extend our method with self-training, where we use a memory-efficient temporal ensemble to generate consistent and reliable pseudo-labels. Although both contrastive learning and self-training (CLST) through temporal ensembling enable knowledge transfer between two domains, it is their combination that leads to a symbiotic structure. We validate our approach on two domain adaptation benchmarks: GTA5 $\rightarrow$ Cityscapes and SYNTHIA $\rightarrow$ Cityscapes. Our method achieves better or comparable results than the state-of-the-art. We will make the code publicly available.
MT3: Meta Test-Time Training for Self-Supervised Test-Time Adaption
Mar 30, 2021

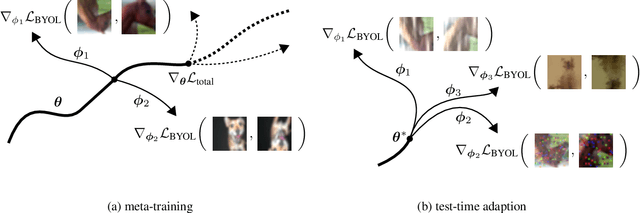

An unresolved problem in Deep Learning is the ability of neural networks to cope with domain shifts during test-time, imposed by commonly fixing network parameters after training. Our proposed method Meta Test-Time Training (MT3), however, breaks this paradigm and enables adaption at test-time. We combine meta-learning, self-supervision and test-time training to learn to adapt to unseen test distributions. By minimizing the self-supervised loss, we learn task-specific model parameters for different tasks. A meta-model is optimized such that its adaption to the different task-specific models leads to higher performance on those tasks. During test-time a single unlabeled image is sufficient to adapt the meta-model parameters. This is achieved by minimizing only the self-supervised loss component resulting in a better prediction for that image. Our approach significantly improves the state-of-the-art results on the CIFAR-10-Corrupted image classification benchmark. Our implementation is available on GitHub.
Anomaly Detection Based on Selection and Weighting in Latent Space
Mar 08, 2021
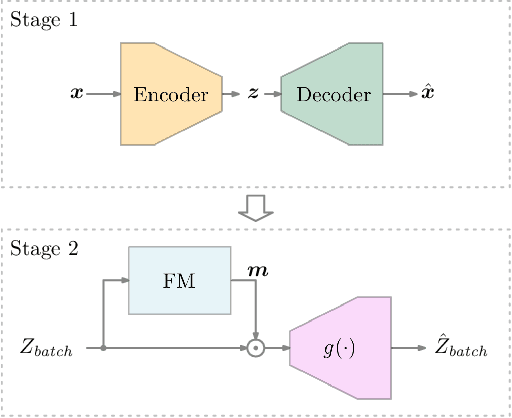


With the high requirements of automation in the era of Industry 4.0, anomaly detection plays an increasingly important role in higher safety and reliability in the production and manufacturing industry. Recently, autoencoders have been widely used as a backend algorithm for anomaly detection. Different techniques have been developed to improve the anomaly detection performance of autoencoders. Nonetheless, little attention has been paid to the latent representations learned by autoencoders. In this paper, we propose a novel selection-and-weighting-based anomaly detection framework called SWAD. In particular, the learned latent representations are individually selected and weighted. Experiments on both benchmark and real-world datasets have shown the effectiveness and superiority of SWAD. On the benchmark datasets, the SWAD framework has reached comparable or even better performance than the state-of-the-art approaches.