 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReqBrain: Task-Specific Instruction Tuning of LLMs for AI-Assisted Requirements Generation
May 23, 2025
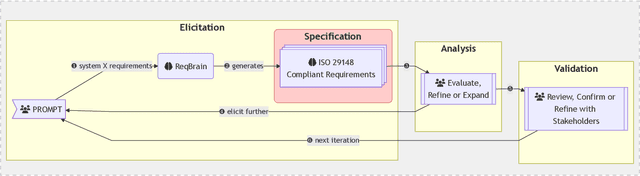


Requirements elicitation and specification remains a labor-intensive, manual process prone to inconsistencies and gaps, presenting a significant challenge in modern software engineering. Emerging studies underscore the potential of employing large language models (LLMs) for automated requirements generation to support requirements elicitation and specification; however, it remains unclear how to implement this effectively. In this work, we introduce ReqBrain, an Al-assisted tool that employs a fine-tuned LLM to generate authentic and adequate software requirements. Software engineers can engage with ReqBrain through chat-based sessions to automatically generate software requirements and categorize them by type. We curated a high-quality dataset of ISO 29148-compliant requirements and fine-tuned five 7B-parameter LLMs to determine the most effective base model for ReqBrain. The top-performing model, Zephyr-7b-beta, achieved 89.30\% Fl using the BERT score and a FRUGAL score of 91.20 in generating authentic and adequate requirements. Human evaluations further confirmed ReqBrain's effectiveness in generating requirements. Our findings suggest that generative Al, when fine-tuned, has the potential to improve requirements elicitation and specification, paving the way for future extensions into areas such as defect identification, test case generation, and agile user story creation.
Detecting Requirements Smells With Deep Learning: Experiences, Challenges and Future Work
Aug 06, 2021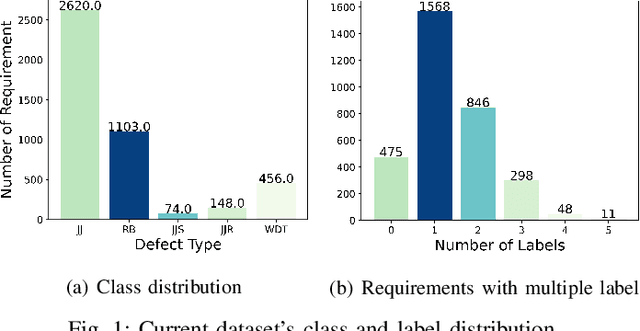
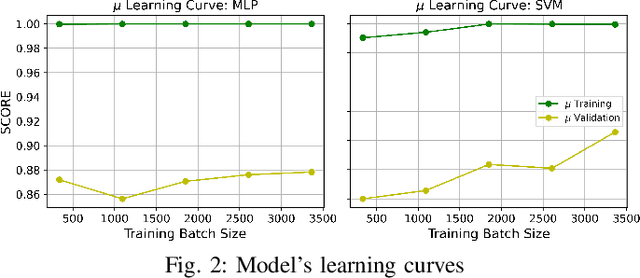
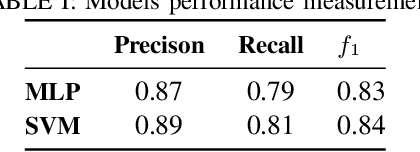
Requirements Engineering (RE) is the initial step towards building a software system. The success or failure of a software project is firmly tied to this phase, based on communication among stakeholders using natural language. The problem with natural language is that it can easily lead to different understandings if it is not expressed precisely by the stakeholders involved, which results in building a product different from the expected one. Previous work proposed to enhance the quality of the software requirements detecting language errors based on ISO 29148 requirements language criteria. The existing solutions apply classical Natural Language Processing (NLP) to detect them. NLP has some limitations, such as domain dependability which results in poor generalization capability. Therefore, this work aims to improve the previous work by creating a manually labeled dataset and using ensemble learning, Deep Learning (DL), and techniques such as word embeddings and transfer learning to overcome the generalization problem that is tied with classical NLP and improve precision and recall metrics using a manually labeled dataset. The current findings show that the dataset is unbalanced and which class examples should be added more. It is tempting to train algorithms even if the dataset is not considerably representative. Whence, the results show that models are overfitting; in Machine Learning this issue is solved by adding more instances to the dataset, improving label quality, removing noise, and reducing the learning algorithms complexity, which is planned for this research.
