 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lost Opportunity for Vision-Language Models: A Comparative Study of Online Test-time Adaptation for Vision-Language Models
May 23, 2024

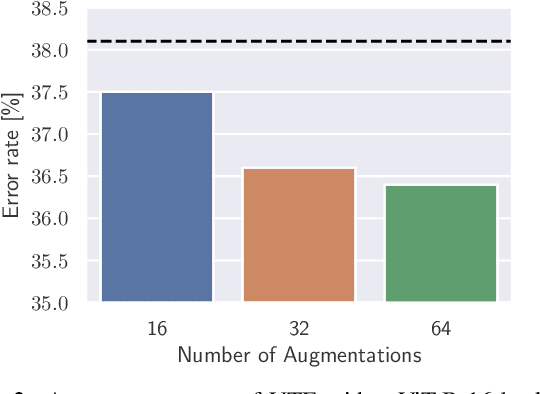

In the realm of deep learning, maintaining model robustness against distribution shifts is critical. This paper investigates test-time adaptation strategies for vision-language models, with a specific focus on CLIP and its variants. Through a systematic exploration of prompt-based techniques and existing test-time adaptation methods, the study aims to enhance the adaptability and robustness of vision-language models in diverse real-world scenarios. The investigation includes an analysis of prompt engineering strategies, such as hand-crafted prompts, prompt ensembles, and prompt learning techniques. We introduce a vision-text-space ensemble that significantly boosts the average performance compared to a text-space-only ensemble. Additionally, our comparative study delves into leveraging existing test-time adaptation methods originally designed for image classification tasks. Experimental evaluations conducted across various datasets and model architectures demonstrate the efficacy of different adaptation strategies. We further give insights into the importance of updating the vision encoder and whether it is beneficial to update the text encoder. Code is available at https://github.com/mariodoebler/test-time-adaptation
Diversity-aware Buffer for Coping with Temporally Correlated Data Streams in Online Test-time Adaptation
Jan 02, 2024

Since distribution shifts are likely to occur after a model's deployment and can drastically decrease the model's performance, online test-time adaptation (TTA) continues to update the model during test-time, leveraging the current test data. In real-world scenarios, test data streams are not always independent and identically distributed (i.i.d.). Instead, they are frequently temporally correlated, making them non-i.i.d. Many existing methods struggle to cope with this scenario. In response, we propose a diversity-aware and category-balanced buffer that can simulate an i.i.d. data stream, even in non-i.i.d. scenarios. Combined with a diversity and entropy-weighted entropy loss, we show that a stable adaptation is possible on a wide range of corruptions and natural domain shifts, based on ImageNet. We achieve state-of-the-art results on most considered benchmarks.
Calibration-free online test-time adaptation for electroencephalography motor imagery decoding
Nov 30, 2023Providing a promising pathway to link the human brain with external devices, Brain-Computer Interfaces (BCIs) have seen notable advancements in decoding capabilities, primarily driven by increasingly sophisticated techniques, especially deep learning. However, achieving high accuracy in real-world scenarios remains a challenge due to the distribution shift between sessions and subjects. In this paper we will explore the concept of online test-time adaptation (OTTA) to continuously adapt the model in an unsupervised fashion during inference time. Our approach guarantees the preservation of privacy by eliminating the requirement to access the source data during the adaptation process. Additionally, OTTA achieves calibration-free operation by not requiring any session- or subject-specific data. We will investigate the task of electroencephalography (EEG) motor imagery decoding using a lightweight architecture together with different OTTA techniques like alignment, adaptive batch normalization, and entropy minimization. We examine two datasets and three distinct data settings for a comprehensive analysis. Our adaptation methods produce state-of-the-art results, potentially instigating a shift in transfer learning for BCI decoding towards online adaptation.
