 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLSSVM: A (multi-)GPGPU-accelerated Least Squares Support Vector Machine
Paper and Code
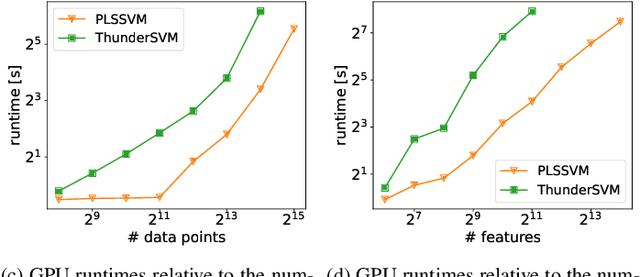
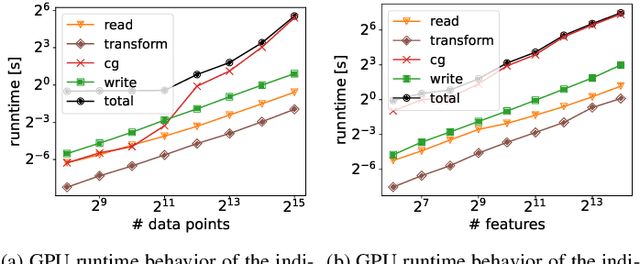
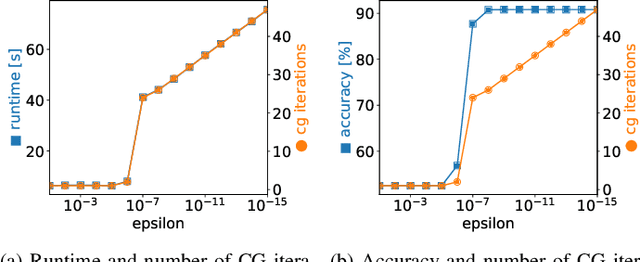
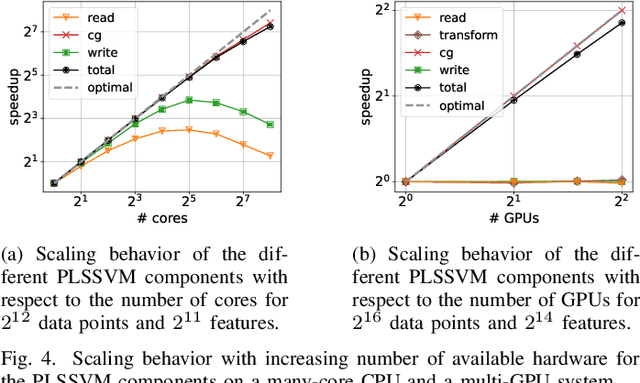
Machine learning algorithms must be able to efficiently cope with massive data sets. Therefore, they have to scale well on any modern system and be able to exploit the computing power of accelerators independent of their vendor. In the field of supervised learning, Support Vector Machines (SVMs) are widely used. However, even modern and optimized implementations such as LIBSVM or ThunderSVM do not scale well for large non-trivial dense data sets on cutting-edge hardware: Most SVM implementations are based on Sequential Minimal Optimization, an optimized though inherent sequential algorithm. Hence, they are not well-suited for highly parallel GPUs. Furthermore, we are not aware of a performance portable implementation that supports CPUs and GPUs from different vendors. We have developed the PLSSVM library to solve both issues. First, we resort to the formulation of the SVM as a least squares problem. Training an SVM then boils down to solving a system of linear equations for which highly parallel algorithms are known. Second, we provide a hardware independent yet efficient implementation: PLSSVM uses different interchangeable backends--OpenMP, CUDA, OpenCL, SYCL--supporting modern hardware from various vendors like NVIDIA, AMD, or Intel on multiple GPUs. PLSSVM can be used as a drop-in replacement for LIBSVM. We observe a speedup on CPUs of up to 10 compared to LIBSVM and on GPUs of up to 14 compared to ThunderSVM. Our implementation scales on many-core CPUs with a parallel speedup of 74.7 on up to 256 CPU threads and on multiple GPUs with a parallel speedup of 3.71 on four GPUs. The code, utility scripts, and documentation are all available on GitHub: https://github.com/SC-SGS/PLSSVM.