 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven identification of latent port-Hamiltonian systems
Aug 15, 2024



Conventional physics-based modeling techniques involve high effort, e.g., time and expert knowledge, while data-driven methods often lack interpretability, structure, and sometimes reliability. To mitigate this, we present a data-driven system identification framework that derives models in the port-Hamiltonian (pH) formulation. This formulation is suitable for multi-physical systems while guaranteeing the useful system theoretical properties of passivity and stability. Our framework combines linear and nonlinear reduction with structured, physics-motivated system identification. In this process, high-dimensional state data obtained from possibly nonlinear systems serves as input for an autoencoder, which then performs two tasks: (i) nonlinearly transforming and (ii) reducing this data onto a low-dimensional latent space. In this space, a linear pH system, that satisfies the pH properties per construction, is parameterized by the weights of a neural network. The mathematical requirements are met by defining the pH matrices through Cholesky factorizations. The neural networks that define the coordinate transformation and the pH system are identified in a joint optimization process to match the dynamics observed in the data while defining a linear pH system in the latent space. The learned, low-dimensional pH system can describe even nonlinear systems and is rapidly computable due to its small size. The method is exemplified by a parametric mass-spring-damper and a nonlinear pendulum example, as well as the high-dimensional model of a disc brake with linear thermoelastic behavior.
Surrogate-data-enriched Physics-Aware Neural Networks
Dec 15, 2021

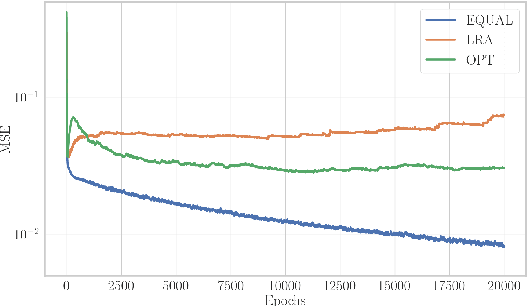
Neural networks can be used as surrogates for PDE models. They can be made physics-aware by penalizing underlying equations or the conservation of physical properties in the loss function during training. Current approaches allow to additionally respect data from numerical simulations or experiments in the training process. However, this data is frequently expensive to obtain and thus only scarcely available for complex models. In this work, we investigate how physics-aware models can be enriched with computationally cheaper, but inexact, data from other surrogate models like Reduced-Order Models (ROMs). In order to avoid trusting too-low-fidelity surrogate solutions, we develop an approach that is sensitive to the error in inexact data. As a proof of concept, we consider the one-dimensional wave equation and show that the training accuracy is increased by two orders of magnitude when inexact data from ROMs is incorporated.
Universality and Optimality of Structured Deep Kernel Networks
May 15, 2021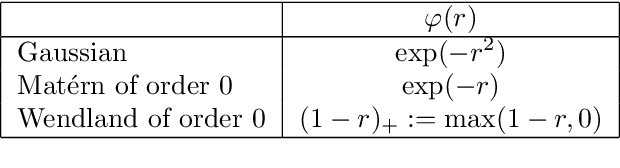
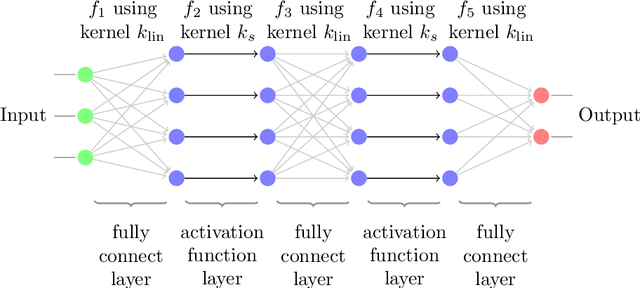

