 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Unsupervised Domain Adaptation for Semantic Segmentation using a Class-Specific Transfer
Aug 12, 2022
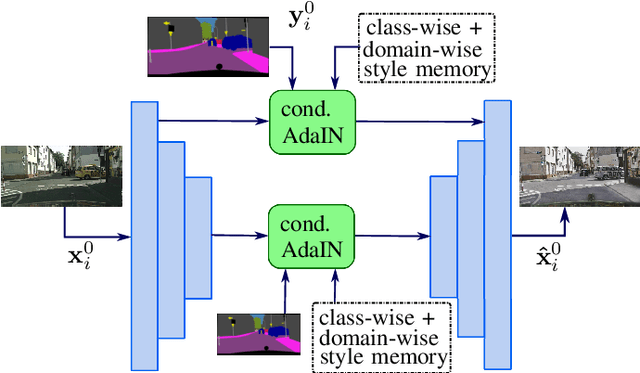
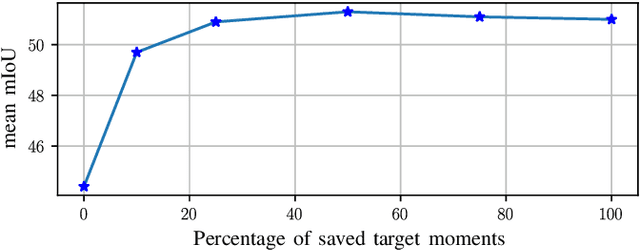
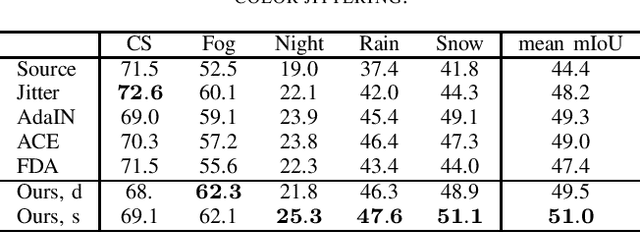
In recent years, there has been tremendous progress in the field of semantic segmentation. However, one remaining challenging problem is that segmentation models do not generalize to unseen domains. To overcome this problem, one either has to label lots of data covering the whole variety of domains, which is often infeasible in practice, or apply unsupervised domain adaptation (UDA), only requiring labeled source data. In this work, we focus on UDA and additionally address the case of adapting not only to a single domain, but to a sequence of target domains. This requires mechanisms preventing the model from forgetting its previously learned knowledge. To adapt a segmentation model to a target domain, we follow the idea of utilizing light-weight style transfer to convert the style of labeled source images into the style of the target domain, while retaining the source content. To mitigate the distributional shift between the source and the target domain, the model is fine-tuned on the transferred source images in a second step. Existing light-weight style transfer approaches relying on adaptive instance normalization (AdaIN) or Fourier transformation still lack performance and do not substantially improve upon common data augmentation, such as color jittering. The reason for this is that these methods do not focus on region- or class-specific differences, but mainly capture the most salient style. Therefore, we propose a simple and light-weight framework that incorporates two class-conditional AdaIN layers. To extract the class-specific target moments needed for the transfer layers, we use unfiltered pseudo-labels, which we show to be an effective approximation compared to real labels. We extensively validate our approach (CACE) on a synthetic sequence and further propose a challenging sequence consisting of real domains. CACE outperforms existing methods visually and quantitatively.
TTAPS: Test-Time Adaption by Aligning Prototypes using Self-Supervision
May 18, 2022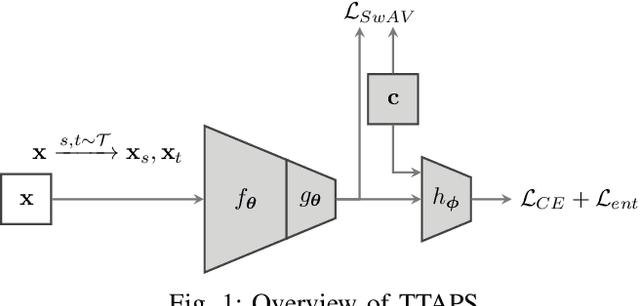
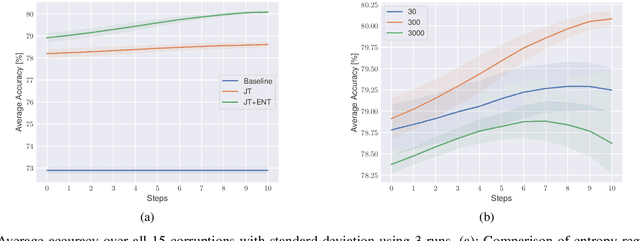
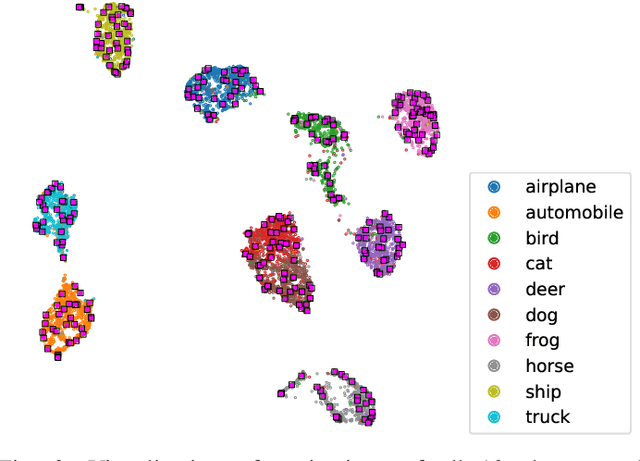

Nowadays, deep neural networks outperform humans in many tasks. However, if the input distribution drifts away from the one used in training, their performance drops significantly. Recently published research has shown that adapting the model parameters to the test sample can mitigate this performance degradation. In this paper, we therefore propose a novel modification of the self-supervised training algorithm SwAV that adds the ability to adapt to single test samples. Using the provided prototypes of SwAV and our derived test-time loss, we align the representation of unseen test samples with the self-supervised learned prototypes. We show the success of our method on the common benchmark dataset CIFAR10-C.