Universal Test-time Adaptation through Weight Ensembling, Diversity Weighting, and Prior Correction
Jun 01, 2023Since distribution shifts are likely to occur during test-time and can drastically decrease the model's performance, online test-time adaptation (TTA) continues to update the model after deployment, leveraging the current test data. Clearly, a method proposed for online TTA has to perform well for all kinds of environmental conditions. By introducing the variable factors 'domain non-stationarity' and 'temporal correlation', we first unfold all practically relevant settings and define the entity as universal TTA. To tackle the problem of universal TTA, we identify and highlight several challenges a self-training based method has to deal with, including: 1) model bias and the occurrence of trivial solutions when performing entropy minimization on varying sequence lengths with and without multiple domain shifts, 2) loss of generalization which exacerbates the adaptation to future domain shifts and the occurrence of catastrophic forgetting, and 3) performance degradation due to shifts in label prior. To prevent the model from becoming biased, we leverage a dataset and model-agnostic certainty and diversity weighting. In order to maintain generalization and prevent catastrophic forgetting, we propose to continually weight-average the source and adapted model. To compensate for disparities in the label prior during test-time, we propose an adaptive additive prior correction scheme. We evaluate our approach, named ROID, on a wide range of settings, datasets, and models, setting new standards in the field of universal TTA.
Robust Mean Teacher for Continual and Gradual Test-Time Adaptation
Nov 23, 2022Since experiencing domain shifts during test-time is inevitable in practice, test-time adaption (TTA) continues to adapt the model during deployment. Recently, the area of continual and gradual test-time adaptation (TTA) emerged. In contrast to standard TTA, continual TTA considers not only a single domain shift, but a sequence of shifts. Gradual TTA further exploits the property that some shifts evolve gradually over time. Since in both settings long test sequences are present, error accumulation needs to be addressed for methods relying on self-training. In this work, we propose and show that in the setting of TTA, the symmetric cross-entropy is better suited as a consistency loss for mean teachers compared to the commonly used cross-entropy. This is justified by our analysis with respect to the (symmetric) cross-entropy's gradient properties. To pull the test feature space closer to the source domain, where the pre-trained model is well posed, contrastive learning is leveraged. Since applications differ in their requirements, we address different settings, namely having source data available and the more challenging source-free setting. We demonstrate the effectiveness of our proposed method 'robust mean teacher' (RMT) on the continual and gradual corruption benchmarks CIFAR10C, CIFAR100C, and Imagenet-C. We further consider ImageNet-R and propose a new continual DomainNet-126 benchmark. State-of-the-art results are achieved on all benchmarks.
Gradual Test-Time Adaptation by Self-Training and Style Transfer
Aug 16, 2022

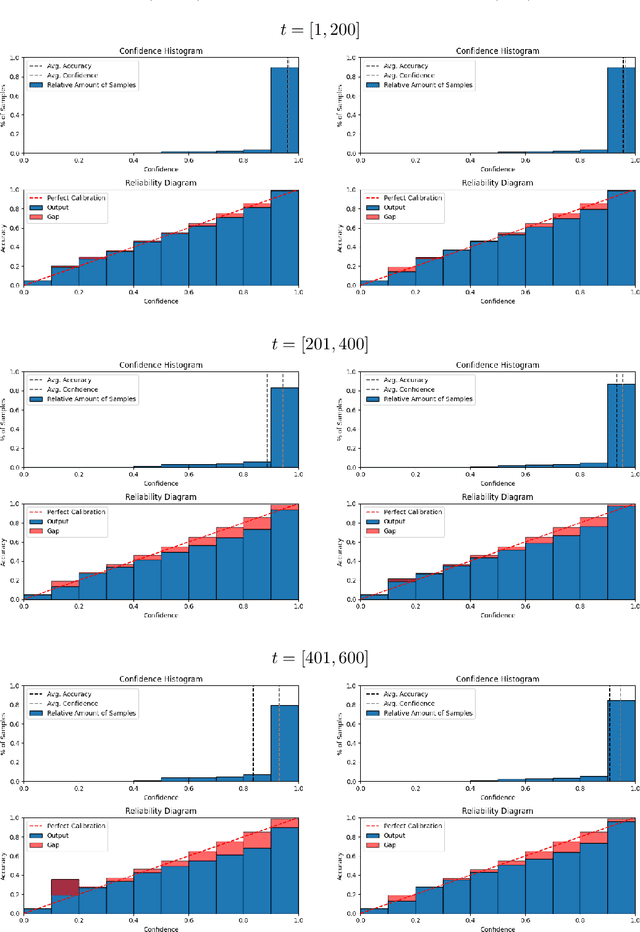

Domain shifts at test-time are inevitable in practice. Test-time adaptation addresses this problem by adapting the model during deployment. Recent work theoretically showed that self-training can be a strong method in the setting of gradual domain shifts. In this work we show the natural connection between gradual domain adaptation and test-time adaptation. We publish a new synthetic dataset called CarlaTTA that allows to explore gradual domain shifts during test-time and evaluate several methods in the area of unsupervised domain adaptation and test-time adaptation. We propose a new method GTTA that is based on self-training and style transfer. GTTA explicitly exploits gradual domain shifts and sets a new standard in this area. We further demonstrate the effectiveness of our method on the continual and gradual CIFAR10C, CIFAR100C, and ImageNet-C benchmark.
