 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prompts to Performance: Evaluating LLMs for Task-based Parallel Code Generation
Feb 24, 2026Large Language Models (LLM) show strong abilities in code generation, but their skill in creating efficient parallel programs is less studied. This paper explores how LLMs generate task-based parallel code from three kinds of input prompts: natural language problem descriptions, sequential reference implementations, and parallel pseudo code. We focus on three programming frameworks: OpenMP Tasking, C++ standard parallelism, and the asynchronous many-task runtime HPX. Each framework offers different levels of abstraction and control for task execution. We evaluate LLM-generated solutions for correctness and scalability. Our results reveal both strengths and weaknesses of LLMs with regard to problem complexity and framework. Finally, we discuss what these findings mean for future LLM-assisted development in high-performance and scientific computing.
Large Language Models (LLMs) for Electronic Design Automation (EDA)
Aug 27, 2025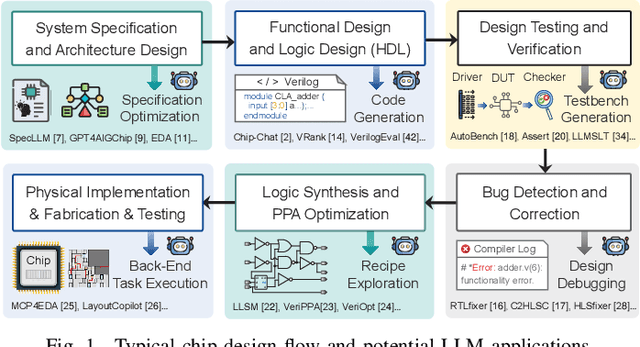
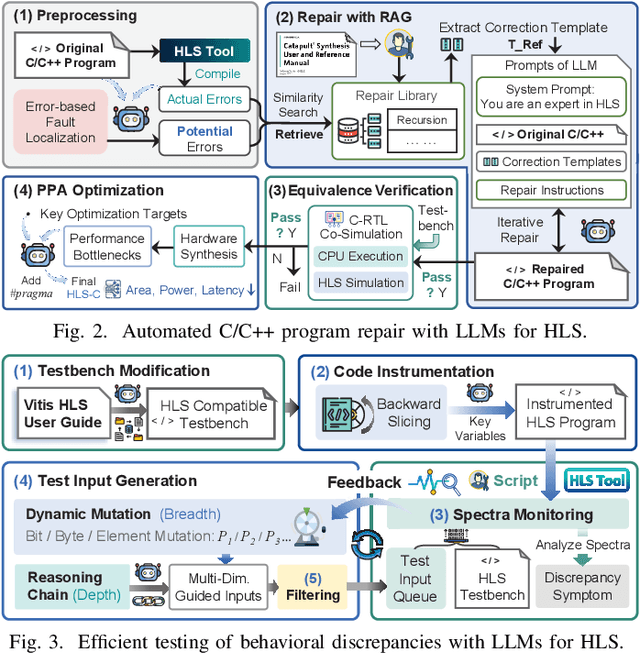
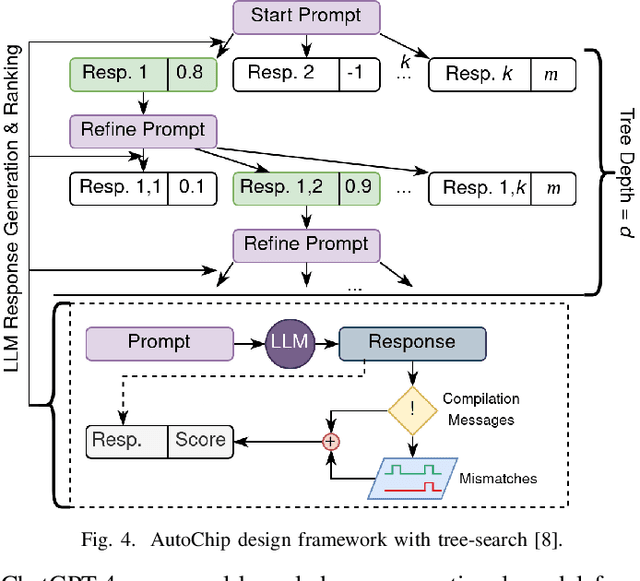
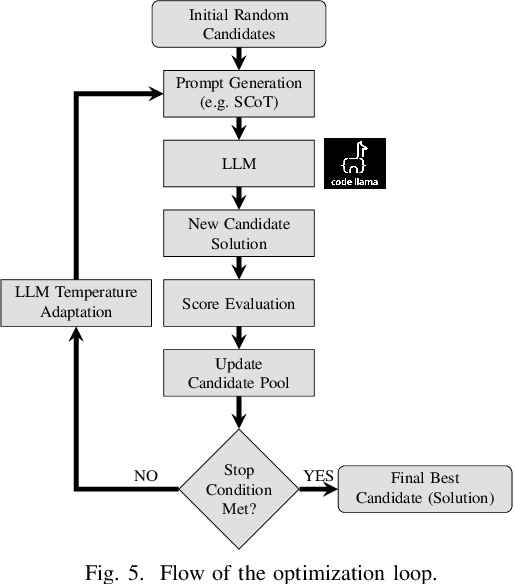
With the growing complexity of modern integrated circuits, hardware engineers are required to devote more effort to the full design-to-manufacturing workflow. This workflow involves numerous iterations, making it both labor-intensive and error-prone. Therefore, there is an urgent demand for more efficient Electronic Design Automation (EDA) solutions to accelerate hardware development. Recently, large language models (LLMs) have shown remarkable advancements in contextual comprehension, logical reasoning, and generative capabilities. Since hardware designs and intermediate scripts can be represented as text, integrating LLM for EDA offers a promising opportunity to simplify and even automate the entire workflow. Accordingly, this paper provides a comprehensive overview of incorporating LLMs into EDA, with emphasis on their capabilities, limitations, and future opportunities. Three case studies, along with their outlook, are introduced to demonstrate the capabilities of LLMs in hardware design, testing, and optimization. Finally, future directions and challenges are highlighted to further explore the potential of LLMs in shaping the next-generation EDA, providing valuable insights for researchers interested in leveraging advanced AI technologies for EDA.
GPRat: Gaussian Process Regression with Asynchronous Tasks