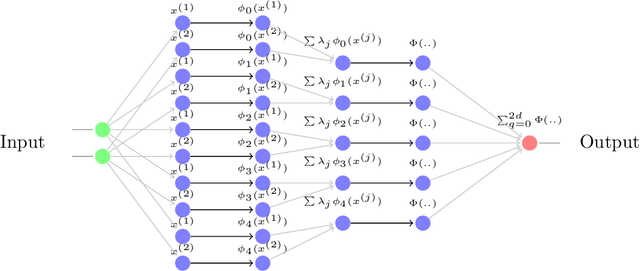
Kernel based methods yield approximation models that are flexible, efficient and powerful. In particular, they utilize fixed feature maps of the data, being often associated to strong analytical results that prove their accuracy. On the other hand, the recent success of machine learning methods has been driven by deep neural networks (NNs). They achieve a significant accuracy on very high-dimensional data, in that they are able to learn also efficient data representations or data-based feature maps. In this paper, we leverage a recent deep kernel representer theorem to connect the two approaches and understand their interplay. In particular, we show that the use of special types of kernels yield models reminiscent of neural networks that are founded in the same theoretical framework of classical kernel methods, while enjoying many computational properties of deep neural networks. Especially the introduced Structured Deep Kernel Networks (SDKNs) can be viewed as neural networks with optimizable activation functions obeying a representer theorem. Analytic properties show their universal approximation properties in different asymptotic regimes of unbounded number of centers, width and depth. Especially in the case of unbounded depth, the constructions is asymptotically better than corresponding constructions for ReLU neural networks, which is made possible by the flexibility of kernel approximation
Structured Deep Kernel Networks for Data-Driven Closure Terms of Turbulent Flows
Mar 25, 2021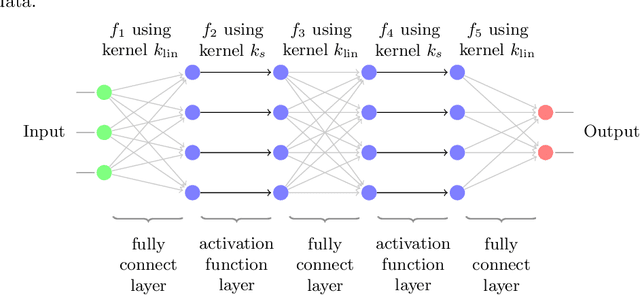
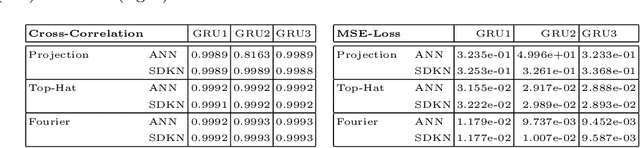
Standard kernel methods for machine learning usually struggle when dealing with large datasets. We review a recently introduced Structured Deep Kernel Network (SDKN) approach that is capable of dealing with high-dimensional and huge datasets - and enjoys typical standard machine learning approximation properties. We extend the SDKN to combine it with standard machine learning modules and compare it with Neural Networks on the scientific challenge of data-driven prediction of closure terms of turbulent flows. We show experimentally that the SDKNs are capable of dealing with large datasets and achieve near-perfect accuracy on the given application.
Kernel methods for center manifold approximation and a data-based version of the Center Manifold Theorem
Dec 01, 2020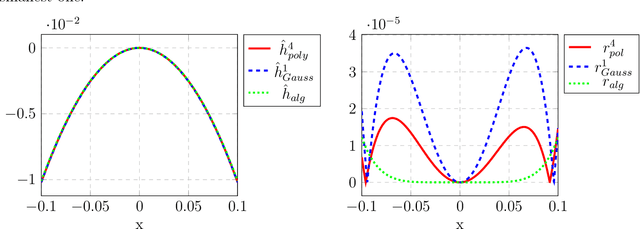
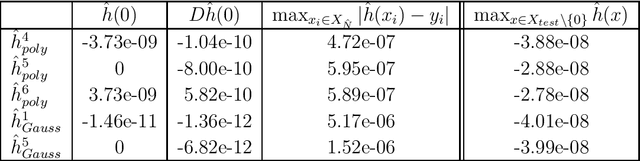