Continual Unsupervised Domain Adaptation for Semantic Segmentation using a Class-Specific Transfer
Aug 12, 2022
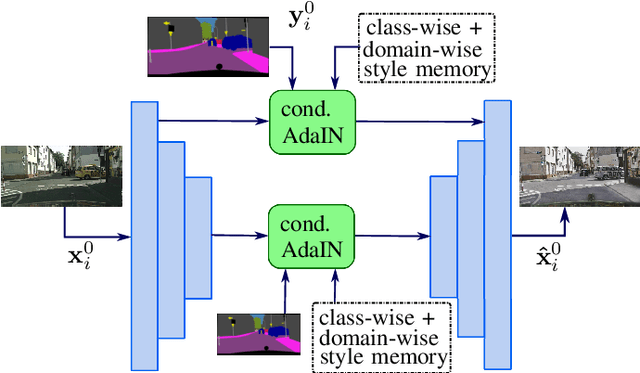
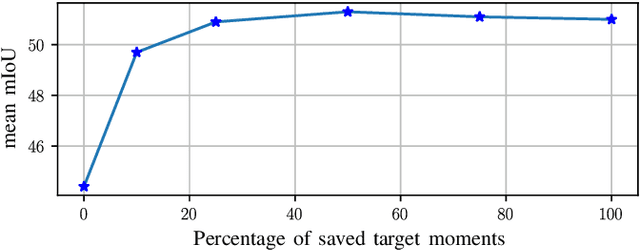
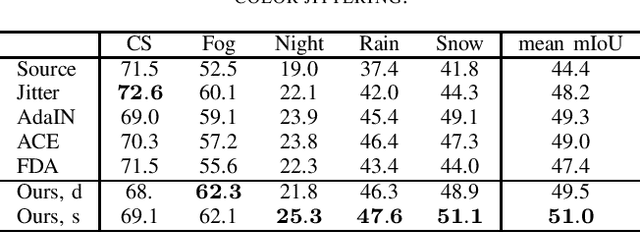
In recent years, there has been tremendous progress in the field of semantic segmentation. However, one remaining challenging problem is that segmentation models do not generalize to unseen domains. To overcome this problem, one either has to label lots of data covering the whole variety of domains, which is often infeasible in practice, or apply unsupervised domain adaptation (UDA), only requiring labeled source data. In this work, we focus on UDA and additionally address the case of adapting not only to a single domain, but to a sequence of target domains. This requires mechanisms preventing the model from forgetting its previously learned knowledge. To adapt a segmentation model to a target domain, we follow the idea of utilizing light-weight style transfer to convert the style of labeled source images into the style of the target domain, while retaining the source content. To mitigate the distributional shift between the source and the target domain, the model is fine-tuned on the transferred source images in a second step. Existing light-weight style transfer approaches relying on adaptive instance normalization (AdaIN) or Fourier transformation still lack performance and do not substantially improve upon common data augmentation, such as color jittering. The reason for this is that these methods do not focus on region- or class-specific differences, but mainly capture the most salient style. Therefore, we propose a simple and light-weight framework that incorporates two class-conditional AdaIN layers. To extract the class-specific target moments needed for the transfer layers, we use unfiltered pseudo-labels, which we show to be an effective approximation compared to real labels. We extensively validate our approach (CACE) on a synthetic sequence and further propose a challenging sequence consisting of real domains. CACE outperforms existing methods visually and quantitatively.