Apr 30, 2025Python is the de-facto language for software development in artificial intelligence (AI). Commonly used libraries, such as PyTorch and TensorFlow, rely on parallelization built into their BLAS backends to achieve speedup on CPUs. However, only applying parallelization in a low-level backend can lead to performance and scaling degradation. In this work, we present a novel way of binding task-based C++ code built on the asynchronous runtime model HPX to a high-level Python API using pybind11. We develop a parallel Gaussian process (GP) li- brary as an application. The resulting Python library GPRat combines the ease of use of commonly available GP libraries with the performance and scalability of asynchronous runtime systems. We evaluate the per- formance on a mass-spring-damper system, a standard benchmark from control theory, for varying numbers of regressors (features). The results show almost no binding overhead when binding the asynchronous HPX code using pybind11. Compared to GPyTorch and GPflow, GPRat shows superior scaling on up to 64 cores on an AMD EPYC 7742 CPU for train- ing. Furthermore, our library achieves a prediction speedup of 7.63 over GPyTorch and 25.25 over GPflow. If we increase the number of features from eight to 128, we observe speedups of 29.62 and 21.19, respectively. These results showcase the potential of using asynchronous tasks within Python-based AI applications.
Large Language Models to Generate System-Level Test Programs Targeting Non-functional Properties
Mar 19, 2024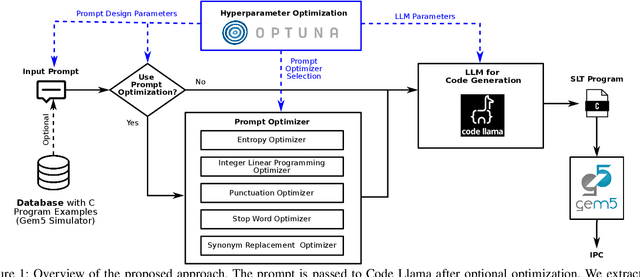
System-Level Test (SLT) has been a part of the test flow for integrated circuits for over a decade and still gains importance. However, no systematic approaches exist for test program generation, especially targeting non-functional properties of the Device under Test (DUT). Currently, test engineers manually compose test suites from off-the-shelf software, approximating the end-user environment of the DUT. This is a challenging and tedious task that does not guarantee sufficient control over non-functional properties. This paper proposes Large Language Models (LLMs) to generate test programs. We take a first glance at how pre-trained LLMs perform in test program generation to optimize non-functional properties of the DUT. Therefore, we write a prompt to generate C code snippets that maximize the instructions per cycle of a super-scalar, out-of-order architecture in simulation. Additionally, we apply prompt and hyperparameter optimization to achieve the best possible results without further training.