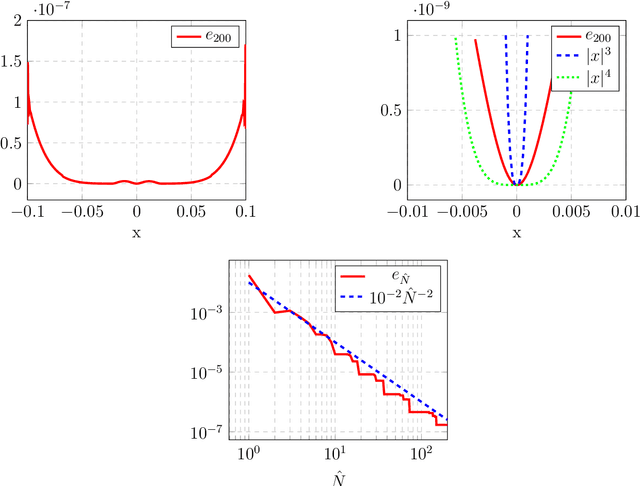
For dynamical systems with a non hyperbolic equilibrium, it is possible to significantly simplify the study of stability by means of the center manifold theory. This theory allows to isolate the complicated asymptotic behavior of the system close to the equilibrium point and to obtain meaningful predictions of its behavior by analyzing a reduced order system on the so-called center manifold. Since the center manifold is usually not known, good approximation methods are important as the center manifold theorem states that the stability properties of the origin of the reduced order system are the same as those of the origin of the full order system. In this work, we establish a data-based version of the center manifold theorem that works by considering an approximation in place of an exact manifold. Also the error between the approximated and the original reduced dynamics are quantified. We then use an apposite data-based kernel method to construct a suitable approximation of the manifold close to the equilibrium, which is compatible with our general error theory. The data are collected by repeated numerical simulation of the full system by means of a high-accuracy solver, which generates sets of discrete trajectories that are then used as a training set. The method is tested on different examples which show promising performance and good accuracy.
Biomechanical surrogate modelling using stabilized vectorial greedy kernel methods
Apr 28, 2020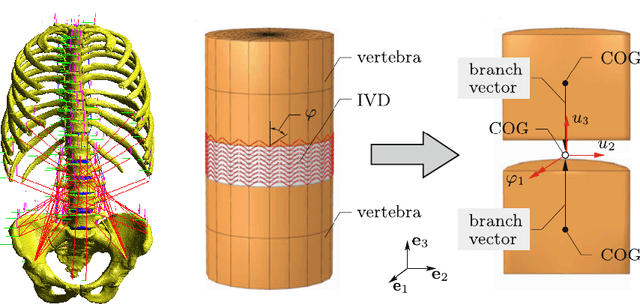


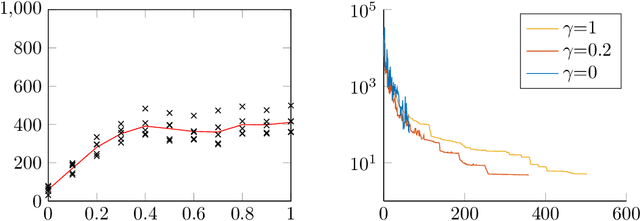
Greedy kernel approximation algorithms are successful techniques for sparse and accurate data-based modelling and function approximation. Based on a recent idea of stabilization of such algorithms in the scalar output case, we here consider the vectorial extension built on VKOGA. We introduce the so called $\gamma$-restricted VKOGA, comment on analytical properties and present numerical evaluation on data from a clinically relevant application, the modelling of the human spine. The experiments show that the new stabilized algorithms result in improved accuracy and stability over the non-stabilized algorithms.
Deep recurrent Gaussian process with variational Sparse Spectrum approximation
Sep 27, 2019
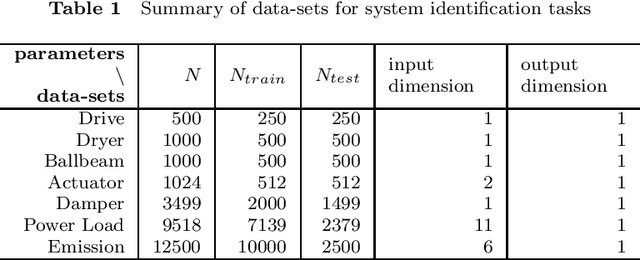
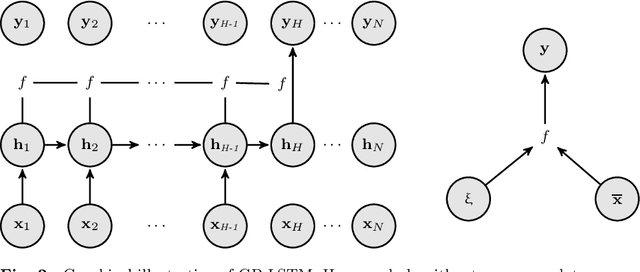

Modeling sequential data has become more and more important in practice. Some applications are autonomous driving, virtual sensors and weather forecasting. To model such systems, so called recurrent models are frequently used. In this paper we introduce several new Deep recurrent Gaussian process (DRGP) models based on the Sparse Spectrum Gaussian process (SSGP) and the improved version, called variational Sparse Spectrum Gaussian process (VSSGP). We follow the recurrent structure given by an existing DRGP based on a specific variational sparse Nystr\"om approximation, the recurrent Gaussian process (RGP). Similar to previous work, we also variationally integrate out the input-space and hence can propagate uncertainty through the Gaussian process (GP) layers. Our approach can deal with a larger class of covariance functions than the RGP, because its spectral nature allows variational integration in all stationary cases. Furthermore, we combine the (variational) Sparse Spectrum ((V)SS) approximations with a well known inducing-input regularization framework. We improve over current state of the art methods in prediction accuracy for experimental data-sets used for their evaluation and introduce a new data-set for engine control, named Emission.