 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCondensed Composite Memory Continual Learning
Paper and Code
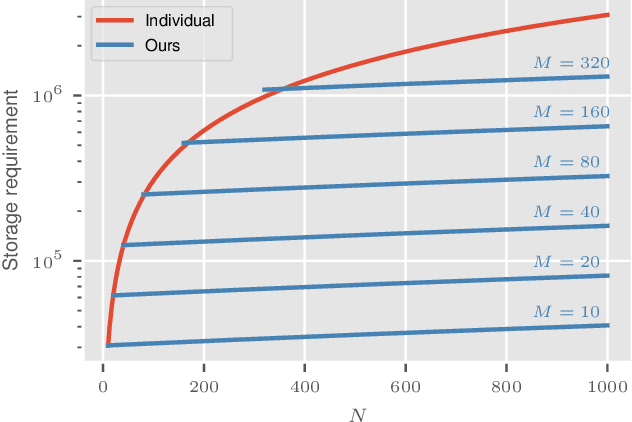
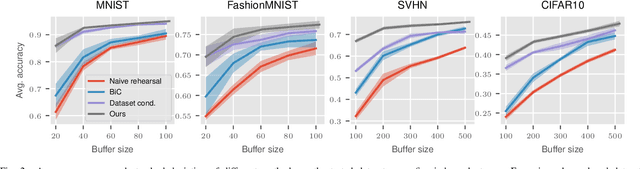

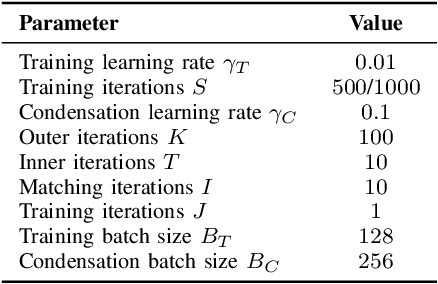
Deep Neural Networks (DNNs) suffer from a rapid decrease in performance when trained on a sequence of tasks where only data of the most recent task is available. This phenomenon, known as catastrophic forgetting, prevents DNNs from accumulating knowledge over time. Overcoming catastrophic forgetting and enabling continual learning is of great interest since it would enable the application of DNNs in settings where unrestricted access to all the training data at any time is not always possible, e.g. due to storage limitations or legal issues. While many recently proposed methods for continual learning use some training examples for rehearsal, their performance strongly depends on the number of stored examples. In order to improve performance of rehearsal for continual learning, especially for a small number of stored examples, we propose a novel way of learning a small set of synthetic examples which capture the essence of a complete dataset. Instead of directly learning these synthetic examples, we learn a weighted combination of shared components for each example that enables a significant increase in memory efficiency. We demonstrate the performance of our method on commonly used datasets and compare it to recently proposed related methods and baselines.