Deep learning based surrogate modeling for thermal plume prediction of groundwater heat pumps
Feb 16, 2023The ability for groundwater heat pumps to meet space heating and cooling demands without relying on fossil fuels, has prompted their mass roll out in dense urban environments. In regions with high subsurface groundwater flow rates, the thermal plume generated from a heat pump's injection well can propagate downstream, affecting surrounding users and reducing their heat pump efficiency. To reduce the probability of interference, regulators often rely on simple analytical models or high fidelity groundwater simulations to determine the impact that a heat pump has on the subsurface aquifer and surrounding heat pumps. These are either too inaccurate or too computationally expensive for everyday use. In this work, a surrogate model was developed to provide a quick, high accuracy prediction tool of the thermal plume generated by a heat pump within heterogeneous subsurface aquifers. Three variations of a convolutional neural network were developed that accepts the known groundwater Darcy velocities as discrete two-dimensional inputs and predicts the temperature within the subsurface aquifer around the heat pump. A data set consisting of 800 numerical simulation samples, generated from random permeability fields and pressure boundary conditions, was used to provide pseudo-randomized Darcy velocity fields as input fields and the temperature field solution for training the network. The subsurface temperature field output from the network provides a more realistic temperature field that follows the Darcy velocity streamlines, while being orders of magnitude faster than conventional high fidelity solvers
PDEBENCH: An Extensive Benchmark for Scientific Machine Learning
Oct 17, 2022
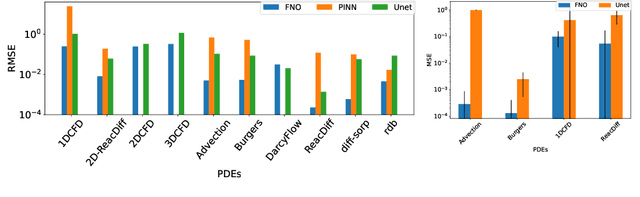
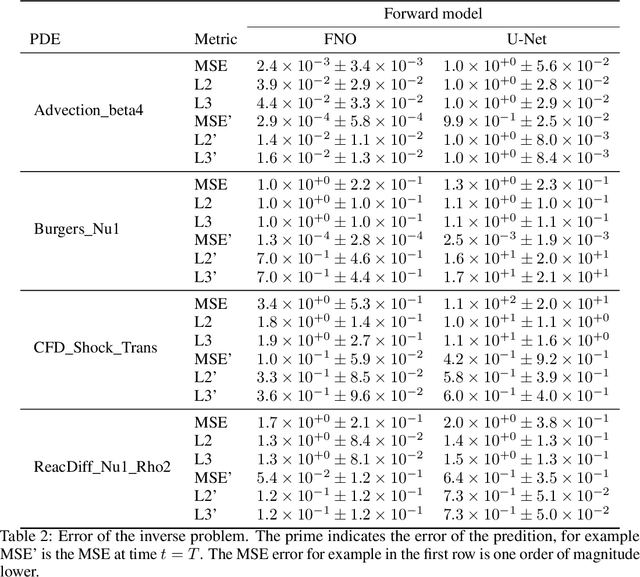
Machine learning-based modeling of physical systems has experienced increased interest in recent years. Despite some impressive progress, there is still a lack of benchmarks for Scientific ML that are easy to use but still challenging and representative of a wide range of problems. We introduce PDEBench, a benchmark suite of time-dependent simulation tasks based on Partial Differential Equations (PDEs). PDEBench comprises both code and data to benchmark the performance of novel machine learning models against both classical numerical simulations and machine learning baselines. Our proposed set of benchmark problems contribute the following unique features: (1) A much wider range of PDEs compared to existing benchmarks, ranging from relatively common examples to more realistic and difficult problems; (2) much larger ready-to-use datasets compared to prior work, comprising multiple simulation runs across a larger number of initial and boundary conditions and PDE parameters; (3) more extensible source codes with user-friendly APIs for data generation and baseline results with popular machine learning models (FNO, U-Net, PINN, Gradient-Based Inverse Method). PDEBench allows researchers to extend the benchmark freely for their own purposes using a standardized API and to compare the performance of new models to existing baseline methods. We also propose new evaluation metrics with the aim to provide a more holistic understanding of learning methods in the context of Scientific ML. With those metrics we identify tasks which are challenging for recent ML methods and propose these tasks as future challenges for the community. The code is available at https://github.com/pdebench/PDEBench.