Estimation of Bivariate Structural Causal Models by Variational Gaussian Process Regression Under Likelihoods Parametrised by Normalising Flows
Sep 06, 2021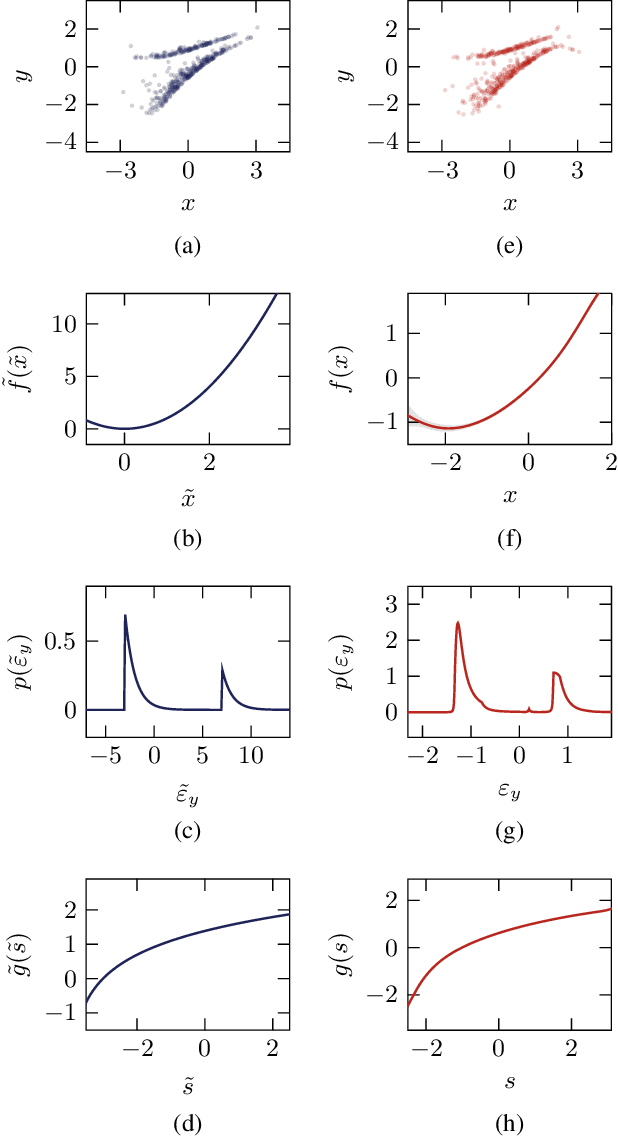
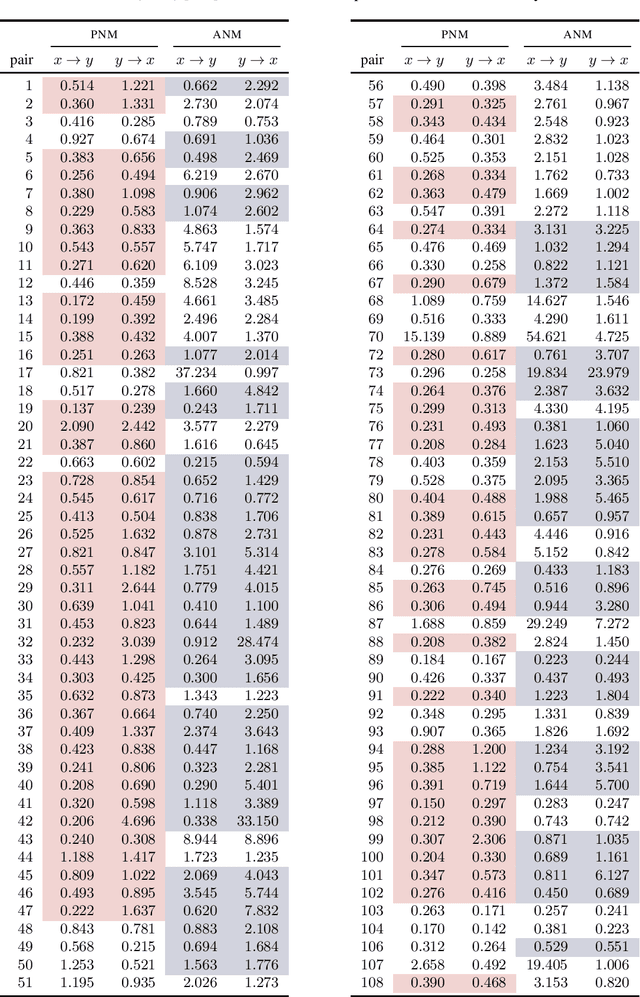
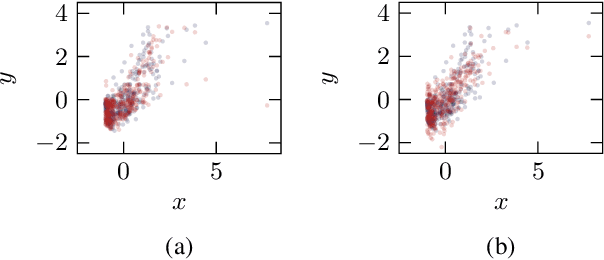
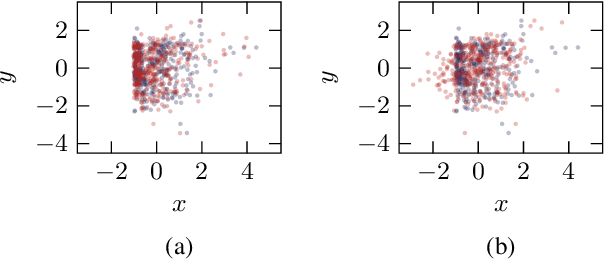
One major drawback of state-of-the-art artificial intelligence is its lack of explainability. One approach to solve the problem is taking causality into account. Causal mechanisms can be described by structural causal models. In this work, we propose a method for estimating bivariate structural causal models using a combination of normalising flows applied to density estimation and variational Gaussian process regression for post-nonlinear models. It facilitates causal discovery, i.e. distinguishing cause and effect, by either the independence of cause and residual or a likelihood ratio test. Our method which estimates post-nonlinear models can better explain a variety of real-world cause-effect pairs than a simple additive noise model. Though it remains difficult to exploit this benefit regarding all pairs from the T\"ubingen benchmark database, we demonstrate that combining the additive noise model approach with our method significantly enhances causal discovery.