An Unsupervised Domain Adaptive Approach for Multimodal 2D Object Detection in Adverse Weather Conditions
Mar 07, 2022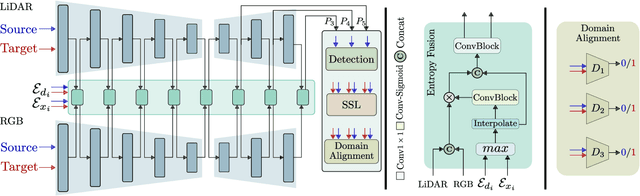
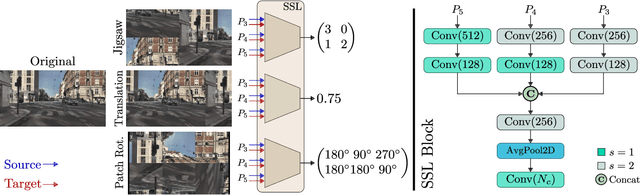
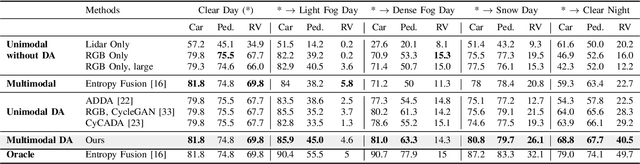
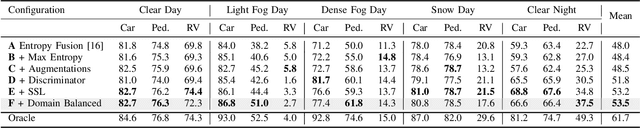
Integrating different representations from complementary sensing modalities is crucial for robust scene interpretation in autonomous driving. While deep learning architectures that fuse vision and range data for 2D object detection have thrived in recent years, the corresponding modalities can degrade in adverse weather or lighting conditions, ultimately leading to a drop in performance. Although domain adaptation methods attempt to bridge the domain gap between source and target domains, they do not readily extend to heterogeneous data distributions. In this work, we propose an unsupervised domain adaptation framework, which adapts a 2D object detector for RGB and lidar sensors to one or more target domains featuring adverse weather conditions. Our proposed approach consists of three components. First, a data augmentation scheme that simulates weather distortions is devised to add domain confusion and prevent overfitting on the source data. Second, to promote cross-domain foreground object alignment, we leverage the complementary features of multiple modalities through a multi-scale entropy-weighted domain discriminator. Finally, we use carefully designed pretext tasks to learn a more robust representation of the target domain data. Experiments performed on the DENSE dataset show that our method can substantially alleviate the domain gap under the single-target domain adaptation (STDA) setting and the less explored yet more general multi-target domain adaptation (MTDA) setting.