A Deep Learning Approach for Thermal Plume Prediction of Groundwater Heat Pumps
Mar 29, 2022


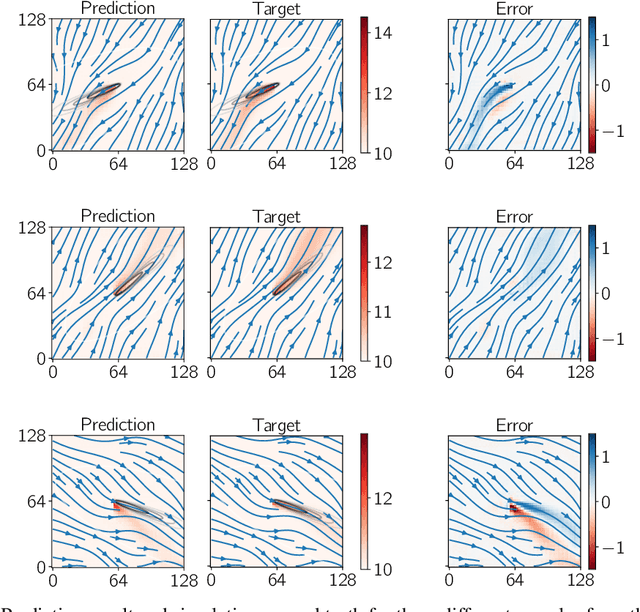
Climate control of buildings makes up a significant portion of global energy consumption, with groundwater heat pumps providing a suitable alternative. To prevent possibly negative interactions between heat pumps throughout a city, city planners have to optimize their layouts in the future. We develop a novel data-driven approach for building small-scale surrogates for modelling the thermal plumes generated by groundwater heat pumps in the surrounding subsurface water. Building on a data set generated from 2D numerical simulations, we train a convolutional neural network for predicting steady-state subsurface temperature fields from a given subsurface velocity field. We show that compared to existing models ours can capture more complex dynamics while still being quick to compute. The resulting surrogate is thus well-suited for interactive design tools by city planners.
PLSSVM: A (multi-)GPGPU-accelerated Least Squares Support Vector Machine
Mar 18, 2022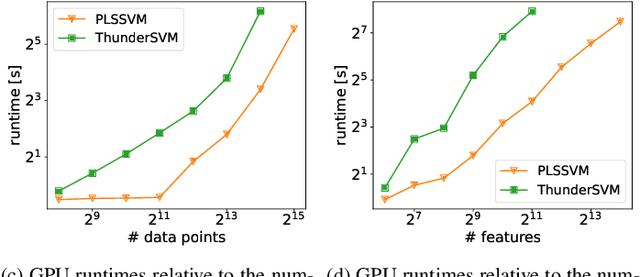
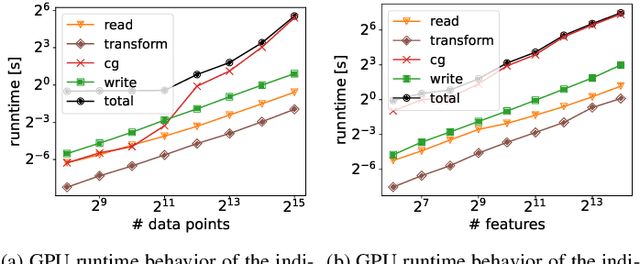
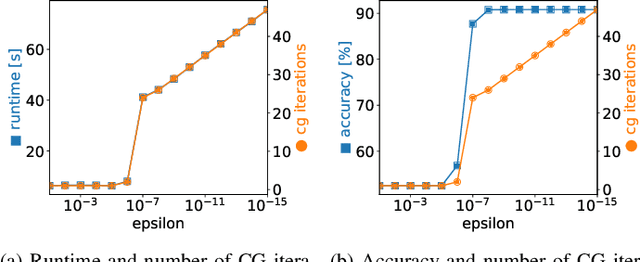
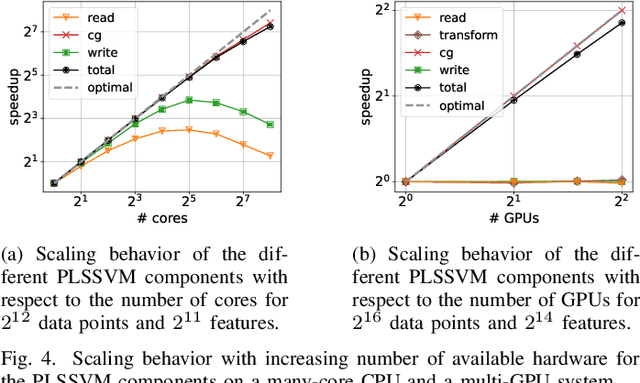
Machine learning algorithms must be able to efficiently cope with massive data sets. Therefore, they have to scale well on any modern system and be able to exploit the computing power of accelerators independent of their vendor. In the field of supervised learning, Support Vector Machines (SVMs) are widely used. However, even modern and optimized implementations such as LIBSVM or ThunderSVM do not scale well for large non-trivial dense data sets on cutting-edge hardware: Most SVM implementations are based on Sequential Minimal Optimization, an optimized though inherent sequential algorithm. Hence, they are not well-suited for highly parallel GPUs. Furthermore, we are not aware of a performance portable implementation that supports CPUs and GPUs from different vendors. We have developed the PLSSVM library to solve both issues. First, we resort to the formulation of the SVM as a least squares problem. Training an SVM then boils down to solving a system of linear equations for which highly parallel algorithms are known. Second, we provide a hardware independent yet efficient implementation: PLSSVM uses different interchangeable backends--OpenMP, CUDA, OpenCL, SYCL--supporting modern hardware from various vendors like NVIDIA, AMD, or Intel on multiple GPUs. PLSSVM can be used as a drop-in replacement for