MT3: Meta Test-Time Training for Self-Supervised Test-Time Adaption
Mar 30, 2021

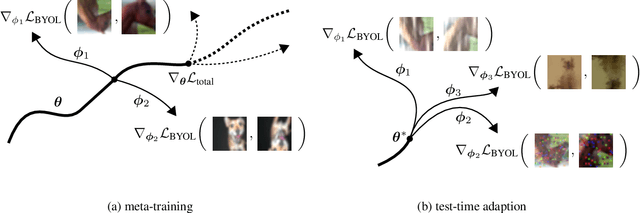

An unresolved problem in Deep Learning is the ability of neural networks to cope with domain shifts during test-time, imposed by commonly fixing network parameters after training. Our proposed method Meta Test-Time Training (MT3), however, breaks this paradigm and enables adaption at test-time. We combine meta-learning, self-supervision and test-time training to learn to adapt to unseen test distributions. By minimizing the self-supervised loss, we learn task-specific model parameters for different tasks. A meta-model is optimized such that its adaption to the different task-specific models leads to higher performance on those tasks. During test-time a single unlabeled image is sufficient to adapt the meta-model parameters. This is achieved by minimizing only the self-supervised loss component resulting in a better prediction for that image. Our approach significantly improves the state-of-the-art results on the CIFAR-10-Corrupted image classification benchmark. Our implementation is available on GitHub.