The Challenges of Persian User-generated Textual Content: A Machine Learning-Based Approach
Jan 20, 2021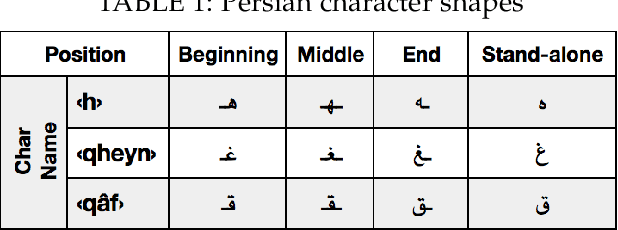
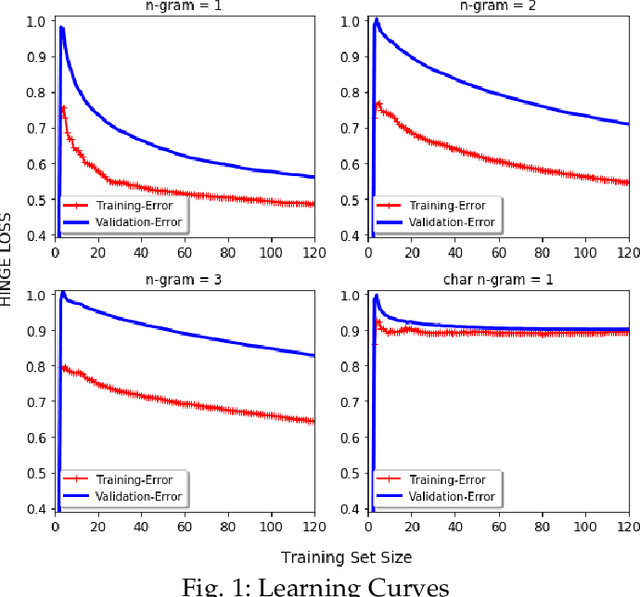
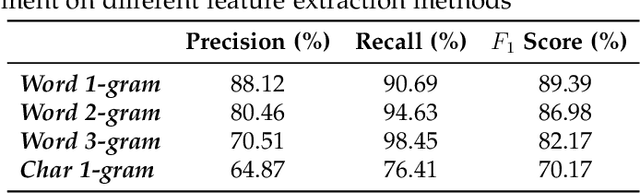
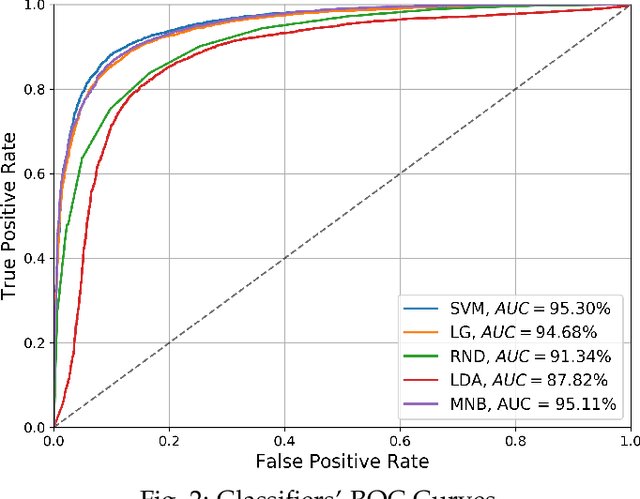
Over recent years a lot of research papers and studies have been published on the development of effective approaches that benefit from a large amount of user-generated content and build intelligent predictive models on top of them. This research applies machine learning-based approaches to tackle the hurdles that come with Persian user-generated textual content. Unfortunately, there is still inadequate research in exploiting machine learning approaches to classify/cluster Persian text. Further, analyzing Persian text suffers from a lack of resources; specifically from datasets and text manipulation tools. Since the syntax and semantics of the Persian language is different from English and other languages, the available resources from these languages are not instantly usable for Persian. In addition, recognition of nouns and pronouns, parts of speech tagging, finding words' boundary, stemming or character manipulations for Persian language are still unsolved issues that require further studying. Therefore, efforts have been made in this research to address some of the challenges. This presented approach uses a machine-translated datasets to conduct sentiment analysis for the Persian language. Finally, the dataset has been rehearsed with different classifiers and feature engineering approaches. The results of the experiments have shown promising state-of-the-art performance in contrast to the previous efforts; the best classifier was Support Vector Machines which achieved a precision of 91.22%, recall of 91.71%, and F1 score of 91.46%.