LIBSVM. We observe a speedup on CPUs of up to 10 compared to LIBSVM and on GPUs of up to 14 compared to ThunderSVM. Our implementation scales on many-core CPUs with a parallel speedup of 74.7 on up to 256 CPU threads and on multiple GPUs with a parallel speedup of 3.71 on four GPUs. The code, utility scripts, and documentation are all available on GitHub: https://github.com/SC-SGS/PLSSVM.
Surrogate-data-enriched Physics-Aware Neural Networks
Dec 15, 2021
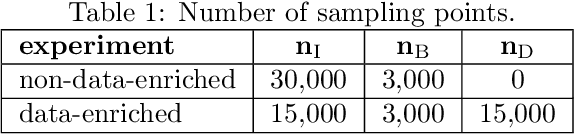

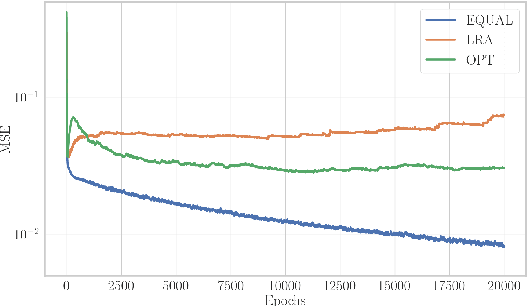
Neural networks can be used as surrogates for PDE models. They can be made physics-aware by penalizing underlying equations or the conservation of physical properties in the loss function during training. Current approaches allow to additionally respect data from numerical simulations or experiments in the training process. However, this data is frequently expensive to obtain and thus only scarcely available for complex models. In this work, we investigate how physics-aware models can be enriched with computationally cheaper, but inexact, data from other surrogate models like Reduced-Order Models (ROMs). In order to avoid trusting too-low-fidelity surrogate solutions, we develop an approach that is sensitive to the error in inexact data. As a proof of concept, we consider the one-dimensional wave equation and show that the training accuracy is increased by two orders of magnitude when inexact data from ROMs is incorporated.
How to Avoid Trivial Solutions in Physics-Informed Neural Networks
Dec 10, 2021


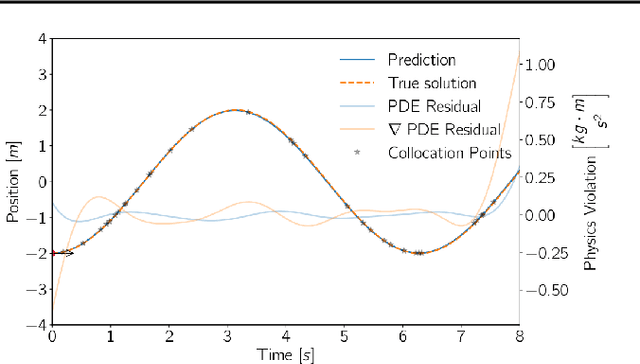
The advent of scientific machine learning (SciML) has opened up a new field with many promises and challenges in the field of simulation science by developing approaches at the interface of physics- and data-based modelling. To this end, physics-informed neural networks (PINNs) have been introduced in recent years, which cope for the scarcity in training data by incorporating physics knowledge of the problem at so-called collocation points. In this work, we investigate the prediction performance of PINNs with respect to the number of collocation points used to enforce the physics-based penalty terms. We show that PINNs can fail, learning a trivial solution that fulfills the physics-derived penalty term by definition. We have developed an alternative sampling approach and a new penalty term enabling us to remedy this core problem of PINNs in data-scarce settings with competitive results while reducing the amount of collocation points needed by up to 80 \% for benchmark problems.