Contrastive Learning and Self-Training for Unsupervised Domain Adaptation in Semantic Segmentation
May 05, 2021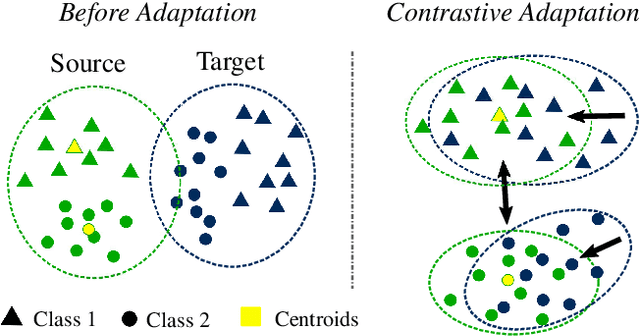
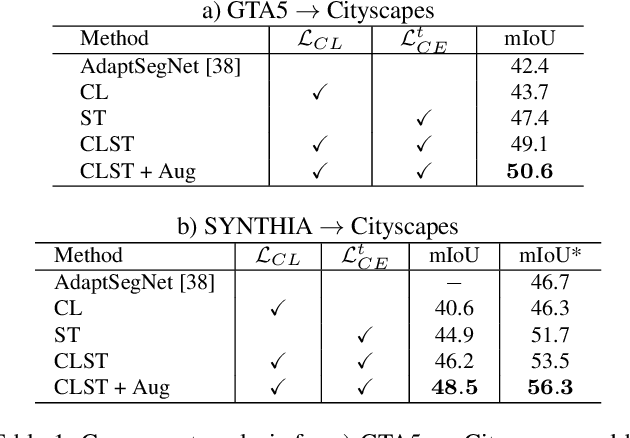
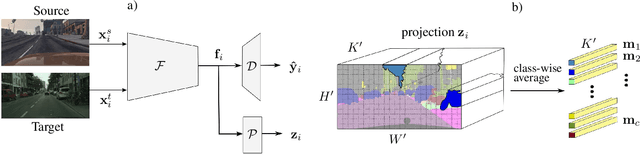
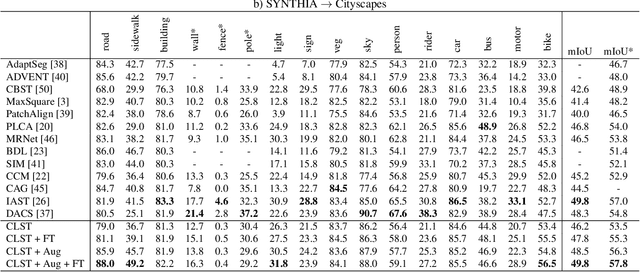
Deep convolutional neural networks have considerably improved state-of-the-art results for semantic segmentation. Nevertheless, even modern architectures lack the ability to generalize well to a test dataset that originates from a different domain. To avoid the costly annotation of training data for unseen domains, unsupervised domain adaptation (UDA) attempts to provide efficient knowledge transfer from a labeled source domain to an unlabeled target domain. Previous work has mainly focused on minimizing the discrepancy between the two domains by using adversarial training or self-training. While adversarial training may fail to align the correct semantic categories as it minimizes the discrepancy between the global distributions, self-training raises the question of how to provide reliable pseudo-labels. To align the correct semantic categories across domains, we propose a contrastive learning approach that adapts category-wise centroids across domains. Furthermore, we extend our method with self-training, where we use a memory-efficient temporal ensemble to generate consistent and reliable pseudo-labels. Although both contrastive learning and self-training (CLST) through temporal ensembling enable knowledge transfer between two domains, it is their combination that leads to a symbiotic structure. We validate our approach on two domain adaptation benchmarks: GTA5 $\rightarrow$ Cityscapes and SYNTHIA $\rightarrow$ Cityscapes. Our method achieves better or comparable results than the state-of-the-art. We will make the code publicly available.
MT3: Meta Test-Time Training for Self-Supervised Test-Time Adaption
Mar 30, 2021

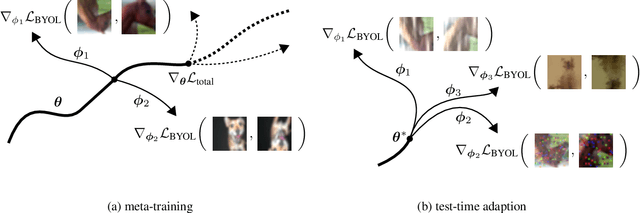

An unresolved problem in Deep Learning is the ability of neural networks to cope with domain shifts during test-time, imposed by commonly fixing network parameters after training. Our proposed method Meta Test-Time Training (MT3), however, breaks this paradigm and enables adaption at test-time. We combine meta-learning, self-supervision and test-time training to learn to adapt to unseen test distributions. By minimizing the self-supervised loss, we learn task-specific model parameters for different tasks. A meta-model is optimized such that its adaption to the different task-specific models leads to higher performance on those tasks. During test-time a single unlabeled image is sufficient to adapt the meta-model parameters. This is achieved by minimizing only the self-supervised loss component resulting in a better prediction for that image. Our approach significantly improves the state-of-the-art results on the CIFAR-10-Corrupted image classification benchmark. Our implementation is available on GitHub.