Condensed Composite Memory Continual Learning
Feb 19, 2021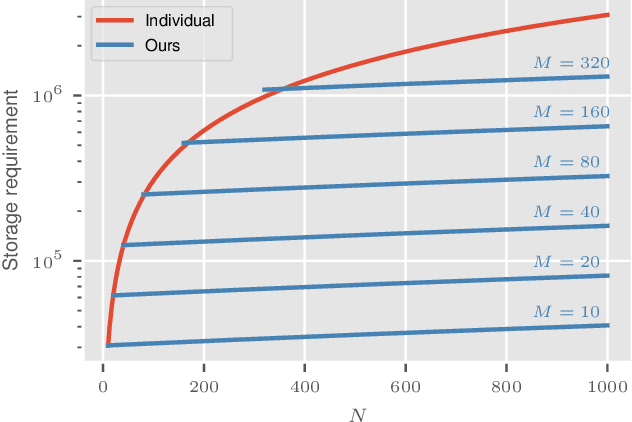
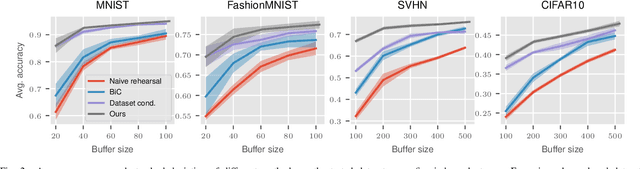

Deep Neural Networks (DNNs) suffer from a rapid decrease in performance when trained on a sequence of tasks where only data of the most recent task is available. This phenomenon, known as catastrophic forgetting, prevents DNNs from accumulating knowledge over time. Overcoming catastrophic forgetting and enabling continual learning is of great interest since it would enable the application of DNNs in settings where unrestricted access to all the training data at any time is not always possible, e.g. due to storage limitations or legal issues. While many recently proposed methods for continual learning use some training examples for rehearsal, their performance strongly depends on the number of stored examples. In order to improve performance of rehearsal for continual learning, especially for a small number of stored examples, we propose a novel way of learning a small set of synthetic examples which capture the essence of a complete dataset. Instead of directly learning these synthetic examples, we learn a weighted combination of shared components for each example that enables a significant increase in memory efficiency. We demonstrate the performance of our method on commonly used datasets and compare it to recently proposed related methods and baselines.
Localizing Catastrophic Forgetting in Neural Networks
Jun 06, 2019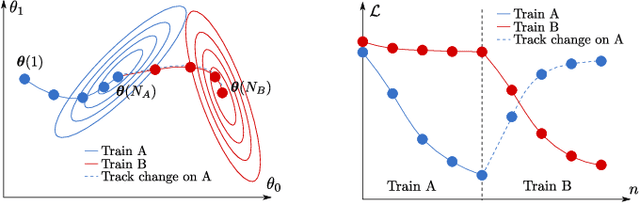
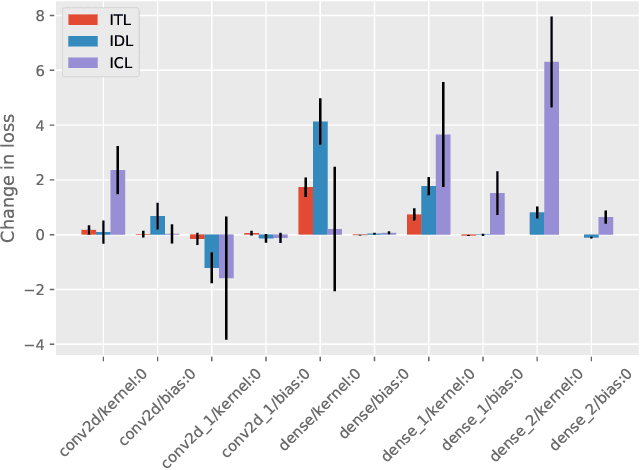
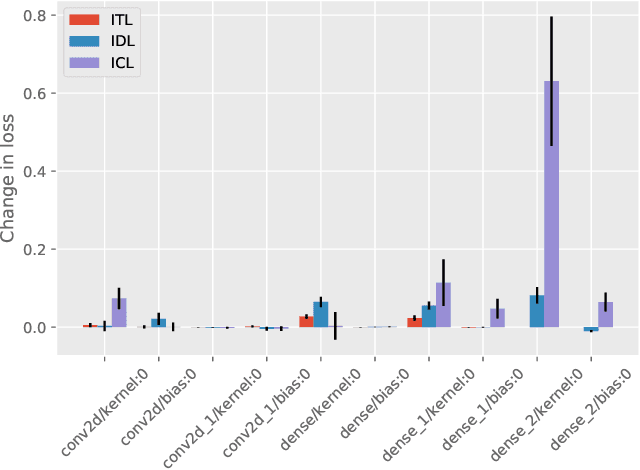
Artificial neural networks (ANNs) suffer from catastrophic forgetting when trained on a sequence of tasks. While this phenomenon was studied in the past, there is only very limited recent research on this phenomenon. We propose a method for determining the contribution of individual parameters in an ANN to catastrophic forgetting. The method is used to analyze an ANNs response to three different continual learning scenarios.